一:简介
OCR(Optical Character Recognition):光学字符识别,是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,后由Google进行改进、修改bug、优化,重新发布。
二:语言字库
书接上回,咱们先放字库地址:
1、Windows版本Tesseract各版本下载 ,https://github.com/tesseract-ocr/tesseract/wiki/Data-Files
2、懒得思考的人呐,直接来这里下载:https://tesseract-ocr.github.io/tessdoc/Data-Files
3、再放一个地址GIthub,直接来这里下载:https://github.com/tesseract-ocr/tessdata再访问不了,那我也没办法了
链接:https://pan.baidu.com/s/1zolP6jiQFP1pABT8z9zh5Q
提取码:cxjt
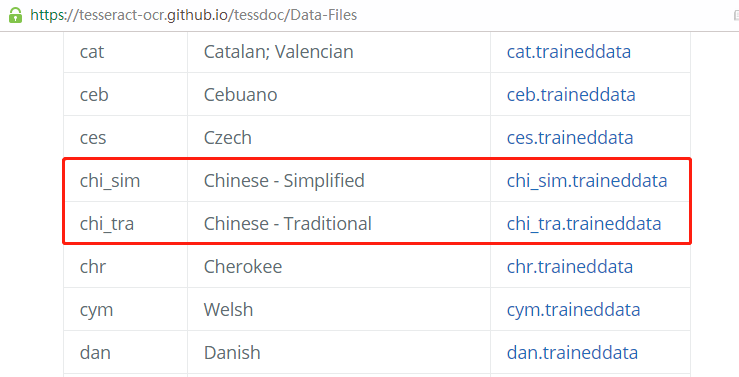
各版本对应字库要识别简体中文需要下载chi_sim.traindata字库(【注意】根据版本下载对应字库)。
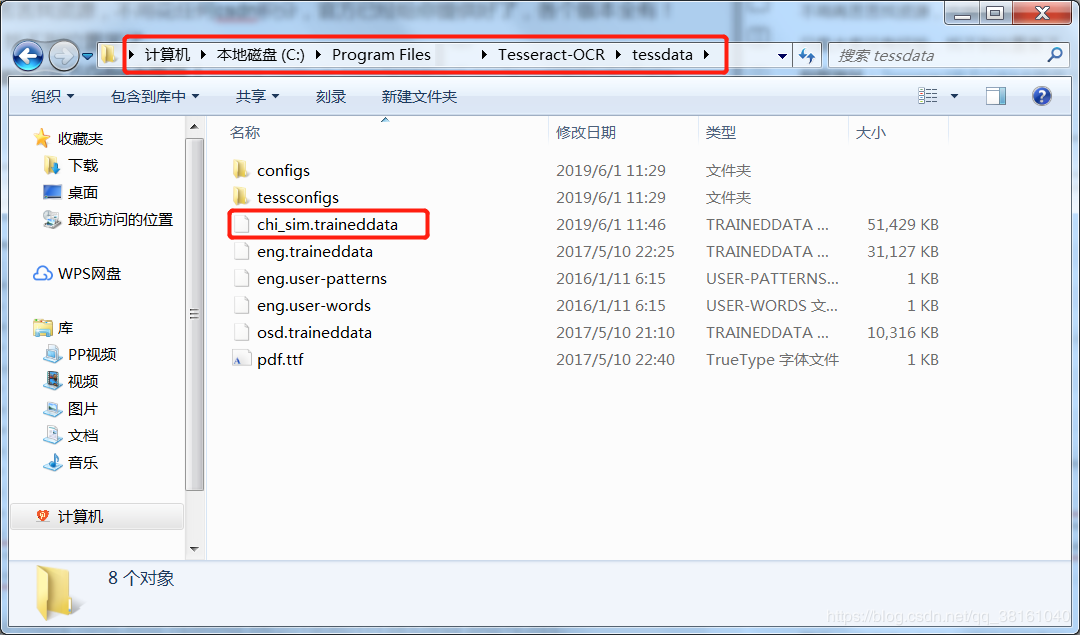
下载简体中文后放入你的字体库:
我的是:C:Program FilesTesseract-OCRtessdata
三:拿个图片来比划比划

执行命令如下:tesseract books.jpg result -l chi_sim
解释器:
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
1、执行过程:

2、执行结果:
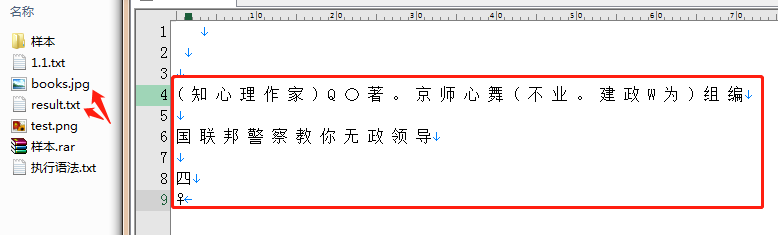
随机拍摄的照片,识别效果不怎么样。标准化的图片应该会很好
四:遇到的问题处理
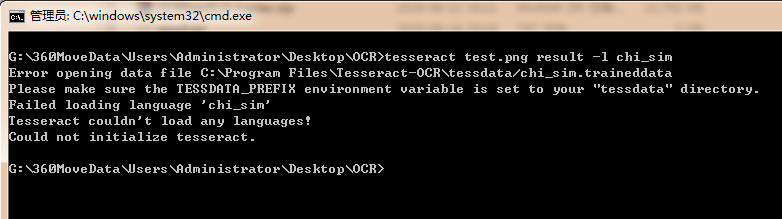
语言库里面的简体中文有问题,解决办法就是
用命令:【tesseract --list-langs】来查看Tesseract-OCR支持语言,如果没有则自行添加对应库。
看到确实是简体中文的语言不存在,所以不能支持了。
正确情况如下:

最后
以上就是娇气鼠标最近收集整理的关于Tesseract5.0 图像识别本地服务 二 【字库、训练识别模型】的全部内容,更多相关Tesseract5.0内容请搜索靠谱客的其他文章。








发表评论 取消回复