
大众点评的美食评论是大家平时选择吃饭地点的一种参考,通过他人品尝的经验来进行选择。今天就来爬一下大众点评吧~
观察网页
我们首先打开大众点评,进入美食板块,观察每家店的评论所在位置。
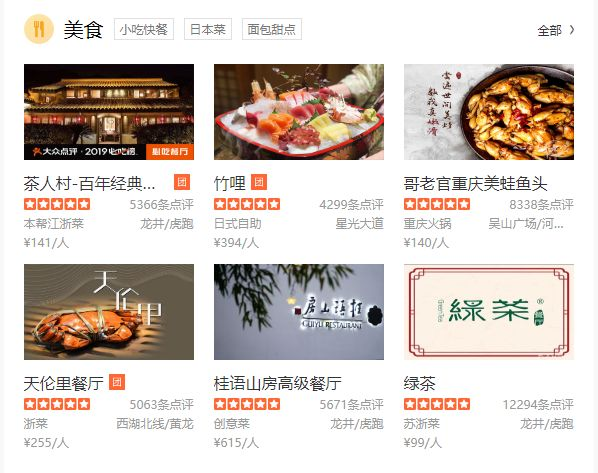
接着打开“茶人村”,发现这家店的具体信息显示为小方块,和之前所述的字体反爬网站相同。

找到其所属的字体类型,反爬字体1:
font-family: 'PingFangSC-Regular-address'
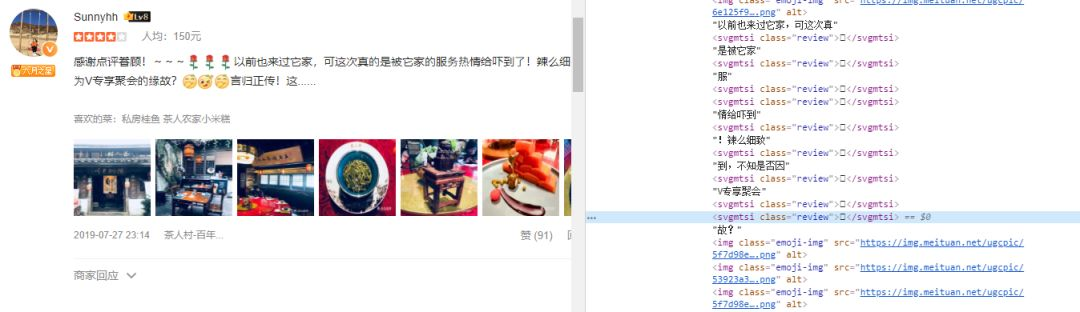
找到其所属的字体类型,反爬字体2:
font-family: 'PingFangSC-Regular-review'

找到其所属的字体类型,反爬字体3:
font-family: 'PingFangSC-Regular-num'
接着去网页源代码中寻找对应的字体文件,点击其CSS文件即可找到。也可以通过链接访问字体文件对应地址。

该CSS文件中果然有多个字体文件,分别对应不同的字体类型,先手动下载下来以作观察。
观察字体文件
用FontCreator打开下载下来的字体文件,发现其包含的字体内容相同,只是编码不同。这里的反爬和之前一篇文章字体反爬之猫眼电影相同,只是包含的字体多了。

另外还有一处不同就是所包含的字体文件不只一个,但是每个字体文件包含的字体种类相同,仅仅是编码不同。一种简单的想法就是遍历这些字体文件,将整个网页源代码的(字体反爬部分)转换成对应的字体。还有一种办法就是选择下载对应的woff文件,只对该部分字体反反爬。比如说我只需要爬取评论部分,而评论部分都是由review类型的字体文件编码的,我们就只需要下载相应的字体文件即可(包含在font-family: 'PingFangSC-Regular-review'之中)。
代码实现
利用正则表达式从CSS文件中提取所有的woff字体文件。
def get_woffs(text):
woffs=[]
urls=re.findall(r'url("//(.*?)")', text)
for url in urls:
if url not in woffs and '.woff' in url:
woffs.append(url)
return woffs
利用字体文件的比对,将获取的源代码的字体编码替换成对应字体,获取解密后的网页源代码。
def decrypt_font(url,headers,response):
'''
输入:链接和头部信息
输出:返回解决字体反爬后的页面源码
'''
font1=TTFont('a.woff')
base_font=['1', '2', '3', '4', '5', '6', '7', '8', '9', '0', '店', '中', '美', '家', '馆', '小', '车', '大', '市', '公', '酒', '行', '国', '品', '发', '电', '金', '心', '业', '商', '司', '超', '生', '装', '园', '场', '食', '有', '新', '限', '天', '面', '工', '服', '海', '华', '水', '房', '饰', '城', '乐', '汽', '香', '部', '利', '子', '老', '艺', '花', '专', '东', '肉', '菜', '学', '福', '饭', '人', '百', '餐', '茶', '务', '通', '味', '所', '山', '区', '门', '药', '银', '农', '龙', '停', '尚', '安', '广', '鑫', '一', '容', '动', '南', '具', '源', '兴', '鲜', '记', '时', '机', '烤', '文', '康', '信', '果', '阳', '理', '锅', '宝', '达', '地', '儿', '衣', '特', '产', '西', '批', '坊', '州', '牛', '佳', '化', '五', '米', '修', '爱', '北', '养', '卖', '建', '材', '三', '会', '鸡', '室', '红', '站', '德', '王', '光', '名', '丽', '油', '院', '堂', '烧', '江', '社', '合', '星', '货', '型', '村', '自', '科', '快', '便', '日', '民', '营', '和', '活', '童', '明', '器', '烟', '育', '宾', '精', '屋', '经', '居', '庄', '石', '顺', '林', '尔', '县', '手', '厅', '销', '用', '好', '客', '火', '雅', '盛', '体', '旅', '之', '鞋', '辣', '作', '粉', '包', '楼', '校', '鱼', '平', '彩', '上', '吧', '保', '永', '万', '物', '教', '吃', '设', '医', '正', '造', '丰', '健', '点', '汤', '网', '庆', '技', '斯', '洗', '料', '配', '汇', '木', '缘', '加', '麻', '联', '卫', '川', '泰', '色', '世', '方', '寓', '风', '幼', '羊', '烫', '来', '高', '厂', '兰', '阿', '贝', '皮', '全', '女', '拉', '成', '云', '维', '贸', '道', '术', '运', '都', '口', '博', '河', '瑞', '宏', '京', '际', '路', '祥', '青', '镇', '厨', '培', '力', '惠', '连', '马', '鸿', '钢', '训', '影', '甲', '助', '窗', '布', '富', '牌', '头', '四', '多', '妆', '吉', '苑', '沙', '恒', '隆', '春', '干', '饼', '氏', '里', '二', '管', '诚', '制', '售', '嘉', '长', '轩', '杂', '副', '清', '计', '黄', '讯', '太', '鸭', '号', '街', '交', '与', '叉', '附', '近', '层', '旁', '对', '巷', '栋', '环', '省', '桥', '湖', '段', '乡', '厦', '府', '铺', '内', '侧', '元', '购', '前', '幢', '滨', '处', '向', '座', '下', '県', '凤', '港', '开', '关', '景', '泉', '塘', '放', '昌', '线', '湾', '政', '步', '宁', '解', '白', '田', '町', '溪', '十', '八', '古', '双', '胜', '本', '单', '同', '九', '迎', '第', '台', '玉', '锦', '底', '后', '七', '斜', '期', '武', '岭', '松', '角', '纪', '朝', '峰', '六', '振', '珠', '局', '岗', '洲', '横', '边', '济', '井', '办', '汉', '代', '临', '弄', '团', '外', '塔', '杨', '铁', '浦', '字', '年', '岛', '陵', '原', '梅', '进', '荣', '友', '虹', '央', '桂', '沿', '事', '津', '凯', '莲', '丁', '秀', '柳', '集', '紫', '旗', '张', '谷', '的', '是', '不', '了', '很', '还', '个', '也', '这', '我', '就', '在', '以', '可', '到', '错', '没', '去', '过', '感', '次', '要', '比', '觉', '看', '得', '说', '常', '真', '们', '但', '最', '喜', '哈', '么', '别', '位', '能', '较', '境', '非', '为', '欢', '然', '他', '挺', '着', '价', '那', '意', '种', '想', '出', '员', '两', '推', '做', '排', '实', '分', '间', '甜', '度', '起', '满', '给', '热', '完', '格', '荐', '喝', '等', '其', '再', '几', '只', '现', '朋', '候', '样', '直', '而', '买', '于', '般', '豆', '量', '选', '奶', '打', '每', '评', '少', '算', '又', '因', '情', '找', '些', '份', '置', '适', '什', '蛋', '师', '气', '你', '姐', '棒', '试', '总', '定', '啊', '足', '级', '整', '带', '虾', '如', '态', '且', '尝', '主', '话', '强', '当', '更', '板', '知', '己', '无', '酸', '让', '入', '啦', '式', '笑', '赞', '片', '酱', '差', '像', '提', '队', '走', '嫩', '才', '刚', '午', '接', '重', '串', '回', '晚', '微', '周', '值', '费', '性', '桌', '拍', '跟', '块', '调', '糕']
base_uniname=font1['cmap'].tables[0].ttFont.getGlyphOrder()[2:]
# 使用百度的FontEditor找到本地字体文件name和数字之间的对应关系, 保存到字典中
base_dict=dict(zip(base_uniname,base_font))
name_list1=font1.getGlyphNames()[1:-1]
text=requests.get(url,headers=headers).text
# 正则匹配字体woff文件
font_files=get_woffs(text)
for i in range(len(font_files)):
new_file=requests.get('http://'+font_files[i],headers)
with open(font_files[i][-13:],'wb') as f:
f.write(new_file.content)
font2=TTFont(font_files[i][-13:])
# font2.saveXML('font_{}.xml'.format(i))
name_list2=font2.getGlyphNames()[1:-1]
# 构造新映射
new_dict={}
for name2 in name_list2:
obj2=font2['glyf'][name2]
for name1 in name_list1:
obj1=font1['glyf'][name1]
# 对象相等则说明对应的数字相同
if obj1==obj2:
new_dict[name2]=base_dict[name1]
for i in name_list2:
pattern='&#x'+i[3:].lower()+';'
response=re.sub(pattern,new_dict[i],response)
return response
最后
以上就是殷勤皮卡丘最近收集整理的关于字体反爬之大众点评的全部内容,更多相关字体反爬之大众点评内容请搜索靠谱客的其他文章。








发表评论 取消回复