前段时间看到知乎上推了一篇文章https://zhuanlan.zhihu.com/p/33699909 ,上面是实现wider&&deep、deepfm、pnn之类的深度学习在ctr上的应用,模型原理都比较简单;数据来源于kaggle比赛的ctr模型,我具体没细看,这里我使用随机生成的数据做test,原githup博客代码全部用python2.7版本来写,切换到3有一些bug要稍微改一下,下面我放的代码就是用3写的,原来githup中预测用c++写的,我用java,其中我挑DeepFM算法重新搞了一下,其余算法大同小异,在java中调用的话,框架是用的tensorflow高阶接口estimator相关的,在这里我要先说明下,原来用这个接口保存为pb格式的模型文件要先保存为checkpoint的形式,废话不多说,直接看代码, java环境1.8,python环境3.6
首先是libsvm格式数据生成java代码,我用数字特征为5个,字符特征为3个,one-hot之后总计为39个特征:
package com.meituan.test;
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.Random;
public class LibSvmUtils {
public final static String TrainPATH = "click/train.txt";
public final static String TestPATH = "click/test.txt";
public final static String VAPATH = "click/va.txt";
public static void main(String[] args) throws IOException {
genatartelibsvm(TrainPATH, 20000);
genatartelibsvm(TestPATH, 2000);
genatartelibsvm(VAPATH, 200);
}
public static void genatartelibsvm(String trainpath, int count) throws IOException {
StringBuffer sb = null;
Random random = new Random();
BufferedWriter bf = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(trainpath)));
/**
*
* 总共field是8个,其中数值是5个,分类形状是3个,总估计特征39个
* **/
for (int i = 0; i < count; i++) {
sb = new StringBuffer();
int featureidx=1;
/**
* 产生label
* */
sb.append(random.nextInt(2)).append(" ");
/**
* 产生数字特征 5个
* */
for (int j = 0; j < 5; j++) {
sb.append(featureidx+":"+Math.random()).append(" ");
featureidx+=1;
}
/**
* 字符特征 5个, 此时featureidx等于6,从6开始算
* */
int featureidxa=featureidx;
sb.append(featureidxa+random.nextInt(18)+":1").append(" ");
/**
* 前面已经有23个,特征这一步从24算起,6+18
* */
int featureidxb=featureidx+18;
sb.append(featureidxb + random.nextInt(10)+":1").append(" ");
/**
* 前面已经有33个,特征这一步从34算起,总共估计39个特征
* */
int featureidxc=featureidx+18+10;
sb.append(featureidxc+ random.nextInt(5)+":1").append("n");
bf.write(sb.toString());
}
bf.close();
}
}tensorflow的模型代码:
"""
#1 Input pipline using Dataset high level API, Support parallel and prefetch reading
#2 Train pipline using Coustom Estimator by rewriting model_fn
#3 Support distincted training using TF_CONFIG
#4 Support export_model for TensorFlow Serving
方便迁移到其他算法上,只要修改input_fn and model_fn
by lambdaji
"""
#from __future__ import absolute_import
#from __future__ import division
#from __future__ import print_function
#import argparse
import shutil
#import sys
import os
import json
import glob
from datetime import date, timedelta
from time import time
#import gc
#from multiprocessing import Process
#import math
import random
import pandas as pd
import numpy as np
import tensorflow as tf
#################### CMD Arguments ####################
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_integer("dist_mode", 0, "distribuion mode {0-loacal, 1-single_dist, 2-multi_dist}")
tf.app.flags.DEFINE_string("ps_hosts", '', "Comma-separated list of hostname:port pairs")
tf.app.flags.DEFINE_string("worker_hosts", '', "Comma-separated list of hostname:port pairs")
tf.app.flags.DEFINE_string("job_name", '', "One of 'ps', 'worker'")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
tf.app.flags.DEFINE_integer("num_threads", 16, "Number of threads")
tf.app.flags.DEFINE_integer("feature_size", 0, "Number of features")
tf.app.flags.DEFINE_integer("field_size", 0, "Number of fields")
tf.app.flags.DEFINE_integer("embedding_size", 32, "Embedding size")
tf.app.flags.DEFINE_integer("num_epochs", 10, "Number of epochs")
tf.app.flags.DEFINE_integer("batch_size", 64, "Number of batch size")
tf.app.flags.DEFINE_integer("log_steps", 1000, "save summary every steps")
tf.app.flags.DEFINE_float("learning_rate", 0.0005, "learning rate")
tf.app.flags.DEFINE_float("l2_reg", 0.0001, "L2 regularization")
tf.app.flags.DEFINE_string("loss_type", 'log_loss', "loss type {square_loss, log_loss}")
tf.app.flags.DEFINE_string("optimizer", 'Adam', "optimizer type {Adam, Adagrad, GD, Momentum}")
tf.app.flags.DEFINE_string("deep_layers", '256,128,64', "deep layers")
tf.app.flags.DEFINE_string("dropout", '0.5,0.5,0.5', "dropout rate")
tf.app.flags.DEFINE_boolean("batch_norm", False, "perform batch normaization (True or False)")
tf.app.flags.DEFINE_float("batch_norm_decay", 0.9, "decay for the moving average(recommend trying decay=0.9)")
tf.app.flags.DEFINE_string("data_dir", '', "data dir")
tf.app.flags.DEFINE_string("dt_dir", '', "data dt partition")
tf.app.flags.DEFINE_string("model_dir", 'tensorflow/', "model check point dir")
tf.app.flags.DEFINE_string("servable_model_dir", 'servermodel/', "export servable model for TensorFlow Serving")
tf.app.flags.DEFINE_string("task_type", 'train', "task type {train, infer, eval, export}")
tf.app.flags.DEFINE_boolean("clear_existing_model", False, "clear existing model or not")
#1 1:0.5 2:0.03519 3:1 4:0.02567 7:0.03708 8:0.01705 9:0.06296 10:0.18185 11:0.02497 12:1 14:0.02565 15:0.03267 17:0.0247 18:0.03158 20:1 22:1 23:0.13169 24:0.02933 27:0.18159 31:0.0177 34:0.02888 38:1 51:1 63:1 132:1 164:1 236:1
def input_fn(filenames, batch_size=32, num_epochs=1, perform_shuffle=False):
print('Parsing', filenames)
def decode_libsvm(line):
#columns = tf.decode_csv(value, record_defaults=CSV_COLUMN_DEFAULTS)
#features = dict(zip(CSV_COLUMNS, columns))
#labels = features.pop(LABEL_COLUMN)
columns = tf.string_split([line], ' ')
labels = tf.string_to_number(columns.values[0], out_type=tf.float32)
splits = tf.string_split(columns.values[1:], ':')
id_vals = tf.reshape(splits.values,splits.dense_shape)
feat_ids, feat_vals = tf.split(id_vals,num_or_size_splits=2,axis=1)
feat_ids = tf.string_to_number(feat_ids, out_type=tf.int32)
feat_vals = tf.string_to_number(feat_vals, out_type=tf.float32)
return {"feat_ids": feat_ids, "feat_vals": feat_vals}, labels
dataset = tf.data.TextLineDataset(filenames).map(decode_libsvm, num_parallel_calls=10).prefetch(500000)
if perform_shuffle:
dataset = dataset.shuffle(buffer_size=256)
# epochs from blending together.
dataset = dataset.repeat(num_epochs)
dataset = dataset.batch(batch_size) # Batch size to use
iterator = dataset.make_one_shot_iterator()
batch_features, batch_labels = iterator.get_next()
#return tf.reshape(batch_ids,shape=[-1,field_size]), tf.reshape(batch_vals,shape=[-1,field_size]), batch_labels
return batch_features, batch_labels
def model_fn(features, labels, mode, params):
"""Bulid Model function f(x) for Estimator."""
#------hyperparameters----
field_size = params["field_size"]
feature_size = params["feature_size"]
embedding_size = params["embedding_size"]
l2_reg = params["l2_reg"]
learning_rate = params["learning_rate"]
#batch_norm_decay = params["batch_norm_decay"]
#optimizer = params["optimizer"]
layers = list(map(int, params["deep_layers"].split(',')))
dropout = list(map(float, params["dropout"].split(',')))
#------bulid weights------
FM_B = tf.get_variable(name='fm_bias', shape=[1], initializer=tf.constant_initializer(0.0))
FM_W = tf.get_variable(name='fm_w', shape=[feature_size], initializer=tf.glorot_normal_initializer())
FM_V = tf.get_variable(name='fm_v', shape=[feature_size, embedding_size], initializer=tf.glorot_normal_initializer())
#------build feaure-------
feat_ids = features['feat_ids']
feat_ids = tf.reshape(feat_ids,shape=[-1,field_size])
feat_vals = features['feat_vals']
feat_vals = tf.reshape(feat_vals,shape=[-1,field_size])
#------build f(x)------
with tf.variable_scope("First-order"):
feat_wgts = tf.nn.embedding_lookup(FM_W, feat_ids) # None * F * 1
y_w = tf.reduce_sum(tf.multiply(feat_wgts, feat_vals),1)
with tf.variable_scope("Second-order"):
embeddings = tf.nn.embedding_lookup(FM_V, feat_ids) # None * F * K
feat_vals = tf.reshape(feat_vals, shape=[-1, field_size, 1])
embeddings = tf.multiply(embeddings, feat_vals) #vij*xi
sum_square = tf.square(tf.reduce_sum(embeddings,1))
square_sum = tf.reduce_sum(tf.square(embeddings),1)
y_v = 0.5*tf.reduce_sum(tf.subtract(sum_square, square_sum),1) # None * 1
with tf.variable_scope("Deep-part"):
if FLAGS.batch_norm:
#normalizer_fn = tf.contrib.layers.batch_norm
#normalizer_fn = tf.layers.batch_normalization
if mode == tf.estimator.ModeKeys.TRAIN:
train_phase = True
#normalizer_params = {'decay': batch_norm_decay, 'center': True, 'scale': True, 'updates_collections': None, 'is_training': True, 'reuse': None}
else:
train_phase = False
#normalizer_params = {'decay': batch_norm_decay, 'center': True, 'scale': True, 'updates_collections': None, 'is_training': False, 'reuse': True}
else:
normalizer_fn = None
normalizer_params = None
deep_inputs = tf.reshape(embeddings,shape=[-1,field_size*embedding_size]) # None * (F*K)
for i in range(len(layers)):
#if FLAGS.batch_norm:
# deep_inputs = batch_norm_layer(deep_inputs, train_phase=train_phase, scope_bn='bn_%d' %i)
#normalizer_params.update({'scope': 'bn_%d' %i})
deep_inputs = tf.contrib.layers.fully_connected(inputs=deep_inputs, num_outputs=layers[i],
#normalizer_fn=normalizer_fn, normalizer_params=normalizer_params,
weights_regularizer=tf.contrib.layers.l2_regularizer(l2_reg), scope='mlp%d' % i)
if FLAGS.batch_norm:
deep_inputs = batch_norm_layer(deep_inputs, train_phase=train_phase, scope_bn='bn_%d' %i) #放在RELU之后 https://github.com/ducha-aiki/caffenet-benchmark/blob/master/batchnorm.md#bn----before-or-after-relu
if mode == tf.estimator.ModeKeys.TRAIN:
deep_inputs = tf.nn.dropout(deep_inputs, keep_prob=dropout[i]) #Apply Dropout after all BN layers and set dropout=0.8(drop_ratio=0.2)
#deep_inputs = tf.layers.dropout(inputs=deep_inputs, rate=dropout[i], training=mode == tf.estimator.ModeKeys.TRAIN)
y_deep = tf.contrib.layers.fully_connected(inputs=deep_inputs, num_outputs=1, activation_fn=tf.identity,
weights_regularizer=tf.contrib.layers.l2_regularizer(l2_reg), scope='deep_out')
y_d = tf.reshape(y_deep,shape=[-1])
with tf.variable_scope("DeepFM-out"):
y_bias = FM_B * tf.ones_like(y_d, dtype=tf.float32) # None * 1
y = y_bias + y_w + y_v + y_d
pred = tf.sigmoid(y)
predictions={"prob": pred}
export_outputs = {tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY: tf.estimator.export.PredictOutput(predictions)}
# Provide an estimator spec for `ModeKeys.PREDICT`
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(
mode=mode,
predictions=predictions,
export_outputs=export_outputs)
#------bulid loss------
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=y, labels=labels)) +
l2_reg * tf.nn.l2_loss(FM_W) +
l2_reg * tf.nn.l2_loss(FM_V) #+ l2_reg * tf.nn.l2_loss(sig_wgts)
# Provide an estimator spec for `ModeKeys.EVAL`
eval_metric_ops = {
"auc": tf.metrics.auc(labels, pred)
}
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(
mode=mode,
predictions=predictions,
loss=loss,
eval_metric_ops=eval_metric_ops)
#------bulid optimizer------
if FLAGS.optimizer == 'Adam':
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate, beta1=0.9, beta2=0.999, epsilon=1e-8)
elif FLAGS.optimizer == 'Adagrad':
optimizer = tf.train.AdagradOptimizer(learning_rate=learning_rate, initial_accumulator_value=1e-8)
elif FLAGS.optimizer == 'Momentum':
optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate, momentum=0.95)
elif FLAGS.optimizer == 'ftrl':
optimizer = tf.train.FtrlOptimizer(learning_rate)
train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())
# Provide an estimator spec for `ModeKeys.TRAIN` modes
if mode == tf.estimator.ModeKeys.TRAIN:
return tf.estimator.EstimatorSpec(
mode=mode,
predictions=predictions,
loss=loss,
train_op=train_op)
def batch_norm_layer(x, train_phase, scope_bn):
bn_train = tf.contrib.layers.batch_norm(x, decay=FLAGS.batch_norm_decay, center=True, scale=True, updates_collections=None, is_training=True, reuse=None, scope=scope_bn)
bn_infer = tf.contrib.layers.batch_norm(x, decay=FLAGS.batch_norm_decay, center=True, scale=True, updates_collections=None, is_training=False, reuse=True, scope=scope_bn)
z = tf.cond(tf.cast(train_phase, tf.bool), lambda: bn_train, lambda: bn_infer)
return z
def set_dist_env():
if FLAGS.dist_mode == 1: # 本地分布式测试模式1 chief, 1 ps, 1 evaluator
ps_hosts = FLAGS.ps_hosts.split(',')
chief_hosts = FLAGS.chief_hosts.split(',')
task_index = FLAGS.task_index
job_name = FLAGS.job_name
print('ps_host', ps_hosts)
print('chief_hosts', chief_hosts)
print('job_name', job_name)
print('task_index', str(task_index))
# 无worker参数
tf_config = {
'cluster': {'chief': chief_hosts, 'ps': ps_hosts},
'task': {'type': job_name, 'index': task_index }
}
print(json.dumps(tf_config))
os.environ['TF_CONFIG'] = json.dumps(tf_config)
elif FLAGS.dist_mode == 2: # 集群分布式模式
ps_hosts = FLAGS.ps_hosts.split(',')
worker_hosts = FLAGS.worker_hosts.split(',')
chief_hosts = worker_hosts[0:1] # get first worker as chief
worker_hosts = worker_hosts[2:] # the rest as worker
task_index = FLAGS.task_index
job_name = FLAGS.job_name
print('ps_host', ps_hosts)
print('worker_host', worker_hosts)
print('chief_hosts', chief_hosts)
print('job_name', job_name)
print('task_index', str(task_index))
# use #worker=0 as chief
if job_name == "worker" and task_index == 0:
job_name = "chief"
# use #worker=1 as evaluator
if job_name == "worker" and task_index == 1:
job_name = 'evaluator'
task_index = 0
# the others as worker
if job_name == "worker" and task_index > 1:
task_index -= 2
tf_config = {
'cluster': {'chief': chief_hosts, 'worker': worker_hosts, 'ps': ps_hosts},
'task': {'type': job_name, 'index': task_index }
}
print(json.dumps(tf_config))
os.environ['TF_CONFIG'] = json.dumps(tf_config)
def main(_):
#tr_files = glob.glob("%s/tr*libsvm" % FLAGS.data_dir)
tr_files = FLAGS.data_dir+"train.txt"
#random.shuffle(tr_files)
print("tr_files:", tr_files)
#va_files = glob.glob("%s/va*libsvm" % FLAGS.data_dir)
va_files = FLAGS.data_dir + "va.txt"
print("va_files:", va_files)
#te_files = glob.glob("%s/te*libsvm" % FLAGS.data_dir)
te_files = FLAGS.data_dir + "test.txt"
print("te_files:", te_files)
if FLAGS.clear_existing_model:
try:
shutil.rmtree(FLAGS.model_dir)
except Exception as e:
print(e, "at clear_existing_model")
else:
print("existing model cleaned at %s" % FLAGS.model_dir)
set_dist_env()
model_params = {
"field_size": FLAGS.field_size,
"feature_size": FLAGS.feature_size,
"embedding_size": FLAGS.embedding_size,
"learning_rate": FLAGS.learning_rate,
"batch_norm_decay": FLAGS.batch_norm_decay,
"l2_reg": FLAGS.l2_reg,
"deep_layers": FLAGS.deep_layers,
"dropout": FLAGS.dropout
}
config = tf.estimator.RunConfig().replace(session_config = tf.ConfigProto(device_count={'GPU':0, 'CPU':FLAGS.num_threads}),
log_step_count_steps=FLAGS.log_steps, save_summary_steps=FLAGS.log_steps)
DeepFM = tf.estimator.Estimator(model_fn=model_fn, model_dir=FLAGS.model_dir, params=model_params, config=config)
if FLAGS.task_type == 'train':
train_spec = tf.estimator.TrainSpec(input_fn=lambda: input_fn(tr_files, num_epochs=FLAGS.num_epochs, batch_size=FLAGS.batch_size))
eval_spec = tf.estimator.EvalSpec(input_fn=lambda: input_fn(va_files, num_epochs=1, batch_size=FLAGS.batch_size), steps=None, start_delay_secs=1000, throttle_secs=1200)
tf.estimator.train_and_evaluate(DeepFM, train_spec, eval_spec)
elif FLAGS.task_type == 'eval':
DeepFM.evaluate(input_fn=lambda: input_fn(va_files, num_epochs=1, batch_size=FLAGS.batch_size))
elif FLAGS.task_type == 'infer':
preds = DeepFM.predict(input_fn=lambda: input_fn(te_files, num_epochs=1, batch_size=FLAGS.batch_size), predict_keys="prob")
with open(FLAGS.data_dir+"/pred.txt", "w") as fo:
for prob in preds:
fo.write("%fn" % (prob['prob']))
elif FLAGS.task_type == 'export':
#feature_spec = tf.feature_column.make_parse_example_spec(feature_columns)
#feature_spec = {
# 'feat_ids': tf.FixedLenFeature(dtype=tf.int64, shape=[None, FLAGS.field_size]),
# 'feat_vals': tf.FixedLenFeature(dtype=tf.float32, shape=[None, FLAGS.field_size])
#}
#serving_input_receiver_fn = tf.estimator.export.build_parsing_serving_input_receiver_fn(feature_spec)
feature_spec = {
'feat_ids': tf.placeholder(dtype=tf.int64, shape=[None, FLAGS.field_size], name='feat_ids'),
'feat_vals': tf.placeholder(dtype=tf.float32, shape=[None, FLAGS.field_size], name='feat_vals')
}
serving_input_receiver_fn = tf.estimator.export.build_raw_serving_input_receiver_fn(feature_spec)
DeepFM.export_savedmodel(FLAGS.servable_model_dir, serving_input_receiver_fn)
if __name__ == "__main__":
#------check Arguments------
if FLAGS.dt_dir == "":
FLAGS.dt_dir = (date.today() + timedelta(-1)).strftime('%Y%m%d')
FLAGS.model_dir = FLAGS.model_dir + FLAGS.dt_dir
#FLAGS.data_dir = FLAGS.data_dir + FLAGS.dt_dir
print('task_type ', FLAGS.task_type)
print('model_dir ', FLAGS.model_dir)
print('data_dir ', FLAGS.data_dir)
print('dt_dir ', FLAGS.dt_dir)
print('num_epochs ', FLAGS.num_epochs)
print('feature_size ', FLAGS.feature_size)
print('field_size ', FLAGS.field_size)
print('embedding_size ', FLAGS.embedding_size)
print('batch_size ', FLAGS.batch_size)
print('deep_layers ', FLAGS.deep_layers)
print('dropout ', FLAGS.dropout)
print('loss_type ', FLAGS.loss_type)
print('optimizer ', FLAGS.optimizer)
print('learning_rate ', FLAGS.learning_rate)
print('batch_norm_decay ', FLAGS.batch_norm_decay)
print('batch_norm ', FLAGS.batch_norm)
print('l2_reg ', FLAGS.l2_reg)
tf.logging.set_verbosity(tf.logging.INFO)
tf.app.run()模型训练以及保存为pb格式代码,训练过程会先checkpoint,然后再保存:
python3 DeepFM.py --task_type=train --learning_rate=0.0005 --optimizer=Adam --num_epochs=1 --batch_size=256 --field_size=8 --feature_size=39 --deep_layers=400,400,400 --dropout=0.5,0.5,0.5 --log_steps=1000 --num_threads=8 --model_dir=tensorflow/ --data_dir=data/python3 DeepFM.py --task_type=export --learning_rate=0.0005 --optimizer=Adam --batch_size=256 --field_size=8 --feature_size=39 --deep_layers=400,400,400 --dropout=0.5,0.5,0.5 --log_steps=1000 --num_threads=8 --model_dir=tensorflow/ --servable_model_dir=servermodel/tensorflow-serving命令:
bazel-bin/tensorflow_serving/model_servers/tensorflow_model_server --port=9000 --model_base_path=/Users/shuubiasahi/Desktop/modelserving
java中调请求serving返回结果:
package org.ranksys.javafm.example;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.tensorflow.framework.DataType;
import org.tensorflow.framework.TensorProto;
import org.tensorflow.framework.TensorShapeProto;
import io.grpc.ManagedChannel;
import io.grpc.ManagedChannelBuilder;
import tensorflow.serving.Model;
import tensorflow.serving.Predict;
import tensorflow.serving.PredictionServiceGrpc;
public class DeepFMPrediction {
public static void main(String[] args) {
List<Integer> ids_vec = Arrays.asList(1, 2, 3, 4, 5, 13, 31, 38);
List<Float> vals_vec = Arrays.asList(0.076f, 0.796f, 0.4707f, 0.21f,
0.83f, 1.0f, 1.0f, 1.0f);
ManagedChannel channel = ManagedChannelBuilder
.forAddress("0.0.0.0", 9000).usePlaintext(true).build();
// 这里还是先用block模式
PredictionServiceGrpc.PredictionServiceBlockingStub stub = PredictionServiceGrpc
.newBlockingStub(channel);
// 创建请求
Predict.PredictRequest.Builder predictRequestBuilder = Predict.PredictRequest
.newBuilder();
// 模型名称和模型方法名预设
Model.ModelSpec.Builder modelSpecBuilder = Model.ModelSpec.newBuilder();
modelSpecBuilder.setName("default");
modelSpecBuilder.setSignatureName("");
predictRequestBuilder.setModelSpec(modelSpecBuilder);
TensorShapeProto.Builder tensorShapeBuilder = TensorShapeProto.newBuilder();
tensorShapeBuilder.addDim(TensorShapeProto.Dim.newBuilder().setSize(1));
tensorShapeBuilder.addDim(TensorShapeProto.Dim.newBuilder().setSize(8));
// 设置入参1
TensorProto.Builder tensorids_ids = TensorProto.newBuilder();
tensorids_ids.setDtype(DataType.DT_INT64);
tensorids_ids.setTensorShape(tensorShapeBuilder.build());
tensorids_ids.addAllIntVal(ids_vec);
// 设置入参2
TensorProto.Builder tensorids_val = TensorProto.newBuilder();
tensorids_val.setDtype(DataType.DT_FLOAT);
tensorids_val.setTensorShape(tensorShapeBuilder.build());
tensorids_val.addAllFloatVal(vals_vec);
Map<String, TensorProto> map=new HashMap<String, TensorProto>();
map.put("feat_ids", tensorids_ids.build());
map.put("feat_vals", tensorids_val.build());
predictRequestBuilder.putAllInputs(map);
Predict.PredictResponse predictResponse = stub.predict(predictRequestBuilder.build());
System.out.println(predictResponse);
}
}
结果:
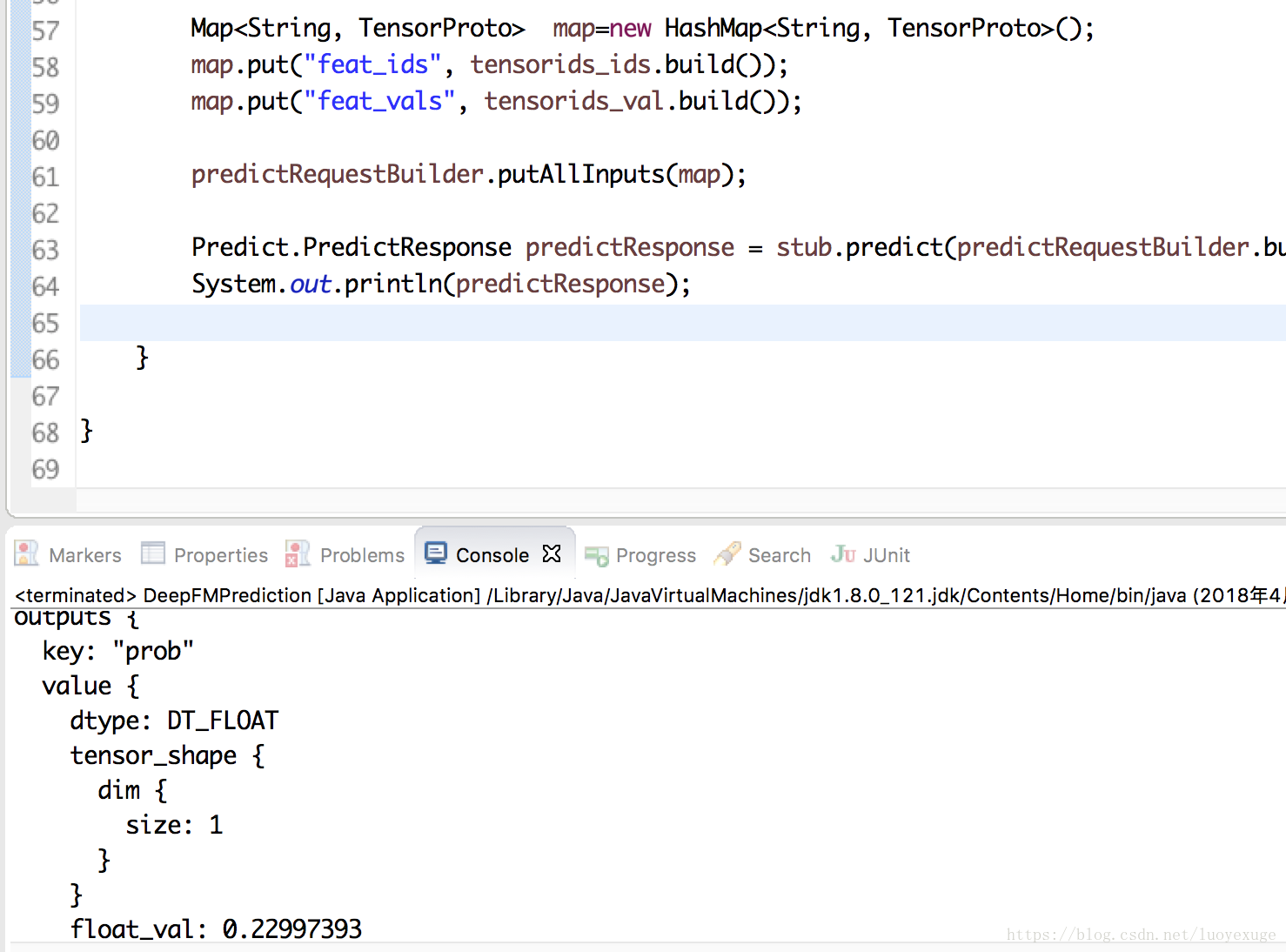
上述步骤有不懂可以随时联系我
最后
以上就是追寻战斗机最近收集整理的关于tensorfow实现DeepFM,模型保存、部署并java请求调用(ctr预测)的全部内容,更多相关tensorfow实现DeepFM内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复