上一篇文章详细给大家介绍了标签的设计与加工,在标签生命周期流程中,标签体系设计完成后,便进入标签加工与上线运行阶段,一般来说数据开发团队会主导此过程,但我们需要关心以下几个问题:
·标签如何快速创建和实现标签逻辑的在线化管理
·业务人员怎么参与到标签建设流程中
·百万级别的标签如何落表
一、加工方式:传统VS在线
当企业无标签系统时,一般由数据开发在离线数仓中完成标签的加工和运行,运营或市场同学需要某个标签需要通过产品经理向数据开发提需求,这个过程存在很多问题:
· 标签资产不可见:标签是存在于表里的字段,业务人员不清楚现在有多少标签;标签的加工逻辑与业务逻辑是否一致只能查看SQL代码;新上线的标签只有部分人知道,标签价值散发慢等
· 标签资产不可管:加工好的标签,有多少在真正被使用,有多少没人用,完全黑盒,不用的标签每天继续运行浪费计算与存储资源
· 标签加工效率低:当业务人员需要某个简单标签时,也需要提交需求给数据开发,加工到上线基本需要2-3天流程
基于以上这些问题,标签的在线化创建与管理显得尤为重要,在线化主要包含以下内容:
· 标签在线化加工
· 标签在线化管理
· 标签在线化更新
其让标签加工过程以及有哪些标签变得透明,业务人员也可以参与进标签建设的流程中。
二、各类型标签加工
标签类型的区分在此处便不再赘述了。在袋鼠云智能标签产品——「客户数据洞察」中,我们按照标签加工逻辑,将标签分为以下类型,各类型标签的加工层次如下图:
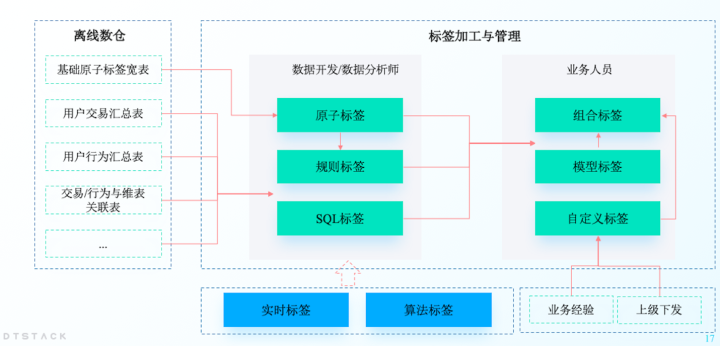 接下来,我们来看看具体各类型标签的加工。
接下来,我们来看看具体各类型标签的加工。
1、原子标签
该类标签由数据开发在数仓加工中完成,一般基于数仓DWD、DWS层的明细表与汇总表加工而来,处理逻辑较为复杂,同时维表中的一些字段也可以作为原子标签。这类标签一般包含哪些内容呢?
● 建立用户的标签体系:
用户维表中的用户基础属性:性别、年龄、置业、会员等级、手机号、身份证号等信息,一般用户系统会有该类信息。
● 基于交易表加工的交易指标
最近30天购买次数、最近30天交易金额、最近7天购买次数、最近7天交易金额。这部分标签也建议放在数仓中实现,有以下几点原因:
·因为其本身也是一个指标,除后续作为标签进行画像分析外,也常用于在数据门户、BI报表中分析,可作为对外服务的指标放在ADS层中,并且市场上也会有专门指标管理的产品,来实现该指标的加工
· 这类标签若属于同一个统计维度(如都计算最近7天),数据开发可以在一个SQL片段中计算多个标签,节约计算成本
· 若业务人员直接基于DWS层的轻度汇总表(每天汇总的交易次数、交易金额)、或DWD层的明细表(每条交易记录一行数据)来加工最近30天购买次数这个标签,需要针对对应的字段进行求和,稍微涉及到一点SQL理解,有一些难度
故该类使用场景多、对于业务人员有计算难度,可在数仓中合并加工降低成本的标签,可在数仓中作为原子标签加工。
● 基于行为表加工的行为指标
可经过数仓加工成如下表格式,加工行为类的标签,便于后续业务人员去衍生。
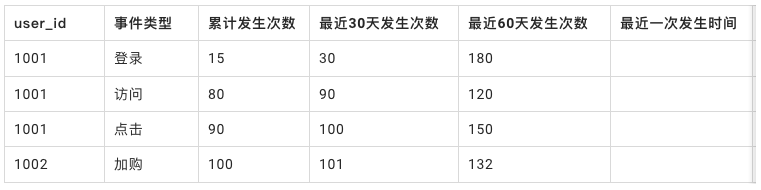 原子标签在数仓加工好后,可导入到标签系统中,进行在线化管理。
原子标签在数仓加工好后,可导入到标签系统中,进行在线化管理。
2、规则标签
该类标签配置可由数据开发或数据分析师来完成,可基于单张表或关联表中的字段进行在线化加工,可设置统计周期、数据过滤条件,其内置常用的聚合函数(求和、均值、计数、去重技术、最大值、最小值等)、操作符(大于、小于、区间、有值、无值、包含等),通过规则化的在线配置完成标签加工。配置界面如以下:
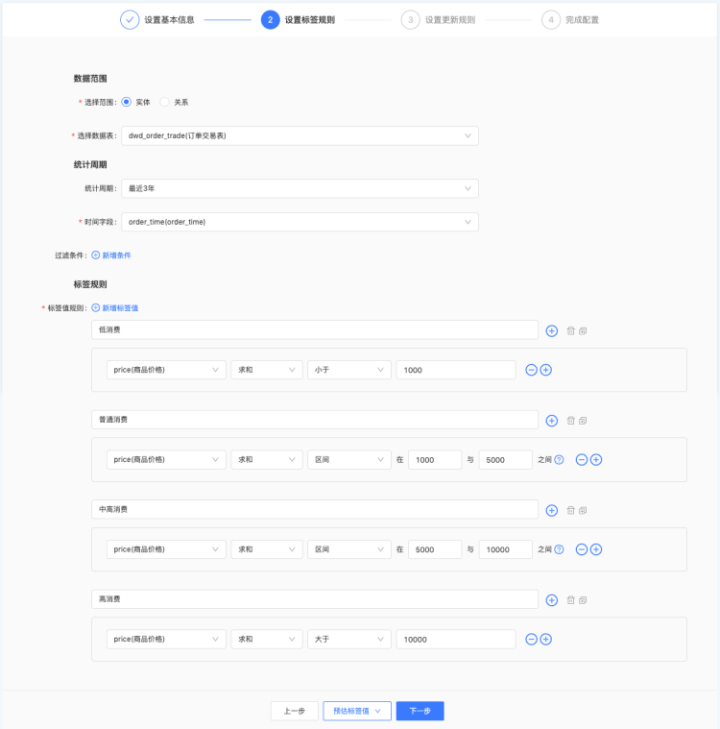
根据上面的描述,该类标签可以将指标的类型的标签在数仓或指标平台加工好,导入至标签平台作为原子标签,再基于这些原子标签取操作符更好。但在实际场景中,基于不同考虑,有的客户也会在标签平台直接加工此类型标签,如以下场景:
· 数仓无对应的基础标签,但业务人员很着急需要该标签某标签,走正常的排期、数仓加工、测试,上线到使用基本2天以上了,基于这种情况可以通过该类标签在标签系统直接配置,5分钟即可配置、更新完成,业务人员便可以使用了
· 客户方想把标签的加工逻辑在线化呈现、方便查找与追溯,通过可视化的方式在线配置
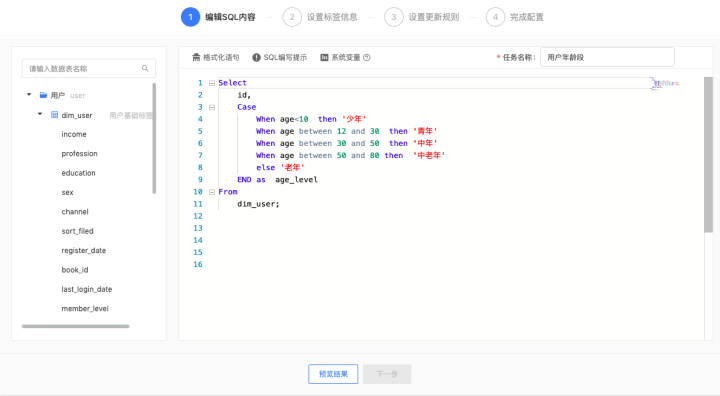
3、SQL标签
SQL标签主要由数据开发、数据分析师使用,主要解决通过规则标签无法表达的逻辑,如用到排序函数、字符转化函数、子查询等内容,可以通过标准SQL语法灵活完成标签加工。
4、模型标签
模型标签可由业务人员创建。系统集成常见的用户分层RFM模型,用户营销AIPL模型、用户生命周期模型,用户输入对应的指标值区间,便可定义对应的标签值。
以RFM模型举例,基于该模型生成“客户价值”标签。可基于最近一次购买时间、最近一年消费金额、最近一年消费频率等几个原子标签,进行不同区间的取值,给用户打上“重要价值客户”、“重要发展客户”、“重要发展客户”、“重要挽留客户”等。
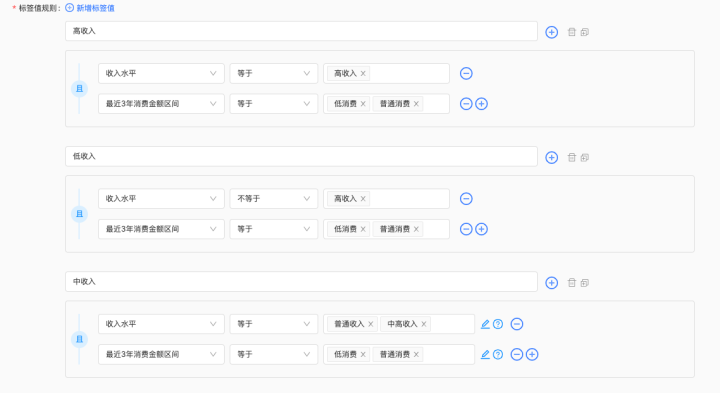
5、组合标签
模型标签可由业务人员创建。基于已生成的原子、规则、SQL、模型标签等,进行规则衍生,生成组合标签。如组合标签“高收入低购买”用户,可通过“收入水平”衍生标签,与“最近3年消费金额区间”衍生标签组合加工,如下图:
6、自定义标签
自定义标签可由业务人员创建。手动为某些用户打上标签,该类标签手动导入,常见场景如下:
· 客服人员和用户ID为1001的用户沟通后,给该用户打上”性格:温和、有耐心”标签
· 如监管机构提供的一些信贷黑名单用户,该类标签可直接导入进标签系统,为用户打上新的标签
7、算法标签
算法标签由算法开发同学创建,该类标签可在算法平台完成,将算好的结果存储至Hive表中,标签系统可获取算法标签的元数据,拿到算法标签的中文名、英文名,注册至标签系统中,在标签系统中完成算法标签的标签信息查看、标签查询等。
如利用机器学习模型加工预测类的算法标签,如根据用户的特征,预测哪些用户是否即将流失,流失的概率等,从而在用户流失之前做一些措施来挽留。
8、实时标签
实时标签由数据开发同学创建,该类标签可在流计算平台完成,实时行为数据打入到kafka中,用FlinkSQL消费,再输出到Kafka、或数据表中,下游直接订阅或查询。
三、标签更新与落库
标签配置完成后,便需要进行标签更新与落库,即将标签打到对象(如用户)的身上,这样业务同学就可以根据标签圈选目标群组啦。在此处我们需要说明以下几个问题:
1、技术选型
首先说明一下标签加工的技术选型,在袋鼠云智能标签产品「客户数据洞察」中我们用的 Trino(Presto)高性能分析引擎读写 Hive 表的方式,标签表存储在Hive中。主要有以下几点原因:
· 随着国家对数字化转型的支持,从金融、政府到小企业都在建设数仓,进行数字化应用,在这个过程中,大多采用的是分布式的Hadoop系统作为计算存储引擎(不论是开源Hadoop,还是发行版的CDH、TDH、FusionInsight等),Hive表便是最常用的存储形式。标签是基于数仓模型搭建出来的,与数仓用同一种存储可以节省存储资源以及不用两种存储之间进行数据交换
· 而用Trino(Presto)的原因是其首先是一个分析型引擎,读写速度均可;其次是其SQL语法完备、函数丰富、灵活,可以处理绝大多是业务场景的需求;并且支持跨库同时读取,如Trino可以同时取Hive与MySQL的数据进行数据处理
但没有一种完美的技术选型,只能贴合企业自己的业务,选取最合适的技术。在这里我们就不分析各种标签的技术选型了。
2、落表方式
上面我们介绍了有各种类型的标签,那么标签如何落表呢,大家看下面这个图:
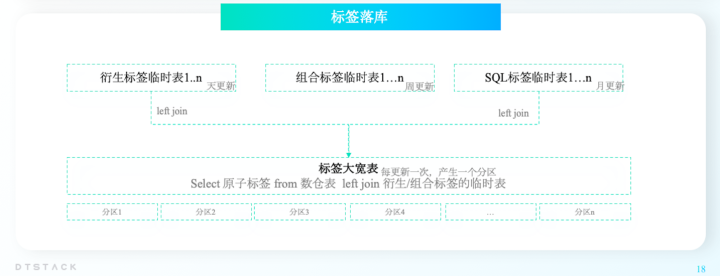 在业务场景中,存在有的标签需要每天更新,如最近30天消费金额区间;而有的标签周更新、月更新即可,更新频率不高,如活动类型偏好。
在业务场景中,存在有的标签需要每天更新,如最近30天消费金额区间;而有的标签周更新、月更新即可,更新频率不高,如活动类型偏好。
这样,便需要支持每个标签有不同的更新频率,但hive2.x版本不支持单列更新,为了解决该问题,我们将每个标签先在临时表存一下(就包含2列,1列用户ID,1列标签)该临时表即建即用即删,每个标签只有一个临时表(非分区表),每个标签占用的占用不大,又能解决标签更新周期不一致的问题。
但如果后续的标签圈群、群组画像分析,我们基于这些单独表的去做联合查询,那效率会很低。
因为每个用营销活动,我们需要5个标签圈选出来一批人群,并查询出这群人的性别、年龄、月消费、会员等级、是否活跃用户等信息,加起来用到了10个标签左右,会涉及到10个表的join操作,客户集群资源不丰裕的情况,查询速度慢。
所有我们便将多个临时表通过聚合任务,将所有的临时表join到一张标签大宽表中,进行固化,这张表是一个分区表,可以每天存储一份全量用户标签信息,当然可以自行设置该表的更新周期与保存多少个分区。
这样,业务人员进行圈群和分析就可以一张表查询数据,查询效率大大提升。通过标签跑批时间的消耗换取业务的查询速度。
但会遇到有些企业标签数量在500-1000个之间,用户量在千万、亿级别,这样的话,用一张表去存所有的标签会遇到标签大宽表跑批时间过长或跑不出来的情况,所以便需要分表,可以根据标签数量分表。
综上,以上加工存储方式,有缺点的地方便是大宽表加工时,需要join多个临时表,消耗内存,跑批时间长。
四、写在最后的话
为解决该问题,袋鼠云智能标签产品「客户数据洞察」在引入数据湖Iceberg进行标签表的存储,其可以实现单列更新,每个标签可以单独更新,这样,便不需要那些临时表了,解决加工效率的问题。
标签加工与落库是标签体系完成后重要的步骤,本篇文章向大家分享了标签加工与落库过程中需要关注的注意点,讲述了不同标签的加工内容以及标签的更新与落库等内容。
欢迎大家留言与我们讨论,也可以分享下自己见到的一些好的标签加工方式,我们共同进步。
最后
以上就是靓丽苗条最近收集整理的关于终于有人把不同标签的加工内容与落库讲明白了丨DTVision分析洞察篇一、加工方式:传统VS在线二、各类型标签加工三、标签更新与落库四、写在最后的话的全部内容,更多相关终于有人把不同标签内容请搜索靠谱客的其他文章。








发表评论 取消回复