这篇文章来自作者对Michael Stonebraker和Rick Cattell两位作者所著《10 Rules for scalable Performance in ‘simple operation’ Datastores 》 Communications of The ACM | June 2011 | VOL. 54 | No. 6 的翻译和理解,以飨读者,分为上、中、下三篇。 原文出自http://blog.csdn.net/hongchangfirst/article/details/7008836。
Ted Codd5在1970年提出了数据的关系模型(the relational model),这种模型解决了当时数据库管理系统(DBMS)的问题(商业上的数据处理)。最早的关系系统有System R2和Ingres9,今天的大多数商业化的关系数据库管理系统的实现的根源都可以追溯到这两个系统。
除非你比较有偏见,否则今天所有的主流商业制造商(Oracle,IBM和Microsoft)和主要的开源系统(MySQL和PostgreSQL)看起来是一样的。我们称这些系统为传统的通用行存储系统(general-purpose traditional row stores, GPTRS),这些系统都有以下特征:
- 面向磁盘的存储;
- 表是由一行一行的存储在磁盘上,即行存储;
- 以B树结构作为索引机制;
- 动态加锁作为并发控制机制;
- 预写日志用于系统恢复;
- SQL作为访问语言;
- 一个“面向行“的查询优化器和执行器,System R7是先驱者。
二十世纪七十年代到八十年代以一个主要的数据库管理系统市场(商业化的数据处理)为特征,今天称之为在线事务处理(online transaction processing, OLTP)。从那时起,数据库管理系统开始在各种各样的新市场使用,包括数据仓库,科研数据库,社交网站和游戏网站。现代数据库管理系统的特征见下图。
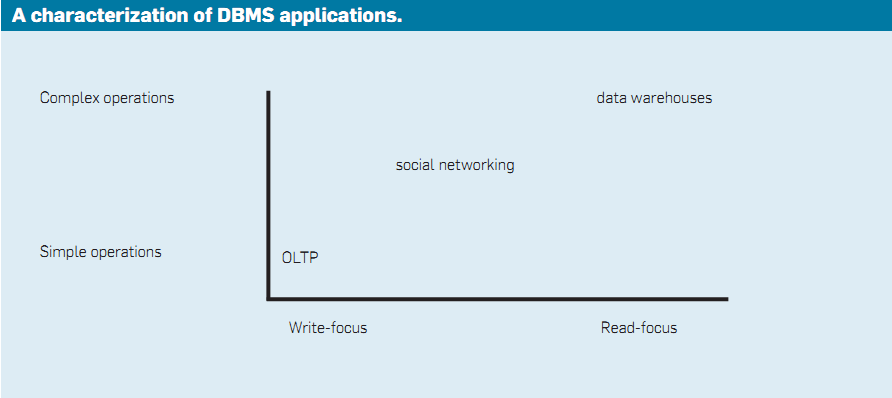
这张图包括两个轴,横轴表示一个应用是读密集型的还是写密集型的,纵轴说明一个应用是执行简单操作(读或者写一些项)还是复杂操作(读或者写成千上万项);例如,传统的在线事务处理(OLTP)市场是一种写密集型、执行简单操作的应用,而数据仓库市场是一种读密集性的、执行复杂操作的应用。当然,还有很多应用是基于两者之间的,比如社交网络应用大多数涉及简单操作并且有读也有写操作。因此,任何一种在这张图上显示的应用我们都应该在两个方向上连续统一的看待,而不应该是离散的。
大多数主要关系模型的商业化引擎和开源系统实现被制定为“一个大小适用于所有应用 ”(one-size-fits-all),也就是说,他们的系统声称对所有的应用(不管在图中的哪个位置)都是合适的。
然而,这种方式也有一些令人不满意的地方。比如,在数据仓库市场,列存储取得了商业上的成功.。在数据仓库领域,如果只有查询所需的列才会从磁盘中读取,那么就可以减少读取未使用数据的开销,提高系统性能。另外,这样还可以获得超强的压缩比和索引,因为在一个存储块上只有一种类型的对象,而不是几种类型的对象分布于多个存储块上。最后,主存带宽可以通过一种对压缩数据操作的查询执行器进行优化。正因为这些原因,列存储在典型的数据仓库工作方面比行存储显著的快,所以我们预期随着时间的推移列存储方式将主导者数据仓库市场。
这里我们对简单操作的应用进行分析,这种应用位于图中较低的位置。相当一部分新的、非传统的通用行存储系统(non-GPTRS)已经被设计出来,用来向数据仓库领域提供可扩展性。我们可以不严谨的把这些系统分为四类:
键值存储类型(Key-value stores)。这类系统有Dunamo,Voldemort,Membase,Membrain,Scalaris和Riak。这些系统有着最为简单的数据模型:一个存储对象的集合,每一个对象都有一个键(key)和一个有效载荷(payload),这种系统几乎没有能力去把(payload)作为一个多属性的对象来对待,因而没有对非主键属性查询机制的支持。
文档存储类型(Document stores)。这类系统有Couch-DB, MongoDB, SimpleDB和Ter-rastore,它们的数据模型包括了大量的对象,这种对象拥有可变长数量的属性,有些系统还允许对象之间的嵌套。这类系统通过(non-SQL)查询语言或者是过程式机制来对多个属性进行约束,从而搜索到对象集。
可扩展记录存储类型(Extensible record stores)。这类系统有BigTable, Cassandra, HBase, HyperTable 和PNUTS,它们提供了可变长的记录集,这些记录集可以通过多个节点在纵向和横向上进行划分。这些操作通常不是通过SQL来执行的。
SQL数据库管理系统类型(SQL DBMSs)。这类系统关注于应用的可扩展性,包括MySQL集群,其它MySQL衍生品,VoltDB,NimbusDB和Clustrix。这类系统保留了SQL和事务的ACID性质(原子性,一致性,隔离性和持久性),但是它们的实现方式非常不同于那些传统的通用行存储系统(GPTRS systems)。
尽管这种分类方式覆盖了主要的新系统类型,但是它可能并不精确和详尽。并且,市场正在快速的变化,读者应该查看其它最新的相关资料。如果想进一步了解这类系统完整的讨论和参照,可参考Cattell4和下边列出的表。
前三种类型的系统大大的驱动了NoSQL的发展,它们通过允许唯一的一条记录操作成为事务,或者通过对ACID的语义进行扩展,比如说,只支持对多版本数据的“事件一致性“来约束传统的事务ACID概念。
多种动机促进了这类系统的发展。一些因素是关系模型令人不满意或者关系型数据库管理系统的“重量级”。另一些因素是大规模Web服务的需求,这类Web资产通常伴随着一些最主要的问题。大型Web资产经常幸运地开始启动后经历了爆炸式的增长,这就是所谓的曲棍球效应。它们往往使用开源的数据库管理系统,因为它是免费的或者它已经被这类系统的开发者所理解。单节点的数据库管理系统解决方案也许成为第一个版本,这马上就引起了可扩展性问题。传统的解决方法是共享(shared),或者把应用的数据划分到多个节点上以平分负载。表可以用这种方式进行划分;例如,员工姓名可一个被划分到26个节点上,字母’A’打头的划分到节点1,依此类推。接下来要做的工作就是在应用逻辑层上改变每一条直接查询语句使其分配到每一个正确的节点上。但是,在应用逻辑层使用这样的划分(sharding)有一些缺点:
- 如果要执行交叉划分过滤或者是联接操作,都必须在应用层编写相应的代码;
- 如果在一个事务中对多个碎片进行更新,那么应用层就要保证在各个节点上数据的一致性;
- 随着系统规模的扩大节点失效会更加普遍。一个很困难的问题是在一个正在运行的系统中怎样维护副本数据的一致性,监测失效,副本的失效和节点间的替换失效;
- 另一个要解决的非常困难的问题是怎样使在改变关系模式的时候不会对那些碎片(shards)产生影响,以至于它们失效;
- 给新节点增加新设备或者改变配置是非常冗长乏味的,如果碎片不能被当作脱机的时(if the shards cannot be taken offline),这种操作也更加的困难。
许多这种碎片式的Web应用开发者们经受着巨大的痛苦,因为他们不得不在应用逻辑层执行这些功能;许多NoSQL的改动都是针对这一痛苦点的。然而,随着大量的新系统和这些系统提供方法的广泛应用,客户b可能在理解和选择一个能满足他们应用需求的系统时会有困难。
这里分别列出上中下三篇地址,方便读者进行阅读。上篇:http://blog.csdn.net/hongchangfirst/article/details/7008836中篇:http://blog.csdn.net/hongchangfirst/article/details/7008955下篇:http://blog.csdn.net/hongchangfirst/article/details/7022162
后面会提供给大家关于这篇论文的后续翻译与理解部分,敬请关注。
最后
以上就是苹果煎蛋最近收集整理的关于衡量易操作数据存储(SOD)可扩展性能的十大准则(上)的全部内容,更多相关衡量易操作数据存储(SOD)可扩展性能内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复