2019独角兽企业重金招聘Python工程师标准>>> 
针对“互联网+”时代的业务增长、变化速度及大规模计算的需求,廉价的、高可扩展的分布式x86集群已成为标准解决方案,如Google已经在几千万台服务器上部署分布式系统。Docker及其相关技术的出现和发展,又给大规模集群管理带来了新的想象空间。如何将二者进行有效地结合?本文将介绍数人科技基于Mesos和Docker的分布式计算平台的实践。
分布式系统设计准则
可伸缩性
首先分布式系统一定是大规模的系统,有很好的Scalability。出于成本的考虑,很多大规模的分布式系统一般采用廉价的PC服务器,而不是大型的高性能服务器。
没有单点失效
廉价的PC服务器在大规模使用中经常会遇到各种各样的问题,PC服务器的硬件不可能是高可靠的,比如Google的数据中心每天都会有大量的硬盘失效,所以分布式系统一定要对硬件容错,保证没有任何的单点失效。在这种很不稳定、很不可靠的硬件计算环境下,搭建一个分布式系统提供高可靠服务,必须要通过软件来容错。分布式系统针对不允许有单点失效的要求有两方面的设计考虑,一种是服务类的企业级应用,每个服务后台实例都要有多个副本,一两台硬件故障不至于影响所有服务实例;另外一种数据存储的应用,每份数据也必须要有多个备份,保证即使某几个硬件坏掉了数据也不会丢失。
高可靠性
除了单点失效,还要保证高可靠性。在分布式环境下,针对企业级服务应用,要做负载均衡和服务发现来保证高可靠性;针对数据服务,为了做到高可靠性,首先要按照某种算法来把整体数据分片(因为一台服务器装不下),然后按照同样的算法来进行分片查找。
数据本地性
再一个分布式设计理念是数据本地性,因为网络通信开销是分布式系统的瓶颈,要减少网络开销,应当让计算任务去找数据,而不是让数据去找计算。
分布式系统与Linux操作系统的比较
由于纵向拓展可优化空间太小(单台服务器的性能上限很明显),分布式系统强调横向扩展、横向优化,当分布式集群计算资源不足时,就要往集群里面添加服务器,来不停地提升分布式集群的计算能力。分布式系统要做到统一管理集群的所有服务器,屏蔽底层管理细节,诸如容错、调度、通信等,让开发人员觉得分布式集群在逻辑上是一台服务器。
和单机Linux操作系统相比,虽然分布式系统还没有成熟到成为“分布式操作系统”,但它和单机Linux一样要解决五大类操作系统必需的功能,即资源分配、进程管理、任务调度、进程间通信(IPC)和文件系统,可分别由Mesos、Docker、Marathon/Chronos、RabbitMQ和HDFS/Ceph来解决,对应于Linux下的Linux Kernel、Linux Kernel、init.d/cron、Pipe/Socket和ext4,如图1所示。

图1 分布式系统与Linux操作系统的比较
基于Mesos的分布式计算平台
Mesos资源分配原理
目前我们的Mesos集群部署在公有云服务上,用100多台虚拟机组成Mesos集群。Mesos不要求计算节点是物理服务器还是虚拟服务器,只要是Linux操作系统就可以。Mesos可以理解成一个分布式的Kernel,只分配集群计算资源,不负责任务调度。基于Mesos之上可以运行不同的分布式计算平台,如Spark、Storm、Hadoop、Marathon和Chronos等。Spark、Storm和Hadoop这样的计算平台有任务调度功能,可以直接使用Mesos SDK跟Mesos请求资源,然后自行调度计算任务,并对硬件容错。Marathon针对服务型分布式应用提供任务调度,比如企业网站等这类需要长时间运行的服务。通常网站应用程序没有任务调度和容错能力,因为网站程序不太会处理某个后台实例挂掉以后要在哪台机器上重新恢复等这类复杂问题。这类没有任务调度能力的服务型分布式应用,可以由Marathon来负责调度。比如,Marathon调度执行了网站服务的一百个后台实例,如果某个实例挂掉了,Marathon会在其他服务器上把这个实例恢复起来。Chronos是针对分布式批处理应用提供任务调度,比如定期处理日志或者定期调Hadoop等离线任务。
Mesos最大的好处是能够对分布式集群做细粒度资源分配。如图2所示,左边是粗粒的资源分配,右边是细粒的资源分配。

图2 Mesos资源调度的两种方式
图2左边有三个集群,每个集群三台服务器,分别装三种分布式计算平台,比如上面装三台Hadoop,中间三台是Spark,下面三台是Storm,三个不同的框架分别进行管理。右边是Mesos集群统一管理9台服务器,所有来自Spark、Hadoop或Storm的任务都在9台服务器上混合运行。Mesos首先提高了资源冗余率。粗粒资源管理肯定带来一定的浪费,细粒的资源提高资源管理能力。Hadoop机器很清闲,Spark没有安装,但Mesos可以只要任何一个调度马上响应。最后一个还有数据稳定性,因为所有9台都被Mesos统一管理,假如说装的Hadoop,Mesos会集群调度。这个计算资源都不共享,存储之间也不好共享。如果这上面跑了Spark做网络数据迁移,显然很影响速度。然后资源分配的方法就是resource offers,是在窗口的可调度的资源自己去选,Mesos是Spark或者是Hadoop等等。这种方法,Mesos的分配逻辑就很简单,只要不停地报告哪些是可用资源就可以了。Mesos资源分配方法也有一个潜在的缺点,就是无中心化的分配方式,所以有可能不会带来全局最优的方式。但这个数据资源缺点对目前来讲并不是很严重。现在一个计算中心资源贡献率很难达到50%,绝大部分计算中心都是很闲的状态。
Mesos资源分配示例
下面具体举例说明怎么用Mesos资源分配。如图3所示,中间是Mesos Master,下面是Mesos Slave,上面是Spark和Hadoop运行在Mesos之上。Mesos Master把可用资源报告给Spark或Hadoop。假定Hadoop有一个任务想运行,Hadoop从Mesos Master上报的可用资源中选择某个Mesos Slave节点,然后这个任务就会在这个Mesos Slave节点上执行,这是任务完成一次资源分配,接下来Mesos Master继续进行资源分配。

图3 Mesos资源分配示例
任务调度
Mesos只做一件事情,就是分布式集群资源分配,不管任务调度。Marathon和Chonos是基于Mesos来做任务调度。如图4所示,Mesos集群混合运行来自Marathon和Chronos的不同类型的任务。Marathon和Chonos基于Mesos做任务调度时,一定是动态调度,也就是每个任务在执行之前是不知道它将来在哪一台服务器上执行和绑定哪一个端口。如图5所示,9台服务器组成的Mesos集群上混合运行各种Marathon调度的任务,中间一台服务器坏掉以后,这台服务器上的两个任务就受影响,然后Marathon把这两个任务迁移到其他服务器上,这就是动态任务调度带来的好处,非常容易实现容错。
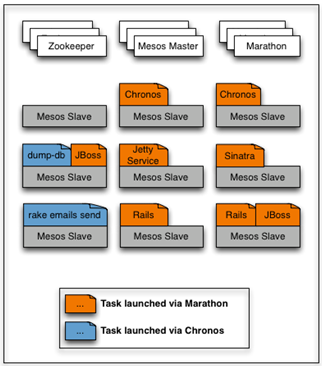
图4 Mesos集群运行不同类型的任务

图5 Marathon动态任务调度
为了减少硬件故障对应用服务的影响,应用程序要尽量做到无状态。无状态的好处是在程序受到影响时不需要进行任何恢复,这样这个程序只要重新调度起来就可以。无状态要求把状态数据放到存储服务器或者是消息队列里面,这样的好处是容错时恢复起来会变得很方便。
服务类的高可靠性
对于服务类型的任务,分布式环境保证服务的高可靠性,这需要负载均衡和服务发现。在分布式环境下做负载均衡有一个难点就是后台这些实例有可能发生动态变化,比如说某一个节点坏掉了,这个节点上的实例会受到影响,然后迁移到其他节点上。然而传统负载均衡器的后台实例地址端口都是静态的。所以在分布式环境下,为了做负载均衡一定要做服务发现。比如,某个服务之前有四个事例,现在新添加了两个实例,需要告诉负载均衡器新增加的实例的地址和端口。服务发现的过程是由几个模块配合完成,比如说Marathon给某个服务增加了新的实例,把新调度的实例地址端口写到Zookeeper,然后Bamboo把Zookeeper里存放的该服务新的实例的地址端口信息告诉负载均衡器,这样负载均衡器就知道新的实例地址端口,完成了服务发现。
数据类的高可靠性
对于服务类型的应用,分布式系统用负载均衡器和服务发现来保证高可靠性的服务。对于数据类型的应用,分布式系统同样要保证高可靠的数据服务。首先要做数据分片,一台服务器存不下所有数据就分成多份来存,但对数据进行分片必须按照某个规则来进行分片,后面查找时要按照同样的规则来进行分片查找,就是一致性。假定最原始的方案我们用Hash计算做成方法,在线性空间上分了三份以后,我要在数据分成三块机器来存,三台机器都存满了时,再把数据进行分配的时候不再把它分配到直线线性空间上,而是把它分配到环状空间上,把起点和终点连接起来,连成一个数据环,如图6所示,这样相应的数据点就放在这一块。如果要添加一个新的数据中心就在环上新切出来这块,这样很方便,切出来这一部分代表这一部分数据都应该放到新的芯片上,所以把原来子数据分片挪到嵌入式的分片上。

图6 数据分片
还有可能删除数据,我们把黄色的数据放到红色的数据上,这是环的好处。实际为了做到高可靠性,任何一个数据可能假定映射到黄色部分以后,这些黄色的部分只要映射到任何一个黄色的区域都会存在同一片机器上,同一片机器底层会有多个副本和做数据的备份,这是实际数据分片的一个实例。这是怎么做数据的高可靠性。这些数据分片,还有负载均衡,都是为了对应分布式分片硬件带来的不可靠和失效,这是我们用分布式系统最大的特点。
基于Docker的分布式计算平台
Docker工作流
我们主要用Docker来做分布式环境下的进程管理。Docker工作流如图7所示,我们不仅把Docker应用到生产阶段,也应用到开发阶段,所以我们每天编辑Dockerfile,提升Docker Images,测试上线,发Docker镜像,在我们内部私有Docker regis里面,再调到我们Docker集群生产环境里面,这和其他的Docker工作流没有什么区别。

图7 Docker工作流
在Mesos提交Docker任务
因为Mesos和Docker已经是无缝结合起来。通过Marathon和Chronos提交服务型应用和批处理型应用。Marathon和Chronos通过RESTful的方式提交任务,用JSON脚本设定应用的后台实例个数、应用的参数、以及Docker Images的路径等等。
分布式环境下的进程通信
在分布式环境下应用服务之间通信,是用分布式消息队列来做,我们用的是RabbitMQ。RabbitMQ也是一个分布式系统,它也要保证高可靠性、解决容错的问题。首先RabbitMQ也有集群,如图8所示,六个节点组成了一个RabbitMQ的集群,每个节点之间是互为备份的关系,任何一个坏掉,其他五个还可以提供服务,通过冗余来保证RabbitMQ的高可靠性。

图8 RabbitMQ集群
其次,RabbitMQ也有数据分片机制。因为消息队列有可能很长,长到所有的消息不可能都放到一个节点上,这时就要用分片,把很长的消息队列分为几段,分别放到不同的节点上。如图9所示是RabbitMQ的联盟机制,把一个消息队列打成两段,一段放在上游一段放在下游,假定下游消息队列的消息被消费完了就自动把上游消息队列里的消息移到下游,这样一个消息队列变成非常长的时候也不怕,分片到多个节点上即可。

图9 消息队列分片
分布式文件系统
最后讲一下分布式文件系统HDFS和Ceph。Hadoop文件系统HDFS,如图10所示,每个数据块有三个备份,必须放在不同的服务器上,而且三个备份里面每个机架最多放两份,这么做也是为了容错。Ceph是另一种流行的开源分布式文件系统。Ceph把网络存储设备抽象成一张逻辑硬盘,然后“挂载”到分布式集群的每台服务器上,原理上非常像是Linux操作系统Mount一块物理硬盘。这样一来,用户程序访问Ceph的文件系统就跟访问Linux本地路径一样,非常方便。

图10 分布式文件系统
分布式环境下的监控
分布式环境下,程序不是运行在本地,而是在集群上面,没有监控就等于程序运行在黑盒子下,无法调优,必须要有监控。分布式环境下的监控分为两个部分,一是性能监控,另一个是报警。性能监控要知道每个应用程序运行状态是什么样,即每一个应用程序占了多少CPU内存、服务的请求处理延迟等。我们是用Graphite来做应用程序性能监控;还有其他系统,比如MongoDB、Hadoop等开源系统,我们用Ganglia来做性能监控,比如CPU内存硬盘的使用情况等。报警是要在关键服务出现故障时,通知开发运维人员及时排解故障,我们用Zabbix来做报警。
转载于:https://my.oschina.net/CandyDesire/blog/465464
最后
以上就是危机糖豆最近收集整理的关于基于Mesos和Docker的分布式计算平台的全部内容,更多相关基于Mesos和Docker内容请搜索靠谱客的其他文章。








发表评论 取消回复