(待修订版)
除去本地常见python第三方库之外,还需要安装这么些陌生的库:
- yaml:yaml是一种存储模型参数的文件,其中最常见的就是神经网络中的各种超参数
-
yacs:yacs是读取yaml文件的库,通过yacs.config中定义的CfgNode类加载参数。这个库能够很好地重用和拼接超参数文件配置。
-
fvcore:在fvocre中,fvcore.common.config同样定义了读取yaml文件的方法(本质上是yacs库中CfgNode类的拓展),用法同样为使用CfgNode类。fvcore是一个轻量级的核心库,它提供了在各种计算机视觉框架(如Detectron2)中共享的最常见和最基本的功能。
准备环境
- Linux or macOS with Python ≥ 3.6
- PyTorch ≥ 1.4 and torchvision that matches the PyTorch installation. You can install them together at pytorch.org to make sure of this
- OpenCV is optional and needed by demo and visualization
安装torch对应的版本:pip37 install torch==1.4.0 torchvision==0.5.0 -i http://mirrors.aliyun.com/pypi/simple
# Or, to install it from a local clone:
git clone https://github.com/facebookresearch/detectron2.git
python -m pip install -e detectron2demo实现测试

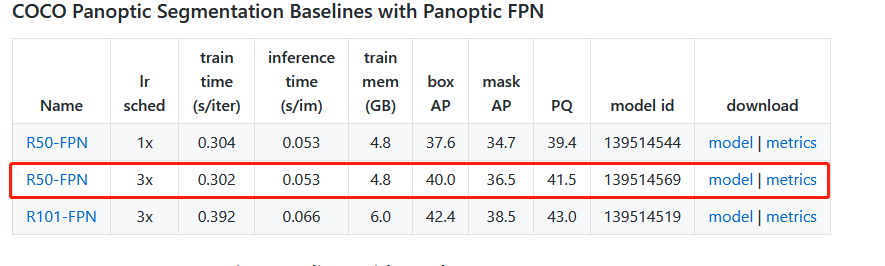
python37 demo/demo.py --config-file configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_3x.yaml --input images/001.jpg --output results --opts MODEL.WEIGHTS models/model_final_c10459.pkl
这里面有几个参数:
- configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_3x.yaml
这个是配置信息,detectron2那个文件夹里面已经有了 - input images/001.jpg
这个是要测试的路径,自己安排就可以了 - --output results
自己定义一个输出路径results - opts MODEL.WEIGHTS models/model_final_c10459.pkl
这是训练好的模型,根据自己的要求去model zoom 下载就可以了
model_final_c10459.pkl下载位置:detectron2/MODEL_ZOO.md at main · facebookresearch/detectron2 · GitHub
results文件夹预测结果:

detectron2-->config-->defaults.py配置参数介绍:
detectron2(目标检测框架)无死角玩转-03:配置config解析-实时更新_江南才尽,年少无知!的博客-CSDN博客_detectron2配置文件解析
# detectron2.detectron2.config.defaults.py
CUDNN_BENCHMARK: False #设置为True,其为自动找到效率最高的配置
DATALOADER: #dataloader的配置(数据迭代器)
ASPECT_RATIO_GROUPING: True # ?
FILTER_EMPTY_ANNOTATIONS: True # 是否过滤掉注释为空的数据
NUM_WORKERS: 4 # 加载数据的线程数目
REPEAT_THRESHOLD: 0.0 # 重新开始迭代是,从0加载数据
SAMPLER_TRAIN: TrainingSampler # 迭代训练样本
DATASETS: #数据集相关的配置
# 迭代数据时,提前准备1000/2000样本,为加快数据加载速度
PRECOMPUTED_PROPOSAL_TOPK_TEST: 1000
PRECOMPUTED_PROPOSAL_TOPK_TRAIN: 2000
# 数据集的文件名
PROPOSAL_FILES_TEST: ()
PROPOSAL_FILES_TRAIN: ()
# 获取数据时,其默认数据集名称
TEST: ('coco_2017_val',)
TRAIN: ('coco_2017_train',)
GLOBAL:
HACK: 1.0
INPUT: # 输入的相关的配置
CROP: # 图片剪切功能
ENABLED: False # 是否开启图片剪切
SIZE: [0.9, 0.9] # 剪切图像的大小比例
TYPE: relative_range # 剪切的方式
FORMAT: BGR # 图片的形式
MASK_FORMAT: polygon #mask掩码的格式,如果图片大小不足,会补黑色像素
MAX_SIZE_TEST: 1333 #测试图片的最大尺寸
MAX_SIZE_TRAIN: 1333 #训练图片的最大尺寸
MIN_SIZE_TEST: 800 # 测试图片最小尺寸
MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800) # 训练图片的最小尺寸
MIN_SIZE_TRAIN_SAMPLING: choice #训练尺寸的选取方式,choice或range
MODEL:
ANCHOR_GENERATOR: # anchor生成的相关配置
ANGLES: [[-90, 0, 90]] # anchor的角度
ASPECT_RATIOS: [[0.5, 1.0, 2.0]] # 长宽的比例
NAME: DefaultAnchorGenerator # anchor生成器的名字
OFFSET: 0.0 # 偏移量
SIZES: [[32], [64], [128], [256], [512]] # 大小,生成anchor每个尺寸的大小
BACKBONE: # 主干网络配置
FREEZE_AT: 2 #冻结?
NAME: build_resnet_fpn_backbone #主干网络的名字
DEVICE: cuda # 使用GPU
FPN: # FPN的相关配置
FUSE_TYPE: sum # 融合方式
IN_FEATURES: ['res2', 'res3', 'res4', 'res5'] # 指定处为输入特征
NORM: # ?
OUT_CHANNELS: 256 # FPN的输出通道数
KEYPOINT_ON: False # 是否开启关键点
LOAD_PROPOSALS: False # ?
MASK_ON: True # ?
META_ARCHITECTURE: GeneralizedRCNN # 微元素的架构,可以是retina等等
PANOPTIC_FPN: # 全景分割的相关配置
COMBINE: #相关绑定
ENABLED: True # 是否启动
INSTANCES_CONFIDENCE_THRESH: 0.5 # 设置置信度的阈值
OVERLAP_THRESH: 0.5 # 重叠部分的
STUFF_AREA_LIMIT: 4096 #?
INSTANCE_LOSS_WEIGHT: 1.0 # 实例的权重比例
PIXEL_MEAN: [103.53, 116.28, 123.675] # 归一化均值
PIXEL_STD: [1.0, 1.0, 1.0] #归一化的方差
PROPOSAL_GENERATOR: #?
MIN_SIZE: 0 #?
NAME: RPN #?
RESNETS: # 残差结构
DEFORM_MODULATED: False #
DEFORM_NUM_GROUPS: 1
DEFORM_ON_PER_STAGE: [False, False, False, False]
DEPTH: 50 # resnet50
NORM: FrozenBN # 冻结BN
NUM_GROUPS: 1 #输出特征的层数
OUT_FEATURES: ['res2', 'res3', 'res4', 'res5']
RES2_OUT_CHANNELS: 256 # 对应层输出的通道数
RES5_DILATION: 1 # ?
STEM_OUT_CHANNELS: 64
STRIDE_IN_1X1: True # ?
WIDTH_PER_GROUP: 64 # 可分离卷积的分组数目
RETINANET: # retinanet相关配置
BBOX_REG_WEIGHTS: (1.0, 1.0, 1.0, 1.0) # BBOX回归在,x,y,w,h的权重
FOCAL_LOSS_ALPHA: 0.25 # FOCAL_LOSS相关参数
FOCAL_LOSS_GAMMA: 2.0 # FOCAL_LOSS相关参数
IN_FEATURES: ['p3', 'p4', 'p5', 'p6', 'p7'] # 输入特征层
IOU_LABELS: [0, -1, 1] # 输出标签
IOU_THRESHOLDS: [0.4, 0.5] # IOU的阈值
NMS_THRESH_TEST: 0.5 # NMS的阈值
NUM_CLASSES: 80 # 训练数据的总类别数目
NUM_CONVS: 4 # 卷积层数目
PRIOR_PROB: 0.01 #?
SCORE_THRESH_TEST: 0.05 # 测试数据的置信度阈值
SMOOTH_L1_LOSS_BETA: 0.1 # L1loss平滑参数
TOPK_CANDIDATES_TEST: 1000 # 提前拿取的测试数据
ROI_BOX_CASCADE_HEAD: # CASCADE 级联相关参数
BBOX_REG_WEIGHTS: ((10.0, 10.0, 5.0, 5.0), (20.0, 20.0, 10.0, 10.0), (30.0, 30.0, 15.0, 15.0))
IOUS: (0.5, 0.6, 0.7)
ROI_BOX_HEAD:
BBOX_REG_WEIGHTS: (10.0, 10.0, 5.0, 5.0)
CLS_AGNOSTIC_BBOX_REG: False
CONV_DIM: 256
FC_DIM: 1024
NAME: FastRCNNConvFCHead
NORM:
NUM_CONV: 0
NUM_FC: 2
POOLER_RESOLUTION: 7
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
SMOOTH_L1_BETA: 0.0
ROI_HEADS:
BATCH_SIZE_PER_IMAGE: 512
IN_FEATURES: ['p2', 'p3', 'p4', 'p5']
IOU_LABELS: [0, 1]
IOU_THRESHOLDS: [0.5]
NAME: StandardROIHeads
NMS_THRESH_TEST: 0.5
NUM_CLASSES: 80
POSITIVE_FRACTION: 0.25
PROPOSAL_APPEND_GT: True
SCORE_THRESH_TEST: 0.05
ROI_KEYPOINT_HEAD:
CONV_DIMS: (512, 512, 512, 512, 512, 512, 512, 512)
LOSS_WEIGHT: 1.0
MIN_KEYPOINTS_PER_IMAGE: 1
NAME: KRCNNConvDeconvUpsampleHead
NORMALIZE_LOSS_BY_VISIBLE_KEYPOINTS: True
NUM_KEYPOINTS: 17
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
ROI_MASK_HEAD:
CLS_AGNOSTIC_MASK: False
CONV_DIM: 256
NAME: MaskRCNNConvUpsampleHead
NORM:
NUM_CONV: 4
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
RPN:
BATCH_SIZE_PER_IMAGE: 256
BBOX_REG_WEIGHTS: (1.0, 1.0, 1.0, 1.0)
BOUNDARY_THRESH: -1
HEAD_NAME: StandardRPNHead
IN_FEATURES: ['p2', 'p3', 'p4', 'p5', 'p6']
IOU_LABELS: [0, -1, 1]
IOU_THRESHOLDS: [0.3, 0.7]
LOSS_WEIGHT: 1.0
NMS_THRESH: 0.7
POSITIVE_FRACTION: 0.5
POST_NMS_TOPK_TEST: 1000
POST_NMS_TOPK_TRAIN: 1000
PRE_NMS_TOPK_TEST: 1000
PRE_NMS_TOPK_TRAIN: 2000
SMOOTH_L1_BETA: 0.0
SEM_SEG_HEAD:
COMMON_STRIDE: 4
CONVS_DIM: 128
IGNORE_VALUE: 255
IN_FEATURES: ['p2', 'p3', 'p4', 'p5']
LOSS_WEIGHT: 1.0
NAME: SemSegFPNHead
NORM: GN
NUM_CLASSES: 54 #类别的数目
WEIGHTS: detectron2://ImageNetPretrained/MSRA/R-50.pkl # 加载的权重
OUTPUT_DIR: ./output # 训练模型存储的位置
SEED: -1
SOLVER: #解决方案
BASE_LR: 0.0025 # 初始学习率
BIAS_LR_FACTOR: 1.0 #?
CHECKPOINT_PERIOD: 5000 # 没 5000个epoch保存一次模型
GAMMA: 0.1
IMS_PER_BATCH: 2 # batch_siez大小
LR_SCHEDULER_NAME: WarmupMultiStepLR # 学习率衰减方式,阶梯型和余弦型
MAX_ITER: 90000 # 到达该迭代次数则停止
MOMENTUM: 0.9 # 优化器动能
STEPS: (60000, 80000) # 到达指定迭代步数,则学习率衰减
WARMUP_FACTOR: 0.001
WARMUP_ITERS: 1000 # 学习率预热的迭代布数
WARMUP_METHOD: linear # 学习率预热增长方式
WEIGHT_DECAY: 0.0001 # 权重衰减
WEIGHT_DECAY_BIAS: 0.0001 # 权重衰减系数
WEIGHT_DECAY_NORM: 0.0
TEST: # 测试相关配置
AUG: # AUG相关配置
ENABLED: False
FLIP: True # 水平翻转
MAX_SIZE: 4000 # 图片的最大尺寸
MIN_SIZES: (400, 500, 600, 700, 800, 900, 1000, 1100, 1200) # 图片的最小尺寸
DETECTIONS_PER_IMAGE: 100 # 每张图片检测到的最大目标数目
EVAL_PERIOD: 0 # 迭代多少次后运行一次evaluator,评估模型,0为训练结束进行评估
EXPECTED_RESULTS: [] # 期待的结果
KEYPOINT_OKS_SIGMAS: [] #?
PRECISE_BN: # 测试精确度,BN的配置
ENABLED: False # 时候启动BN
NUM_ITER: 200 # 迭代数目
VERSION: 2
VIS_PERIOD: 0
文件注释
detectron2/data/datasets/builtin.py 包含所有数据集结构
detectron2/data/datasets/builtin_meta.py 包含每个数据集元数据
detectron2/data/transforms/transform_gen.py 包含基本的数据增强
detectron2/config/defaults.py 包含所有模型参数NMS
参考文章:目标检测中NMS和mAP指标中的的IoU阈值和置信度阈值_梦坠凡尘的博客-CSDN博客_iou阈值
模型预测会输出很多框,比如同一个目标会有很多框对应,NMS的作用是删除重复框,保留置信度分数最大的框。
在NMS算法中有一个置信度阈值c和IoU阈值u,简单回顾NMS算法如下:
对于一个预测框集合B(B中包含很多个预测框和它们对应的score)
- 找出B中score分数最高的M
- 将M从B中删除
- 将删除的M添加进最后的集合D
- 将B中所有的box与M进行IoU计算,删除B中 IoU > u的所有对应box
重复上面的步骤
最后D中的框就是保留下来的,留下的框中,删除掉低于score阈值的框,剩下的就是最终的预测框。
所以,这里的置信度阈值c是过滤掉预测框中置信度分数低于c的box;IoU阈值指的是拿出score分数最高框的其余框与score分数最高框的一个IoU比较。
注意到上面的NMS流程并没有对box的score做排序的过程。其实还有其它实现方式:
- 先对B中所有的box的score做排序,
- 拿出score最高的box(这里当做M,从大到小排序就是首个box)放在别的list D,
- 然后用B中其余的box分别与M计算IoU,去掉IoU > u 的box
- 重复上面步骤。
一样的,利用置信度阈值c对D中的box在做一次过滤,剩下的就是最后输出的。
对于利用置信度阈值c过滤,可以在没开始NMS前就做过滤,也可以在NMS后做过滤,这个不影响,看代码怎么实现。
以人脸检测为例,通常的流程为3步:NMS—卷积神经网络 - 理想几岁 - 博客园
(1)通过滑动窗口或者其它的object proposals方法产生大量的候选窗口;
(2)用训练好的分类器对候选窗口进行分类,该过程可以看做是一个打分的过程;
(3)使用NMS对上面的检测结果进行融合(因为一个目标可能被检测出多个窗口,而我们只希望保留一个)。
如下图是(2)分类检测之后的结果: 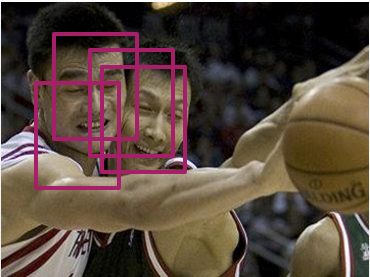
以此图为例,传统的NMS,首先选定一个IOU阈值,例如为0.25。然后将所有4个窗口(bounding box)按照得分由高到低排序。然后选中得分最高的窗口,遍历计算剩余的3个窗口与该窗口的重叠面积比例(IOU),如果IOU大于阈值0.25,则将窗口删除。然后,再从剩余的窗口中选中一个得分最高的,重复上述过程。直至所有窗口都被处理。
假如0.25是一个不错的阈值,那么我们可以得到比较好的结果,如下图:
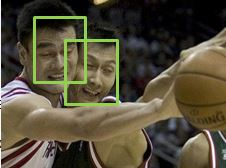
如果,我们的IOU阈值设定的特别小,比如说0.1。那么2个人的窗口会被归为一个人而被融合。得到下面的错误结果:

如果,我们的IOU阈值设定的特别大,比如说0.6。那么又可能得到下面的错误结果: 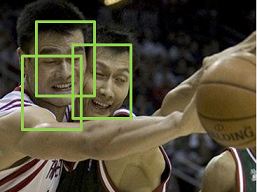
由上可知,对于传统的NMS算法选择一个好的阈值是多么重要的一件事,但又是一件很困难的事。传统的NMS是一种硬判决,是一种贪心算法。因此在文章中,作者称传统的NMS算法为:GreedyNMS
参考文章
Detectron2 测试用例 demo 代码注释:Detectron2 测试用例 demo 代码注释_黑山白雪m的博客-CSDN博客
Detectron2安装测试 (踩坑篇):Detectron2安装测试 (踩坑篇)_GrowthDiary007的博客-CSDN博客
手把手教你深度学习目标检测框架 detectron2 环境搭建:手把手教你深度学习目标检测框架 detectron2 环境搭建 - 云+社区 - 腾讯云
实战参考:
-
detectron2(目标检测框架)无死角玩转-04:训练自己的数据:https://blog.csdn.net/weixin_43013761/article/details/104032429 (重写配置文件,避免了散落到各地的繁琐配置,方便,首选)
- Detectron2训练自己的实例分割数据集:https://www.jianshu.com/p/a94b1629f827
-
Detectron2 尝鲜 -- 训练一个红绿灯检测模型:Detectron2 尝鲜 -- 训练一个红绿灯检测模型 - 知乎
-
detectron2:使用tools/train_net.py脚本命令行参数训练自己coco格式的数据集:https://www.freesion.com/article/4470383875/ (实验,报类别错误,未继续)
-
【detectron】训练自己的数据集:https://www.it610.com/article/1282150777380421632.htm (coco格式下,数据的准备和类别的修改)
-
detectron2训练自己的数据集:https://blog.csdn.net/sophia_xw/article/details/102954932 (讲述了数据放置结构,类别、训练配置参数的修改)
-
detectron2(目标检测框架)无死角玩转-04:训练自己的数据:https://blog.csdn.net/weixin_43013761/article/details/104032429 (强烈推荐)
-
https://blog.csdn.net/weixin_39916966/article/details/103299051(完整的训练和测试代码,参考推荐)
最后
以上就是稳重茉莉最近收集整理的关于Facebook detectron2学习记录准备环境detectron2-->config-->defaults.py配置参数介绍:NMS参考文章的全部内容,更多相关Facebook内容请搜索靠谱客的其他文章。








发表评论 取消回复