蒋彪,腾讯云高级工程师,10+年专注于操作系统相关技术,Linux内核资深发烧友。目前负责腾讯云原生OS的研发,以及OS/虚拟化的性能优化工作。
## 导语
云原生场景,相比于传统的IDC场景,业务更加复杂多样,而原生 Linux kernel 在面对云原生的各种复杂场景时,时常显得有些力不从心。本文基于一个腾讯云原生场景中的一个实际案例,展现针对类似问题的一些排查思路,并希望借此透视Linux kernel的相关底层逻辑以及可能的优化方向。
## 背景
腾讯云客户某关键业务容器所在节点,偶发CPU sys(内核态CPU占用)冲高的问题,导致业务抖动,复现无规律。节点使用内核为upstream 3.x版本。
## 现象
在业务负载正常的情况下,监控可见明显的CPU占用率毛刺,最高可达100%,同时节点load飙升,此时业务会随之出现抖动。
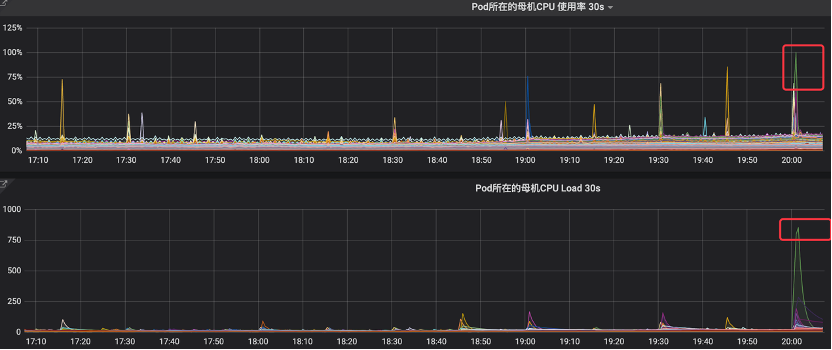
## 捕获数据
### 思路
故障现象为CPU sys冲高,即CPU在内核态持续运行导致,分析思路很简单,需要确认sys冲高时,具体的执行上下文信息,可以是堆栈,也可以是热点。
**难点:**
由于故障出现随机,持续时间比较短(秒级),而且由于是内核态CPU冲高,当故障复现时,常规排查工具无法得到调度运行,登录终端也会hung住(由于无法正常调度),所以常规监控(通常粒度为分钟级)和排查工具均无法及时抓到现场数据。
### 具体操作
#### 秒级监控
通过部署秒级监控(基于atop),在故障复现时能抓到故障发生时的系统级别的上下文信息,示例如下:
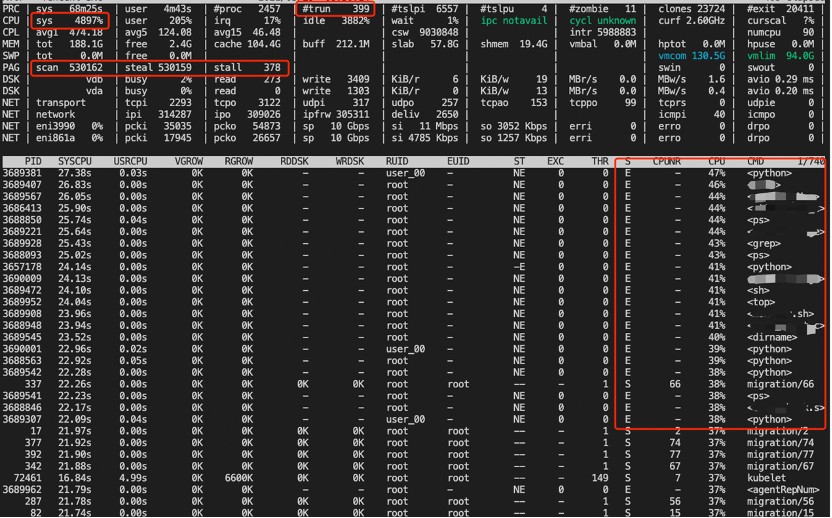
从图中我们可以看到如下现象:
1. sys很高,usr比较低
2. 触发了页面回收(PAG行),且非常频繁
3. 比如ps之类的进程普遍内核态CPU使用率较高,而用户态CPU使用率较低,且处于退出状态
至此,抓到了系统级别的上下文信息,可以看到故障当时,系统中正在运行的、CPU占用较高的进程和状态,也有一些系统级别的统计信息,但仍无从知晓故障当时,sys具体消耗在了什么地方,需要通过其他方法/工具继续抓现场。
#### 故障现场
如前面所说,这里说的**现场**,可以是故障当时的瞬时堆栈信息,也可以是热点信息。
对于堆栈的采集,直接能想到的简单方式:
1. pstack
2. cat /proc/<pid>/stack
当然这两种方式都依赖:
1. 故障当时CPU占用高的进程的pid
2. 故障时采集进程能及时执行,并得到及时调度、处理
显然这些对于当前的问题来说,都是难以操作的。
对于热点的采集,最直接的方式就是perf工具,简单、直接、易用。但也存在问题:
1. 开销较大,难以常态化部署;如果常态化部署,采集数据量巨大,解析困难
2. 故障时不能保证能及时触发执行
perf本质上是通过pmu硬件进行周期性采样,实现时采用NMI(x86)进行采样,所以,一旦触发采集,就不会受到调度、中断、软中断等因素的干扰。但由于执行perf命令的动作本身必须是在进程上下文中触发(通过命令行、程序等),所以在故障发生时,由于内核态CPU使用率较高,并不能保证perf命令执行的进程能得到正常调度,从而及时采样。
因此针对此问题的热点采集,必须提前部署(常态化部署)。通过两种方式可解决(缓解)前面提到的开销大和数据解析困难的问题:
1. 降低perf采样频率,通常降低到99次/s,实测对真实业务影响可控
2. Perf数据切片。通过对perf采集的数据按时间段进行切片,结合云监控中的故障时间点(段),可以准确定位到相应的数据片,然后做针对性的统计分析。
具体方法:
采集:
```
`.``/perf` `record -F99 -g -a`
```
分析:
```
#查看header里面的captured on时间,应该表示结束时间,time of last sample最后采集时间戳,单位是秒,可往前追溯现场时间
./perf report --header-only
#根据时间戳索引
./perf report --time start_tsc,end_tsc
```
按此思路,通过提前部署perf工具采集到了一个**现场**,热点分析如下:
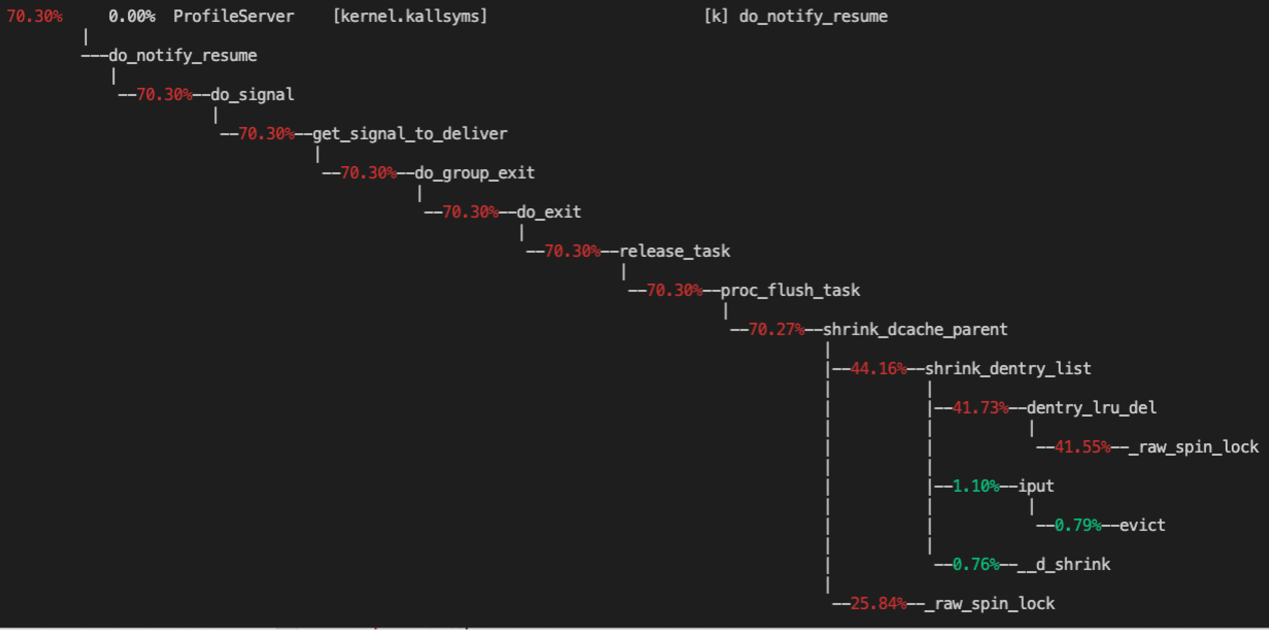
可以看到,主要的热点在于 shrink_dentry_list 中的一把 spinlock。
## 分析
### 现场分析
根据 perf 的结果,我们找到内核中的热点函数 dentry_lru_del,简单看下代码:
```
// dentry_lru_del()函数:
static void dentry_lru_del(struct dentry *dentry) {
if (!list_empty(&dentry->d_lru)) {
spin_lock(&dcache_lru_lock);
__dentry_lru_del(dentry);
spin_unlock(&dcache_lru_lock);
}
}
```
函数中使用到的 spinlock 为 dentry_lru_lock,在3.x内核代码中,这是一把超大锁(全局锁)。单个文件系统的所有的 dentry 都放入同一个lru链表(位于superblock)中,对该链表的几乎所有操作(dentry_lru_(add|del|prune|move_tail))都需要拿这把锁,而且所有的文件系统共用了同一把全局锁(3.x内核代码),参考 add 流程:
```
static void dentry_lru_add(struct dentry *dentry) {
if (list_empty(&dentry->d_lru)) {
// 拿全局锁
spin_lock(&dcache_lru_lock);
// 把dentry放入sb的lru链表中
list_add(&dentry->d_lru, &dentry->d_sb->s_dentry_lru);
dentry->d_sb->s_nr_dentry_unused++;
dentry_stat.nr_unused++;
spin_unlock(&dcache_lru_lock);
}
}
```
由于 dentry_lru_lock 是全局大锁,可以想到的一些典型场景中都会持这把锁:
1. 文件系统 umount 流程
2. rmdir 流程
3. 内存回收 shrink_slab 流程
4. 进程退出清理/proc目录流程(proc_flush_task)-前面抓到的现场
其中,文件系统 umount 时,会清理掉对应 superblock 中的所有 dentry,则会遍历整个 dentry 的lru链表,如果 dentry 数量过多,将直接导致 sys 冲高,而且其他依赖于 dentry_lru_lock 的流程也会产生严重的锁竞争,由于是 spinlock,也会导致其他上下文 sys 冲高。
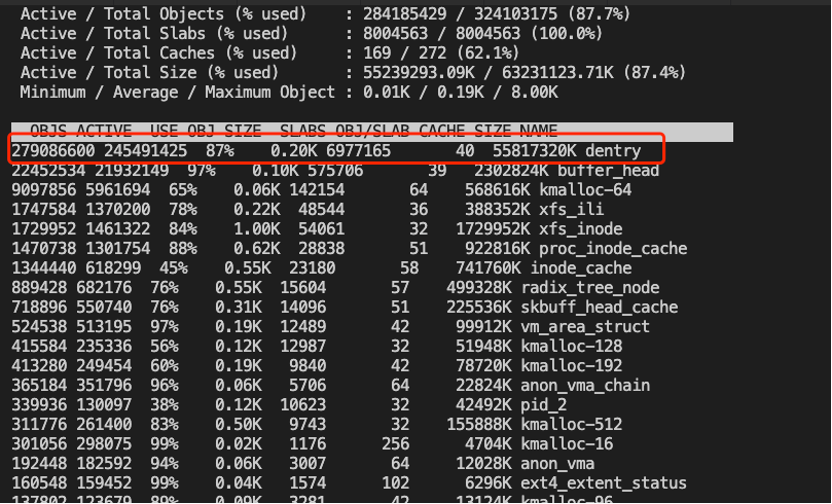
接下来,再回过头看之前的秒级监控日志,就会发现故障是系统的 slab 占用近60G,非常大:

而dentry cache(位于slab中)很可能是罪魁祸首,确认slab中的对象的具体分布的最简便的方法:Slabtop,在相同业务集群其他节点找到类似环境,可见确实dentry占用率绝大部分:
我们接下来可以使用 crash 工具在线解析对应文件系统的 superblock 的 dentry lru 链表,可见 unused entry 数量高达2亿+
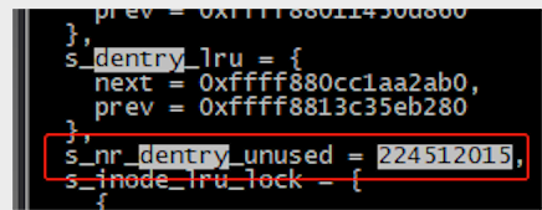
另一方面,根据业务的上下文日志,可以确认其中一类故障时,业务有删除 pod 的操作,而删除pod过程中,会 umount overlayfs,然后会触发文件系统 umount 操作,然后就出现这样的现象,场景完全吻合!
进一步,在有 2亿+dentry 环境中,手工drop slab并通过time计时,接近40s,阻塞时间也能吻合。
```
`time` `echo` `2 > ``/proc/sys/vm/drop_caches`
```
至此,基本能解释:sys 冲高的直接原因为dentry数量太多。
### 亿级 Dentry 从何而来
接下来的疑问:为何会有这么多dentry?
直接的解答方法,找到这些dentry的绝对路径,然后根据路径反推业务即可。那么2亿+dentry如何解析?
两种办法:
**方法1:在线解析**
通过crash工具在线解析(手工操练),
基本思路:
1. 找到sb中的dentry lru list位置
2. List所有的node地址,结果存档
3. 由于entry数量过多,可以进行切片,分批保存至单独文档,后续可以批量解析。
4. Vim列编辑存档文件,批量插入命令(file),保存为批量执行命令的文件
5. crash -i批量执行命令文件,结果存档
6. 对批量执行结果进行文本处理,统计文件路径和数量
结果示例:

其中:
1. db为后面提及的类似xxxxx_dOeSnotExist_.db文件,占大部分。
2. session为systemd为每个session创建的临时文件
db文件分析如下:
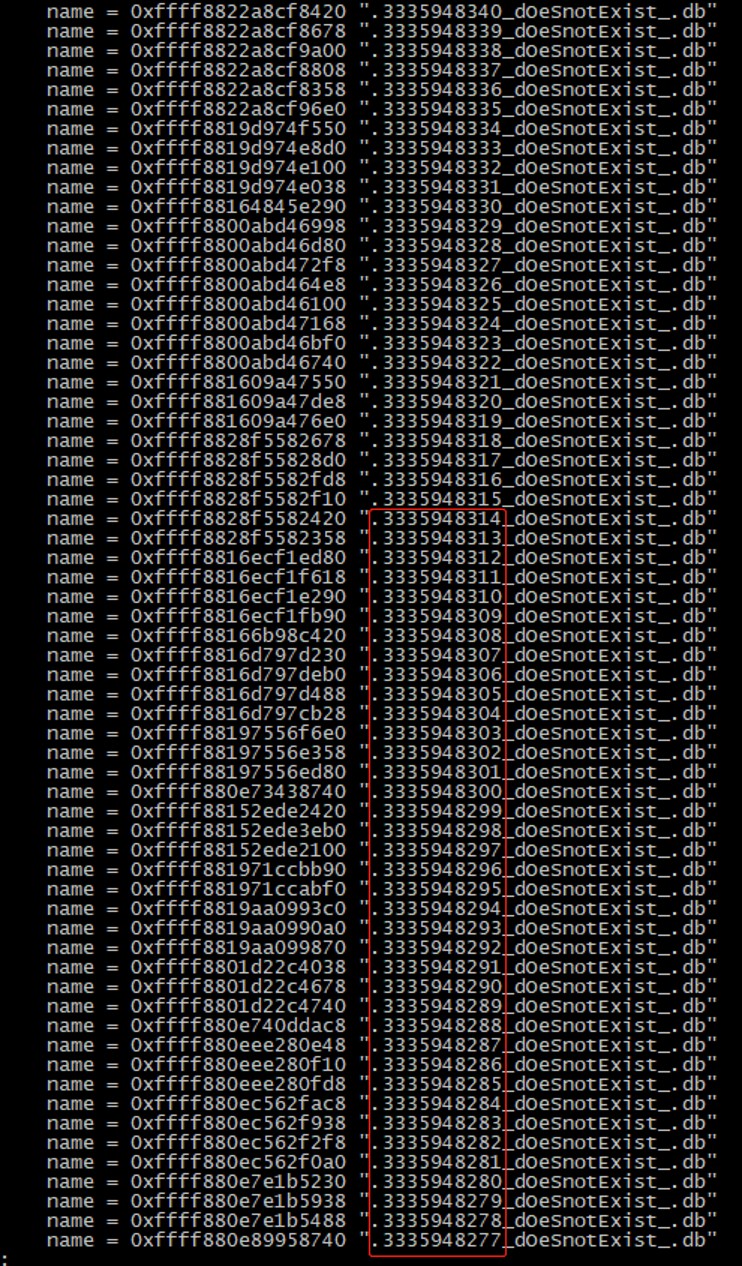
文件名称有几个明显特征:
1. 有统一的计数,可能是某一个容器产生
2. 名称中包含字符串“dOeSnotExist“
3. 都拥有.db的后缀
对应的绝对路径示例如下(用于确认所在容器)


如此可以通过继续通过 overlayfs id 继续查找对应的容器(docker inspect),确认业务。
**方法2:动态跟踪**
通过编写 systemtap 脚本,追踪 dentry 分配请求,可抓到对应进程(在可复现的前提下),脚本示例如下:
```
probe kernel.function("d_alloc") {
printf("[%d] %s(pid:%d ppid:%d) %s %sn", gettimeofday_ms(), execname(), pid(), ppid(), ppfunc(), kernel_string_n($name->name, $name->len));
}
```
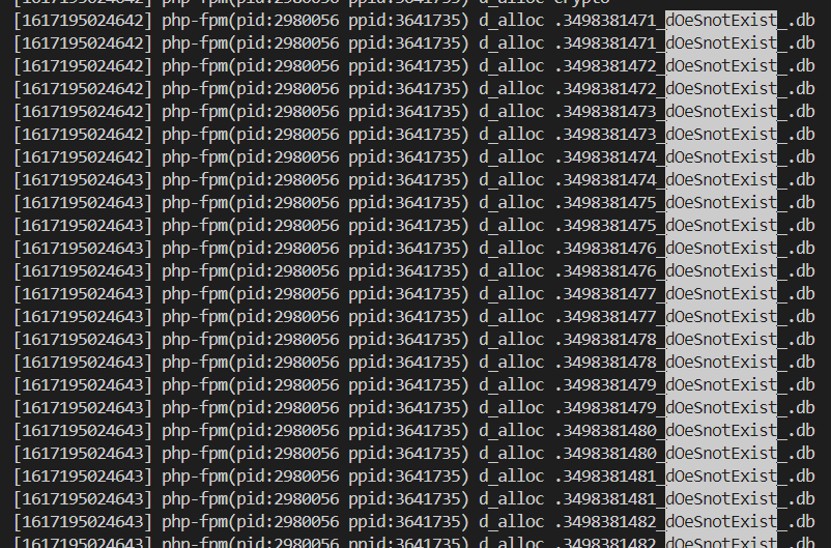
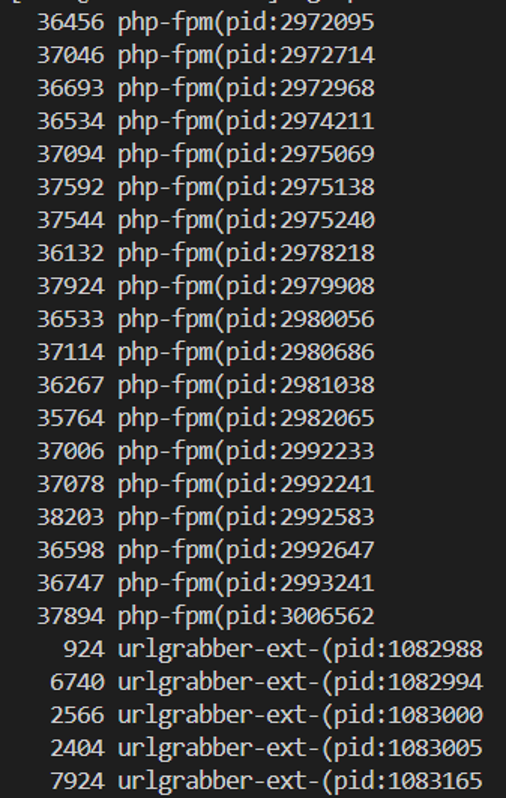
按进程维度统计:
### Xxx_dOeSnotExist_.db文件分析
通过前面抓取到的路径可以判断该文件与nss库(证书/密钥相关)相关,https 服务时,需要使用到底层nss密码库,访问web服务的工具如 curl 都使用到了这个库,而nss库存在bug:
https://bugzilla.mozilla.org/show_bug.cgi?id=956082
https://bugzilla.redhat.com/show_bug.cgi?id=1779325
大量访问不存在的路径这个行为,是为了检测是否在网络文件系统上访问 nss db, 如果访问临时目录比访问数据库目录快很多,会开启cache。这个探测过程会尝试 33ms 内循环 stat 不存在的文件(最大1万次), 这个行为导致了大量的 negative dentry。
使用curl工具可模拟这个bug,在测试机中执行如下命令:
```
`strace` `-f -e trace=access curl ``'https://baidu.com'`
```
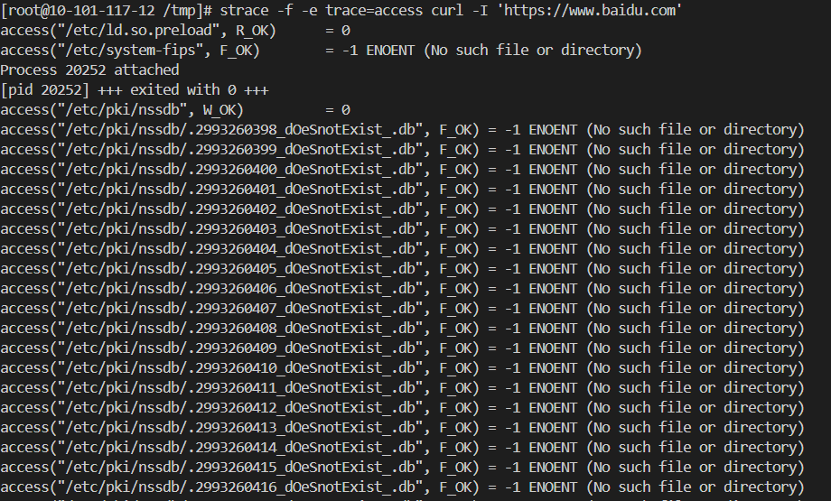
规避方法:设置环境变量 NSS_SDB_USE_CACHE=yes
解决方法:升级 pod 内的 nss 服务
至此,问题分析近乎完成。看起来就是一个由平平无奇的用户态组件的bug引发的血案,分析方法和手段也平平无奇,但后面的分析才是我们关注的重点。
### 另一种现象
回想前面讲到的 dentry_lru_lock 大锁竞争的场景,仔细分析其他几例出现 sys 冲高的秒级监控现场,发现这种场景中并无删除pod动作(也就是没有 umount 动作),也就意味着没有遍历 dentry lru 的动作,按理不应该有反复持有 dentry_lru_lock 的情况,而且同时会出现sys冲高的现象。
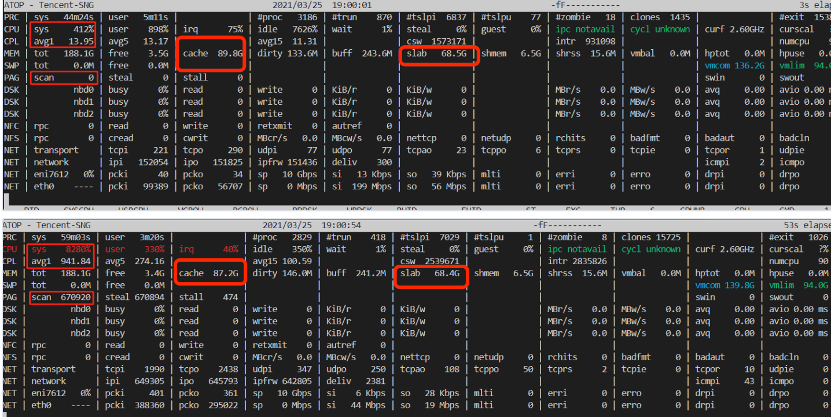
可以看到,故障前后的 cache 回收了2G+,但实际的 free 内存并没有增加,反而减少了,说明此时,业务应该正在大量分配新内存,导致内存不足,从而导致内存一直处于回收状态(scan 数量增加很多)。
而在内存紧张进入直接回收后时,会(可能)shrink_slab,以至于需要持 dentry_lru_lock,这里的具体逻辑和算法不分析了:)。当回收内存压力持续时,可能会反复/并发进入直接回收流程,导致 dentry_lru_lock 锁竞争,同时,在出现问题的业务场景中,单pod进程拥有2400+线程,批量退出时调用 proc_flush_task 释放/proc目录下的进程目录项,从而也会批量/并发获取 dcache_lru_lock 锁,加剧锁竞争,从而导致sys冲高。
两种现象都能基本解释了。其中,第二种现象相比于第一种,更复杂,原因在于其中涉及到了内存紧张时的并发处理逻辑。
## 解决 & 思考
### 直接解决/规避
基于前面的分析,可以看出,最直接的解决方式为:
升级 pod nss 服务,或者设置设置环境变量规避
但如果再思考下:如果nss没有 bug,但其他组件也做了类似可能产生大量 dentry 的动作,比如执行类似这样的脚本:
```
#!/bin/bash
i=0
while (( i < 1000000 )) ; do
if test -e ./$i; then
echo $i > ./$i
fi
((i++))
done
```
本质上也会不停的产生 dentry(slab),面对这种场景该怎么办?可能的简便的解决/规避方法是:周期性 drop cache/slab,虽然可能引发偶尔的性能小波动,但基本能解决问题。
### 锁优化
前面分析指出,导致 sys 冲高的直接原因是 dcache_lru_lock 锁的竞争,那这把锁是否有优化空间呢?
答案是:有
看看3.x内核代码中的锁使用:
```
static void dentry_lru_add(struct dentry *dentry) {
if (list_empty(&dentry->d_lru)) {
//全局锁
spin_lock(&dcache_lru_lock);
list_add(&dentry->d_lru, &dentry->d_sb->s_dentry_lru);
dentry->d_sb->s_nr_dentry_unused++;
dentry_stat.nr_unused++;
spin_unlock(&dcache_lru_lock);
}
}
```
可以明显看出这是个全局变量,即所有文件系统公用的全局锁。而实际的 dentry_lru 是放在 superblock 中的,显然这把锁的范围跟lru是不一致的。
于是,新内核版本中,果真把这把锁放入了 superblock 中:
```
static void d_lru_del(struct dentry *dentry) {
D_FLAG_VERIFY(dentry, DCACHE_LRU_LIST);
dentry->d_flags &= ~DCACHE_LRU_LIST;
this_cpu_dec(nr_dentry_unused);
if (d_is_negative(dentry)) this_cpu_dec(nr_dentry_negative);
//不再加单独的锁,使用list_lru_del原语中自带的per list的lock
WARN_ON_ONCE(!list_lru_del(&dentry->d_sb->s_dentry_lru, &dentry->d_lru));
}
bool list_lru_add(struct list_lru *lru, struct list_head *item) {
int nid = page_to_nid(virt_to_page(item));
struct list_lru_node *nlru = &lru->node[nid];
struct mem_cgroup *memcg;
struct list_lru_one *l;
//使用per lru list的lock
spin_lock(&nlru->lock);
if (list_empty(item)) {
// …
}
spin_unlock(&nlru->lock);
return false;
}
`
```
新内核中,弃用了全局锁,而改用了 list_lru 原语中自带的 lock,而由于 list_lru 自身位于 superblock 中,所以,锁变成了per list(superblock)的锁,虽然还是有点大,但相比之前减小了许多。
所以,新内核中,对锁做了优化,但未必能完全解决问题。
### 继续思考1
为什么访问不存在的文件/目录(nss cache和上述脚本)也会产生 dentry cache 呢?一个不存在的文件/目录的 dentry cache 有何用处呢?为何需要保留?表面看,看似没有必要为一个不存在的文件/目录保留 dentry cache。其实,这样的 dentry cache(后文简称dcache)在内核中有标准的定义:**Negative dentry**
```
`A special form of dcache entry gets created ``if` `a process attempts to access a non-existent ``file``. Such an entry is known as a negative dentry.`
```
Negative dentry 具体有何用途?由于 dcache 的主要作用是:用于加快文件系统中的文件查找速度,设想如下场景:如果一个应用总是从一些预先配置好的路径列表中去查找指定文件(类似于 PATH 环境变量),而且该文件仅存在与这些路径中的一个,这种情况下,如果存在 negative dcache,则能加速失败路径的查找,整体提升文件查找的性能。
### 继续思考2
是否能单独限制 negative dcache 的数量呢?
答案是:可以。
Rhel7.8版本内核中(3.10.0-1127.el7),合入了一个 feature:negative-dentry-limit,专门用来限制 negative dcache 的数量,关于这个 feature 的说明请参考:
https://access.redhat.com/solutions/4982351
关于 feature 的具体实现,请参考:
https://lwn.net/Articles/813353/
具体原理就不解释了:)
残酷的现实是:rhel8和upstream kernel都没有合入这个feature,为啥呢?
请参考:
Redhat 的官方解释(其实并没有解释清楚)
https://access.redhat.com/solutions/5777081
再看看社区的激烈讨论:
https://lore.kernel.org/patchwork/cover/960253/
Linus 也亲自站出来反对。整体基调是:现有的 cache reclaim 机制已经够用(够复杂了),再结合 memcg 的 low 水线等保护措施(cgroup v2才有哦),能处理好 cache reclaim 的活,如果限制的话,可能会涉及到同步回收等,引入新阻塞、问题和不必要的复杂,negative dache 相比于普通的 pagecache 没有特别之处,不应该被区别对待(被优待),而且 negative dcache 本身回收很快,balabala。
结果是,还是不能进社区,尽管这个功能看起来是如此“实用”。
### 继续思考3
还有其他方式能限制 dcache 吗?
答案是:还有
文件系统层,提供了 unused_dentry_hard_limit 参数,可以控制 dcache 的整体数量,整体控制逻辑类似。具体代码原理也不赘述了,欢迎大家查阅代码。
遗憾的是,该参数依赖于各文件系统自身实现,3.x内核中只看到 overlayfs 有实现,其他文件系统没有。所以,通用性有所限制,具体效果未知(未实际验证)。
至此,看似真的已经分析清楚了?
## Think More
**能否再思考一下:为什么 dentry 数量这么多,而没有被及时回收呢?**
当前案例表面上看似一个有应用(nss)bug引发的内核抖动问题,但如果仔细思考,你会发现这其实还是内核自身面对类似场景的能力不足,其本质问题还在于:
1. 回收不及时
2. cache 无限制
### 回收不及时
由于内核中会将访问过的所有文件(目录)对应的 dentry 都缓存起来存于slab中(除非有特性标记),用于下次访问时提示效率,可以看到出问题的环境中,slab占用都高达60G,其中绝大部分都是 dentry 占用。
而内核中,仅(绝大部分场景)当内存紧张时(到达内存水线)才会触发主动回收cache(主要包括slab和pagecache),而问题环境中,内存通常很充足,实际使用较少,绝大部分为缓存(slab和pagecache)。
当系统free内存低于low水线时,触发异步回收(kswapd);当 free 内存低于 min 水线是触发同步回收。也就是说仅当free内存低到一定程度(水线)时才能开始回收 dentry,而由于水线通常较低,导致回收时机较晚,而当业务有突发内存申请时,可能导致短期内处于内存反复回收状态。
注:水线(全局)由内核默认根据内存大小计算的,upstream内核中默认的水线比较低。在部分容器场景确实不太合理,新版本内核中有部分优化(可以设置min和low之间的距离),但也不完美。
**Memcg async reclaim**
在云原生(容器)场景中,针对cache的有效、及时回收,内核提供了标准异步回收方式:到达low水线后的 kswapd 回收,但 kswapd 是per-node粒度(全局),即使在调大 min 和 low 水线之间的 distance 之后(高版本内核支持),仍存在如下不足:
1. distance 参数难以通用,难以控制
2. 全局扫描开销较大,比较笨重
3. 单线程(per-node)回收,仍可能较慢,不及时
在实际应用中,也常见因为内存回收不及时导致水线被击穿,从而出现业务抖动的问题。针对类似场景的问题,社区在多年前有人提交了 memcg async relaim 的想法和补丁(相对原始),基本原理为:为每个 pod (memcg)创建一个类似 kswapd 这样的内存异步回收线程,当pod级别的 async low 水线达到后,触发 per-cgroup 基本的异步内存回收。理论上也能比较好的解决/优化类似场景的问题。但最终经过长时间讨论后,社区最终没有接受,主要原因还是出于容器资源开销和 Isolation 的考虑:
1. 如果为每个 cgroup 创建一个内核线程,当容器数量较多时,内存线程数量增多,开销难以控制。
2. 后续优化版本去除了 per-cgroup 的内核回收线程,而借用于内核自带的 workqueue 来做,由于 workqueue 的池化能力,可以合并请求,减少线程线程创建数量,控制开销。但随之而来的是隔离性(Isolation)的问题,问题在于新提交的 workqueue 请求无法 account 到具体的 pod(cgroup),破坏了容器的隔离性。
从Maintainer的角度看,拒绝的理由很充分。但从(云原生)用户的角度看,只能是再次的失落,毕竟实际的问题并未得到真正充分解决。
虽然 memcg async reclaim 功能最终未能被社区接受,但仍有少数厂商坚持在自己的版本分支中合入了相应功能,其中的典型代表如 Google,另外还包括我们的 TencentOS Server (原TLinux),我们不仅合入/增强了原有的 memcg async reclaim 功能,还将其整体融入了我们的云原生资源 QoS 框架,整体为保证业务的内存服务质量提供底层支撑。
### cache 无限制
Linux 倾向于尽可能将空闲内存利用起来,用做cache(主要是page cache和slab),用于提升性能(主要是文件访问)。意味着系统中 cache 可以几乎不限制(只要有free内存)的增长。在现实场景中带来不少的问题,本案例中的问题就是其中一种典型。如果有 cache limit 能力,理论上能很大程度解决类似问题。
**Cache limit**
而关于page cache limit话题,多年前曾在 Kernel upstream 社区中持续争论了很长一段时间,但最终还是未能进入upstream,主要原因还在于违背了尽量利用内存的初衷。尽管在一些场景中确实存在一些问题,社区仍建议通过其他方式解决(业务或者其他内核手段)。
虽然社区未接受,但少部分厂商还是坚持在自己的版本分支中合入了 page cache limit 功能,其中典型代表如SUSE,另外还包括我们的 TencentOS Server(原TLinux),我们不仅合入/增强了 page cache limit 功能,支持同步/异步回收,同时还增强了 slab limit 的限制,可以同时限制 page cache 和 slab 的用量。该功能在很多场景中起到了关键作用。
## 结论
1. 在如下多个条件同时发生时,可能出现 dentry list 相关的锁竞争,导致sys高:
- 系统中存在大量dentry缓存(容器访问过的大量文件/目录,不停累积)
- 业务突发内存申请,导致free内存突破水线,触发内存回收(反复)
- 业务进程退出,退出时需要清理/proc 文件,期间依赖于 dentry list 的大锁,出现 spinlock race。
2. 用户态应用 nss bug 导致 dcache 过多,是事故的直接原因。
3. 深层次思考,可以发现,upstream kernel 为考虑通用性、架构优雅等因素,放弃了很多实用功能和设计,在云原生场景中,难以满足极致需求,要成为云原生OS的核心底座,还需要深度hack。
4. TencentOS Server 为云原生海量场景做了大量深度定制和优化,能自如应对复杂、极端云原生业务带来各种挑战(包括本案例中涉及的问题)。此外,TencentOS Server 还设计实现了云原生资源 QoS 保障特性(RUE),为不同优先级的容器提供了各种关键资源的 QoS 保障能力。敬请期待相关分享。
## 结语
在云原生场景中,upstream kerne l难以满足极端场景的极致需求,要成为云原生OS的底座,还需要深度hack。而 TencentOS Server 正为之不懈努力!
【注:案例素材取自腾讯云虚拟化团队和云技术运营团队】
*容器服务(Tencent Kubernetes Engine,TKE)是腾讯云提供的基于 Kubernetes,一站式云原生 PaaS 服务平台。为用户提供集成了容器集群调度、Helm 应用编排、Docker 镜像管理、Istio服务治理、自动化DevOps以及全套监控运维体系的企业级服务。*
最后
以上就是单薄蚂蚁最近收集整理的关于内存回收导致关键业务抖动案例分析-论云原生OS内存QoS保障的全部内容,更多相关内存回收导致关键业务抖动案例分析-论云原生OS内存QoS保障内容请搜索靠谱客的其他文章。








发表评论 取消回复