这篇是kaggle上的,有关检测恶意代码的模型,本人在这篇博客解说了有关其获取数据之后的数据预处理。一下是根据其每一步的解说:
1.Load Data(获取数据):
# referred https://www.kaggle.com/theoviel/load-the-totality-of-the-data
dtypes = {
'MachineIdentifier': 'category',
'ProductName': 'category',
'EngineVersion': 'category',
'AppVersion': 'category',
'AvSigVersion': 'category',
'IsBeta': 'int8',
'RtpStateBitfield': 'float16',
'IsSxsPassiveMode': 'int8',
'DefaultBrowsersIdentifier': 'float32',
'AVProductStatesIdentifier': 'float32',
'AVProductsInstalled': 'float16',
'AVProductsEnabled': 'float16',
'HasTpm': 'int8',
'CountryIdentifier': 'int16',
'CityIdentifier': 'float32',
'OrganizationIdentifier': 'float16',
'GeoNameIdentifier': 'float16',
'LocaleEnglishNameIdentifier': 'int16',
'Platform': 'category',
'Processor': 'category',
'OsVer': 'category',
'OsBuild': 'int16',
'OsSuite': 'int16',
'OsPlatformSubRelease': 'category',
'OsBuildLab': 'category',
'SkuEdition': 'category',
'IsProtected': 'float16',
'AutoSampleOptIn': 'int8',
'PuaMode': 'category',
'SMode': 'float16',
'IeVerIdentifier': 'float16',
'SmartScreen': 'category',
'Firewall': 'float16',
'UacLuaenable': 'float32',
'UacLuaenable': 'float64', # was 'float32'
'Census_MDC2FormFactor': 'category',
'Census_DeviceFamily': 'category',
'Census_OEMNameIdentifier': 'float32', # was 'float16'
'Census_OEMModelIdentifier': 'float32',
'Census_ProcessorCoreCount': 'float16',
'Census_ProcessorManufacturerIdentifier': 'float16',
'Census_ProcessorModelIdentifier': 'float32', # was 'float16'
'Census_ProcessorClass': 'category',
'Census_PrimaryDiskTotalCapacity': 'float64', # was 'float32'
'Census_PrimaryDiskTypeName': 'category',
'Census_SystemVolumeTotalCapacity': 'float64', # was 'float32'
'Census_HasOpticalDiskDrive': 'int8',
'Census_TotalPhysicalRAM': 'float32',
'Census_ChassisTypeName': 'category',
'Census_InternalPrimaryDiagonalDisplaySizeInInches': 'float32', # was 'float16'
'Census_InternalPrimaryDisplayResolutionHorizontal': 'float32', # was 'float16'
'Census_InternalPrimaryDisplayResolutionVertical': 'float32', # was 'float16'
'Census_PowerPlatformRoleName': 'category',
'Census_InternalBatteryType': 'category',
'Census_InternalBatteryNumberOfCharges': 'float64', # was 'float32'
'Census_OSVersion': 'category',
'Census_OSArchitecture': 'category',
'Census_OSBranch': 'category',
'Census_OSBuildNumber': 'int16',
'Census_OSBuildRevision': 'int32',
'Census_OSEdition': 'category',
'Census_OSSkuName': 'category',
'Census_OSInstallTypeName': 'category',
'Census_OSInstallLanguageIdentifier': 'float16',
'Census_OSUILocaleIdentifier': 'int16',
'Census_OSWUAutoUpdateOptionsName': 'category',
'Census_IsPortableOperatingSystem': 'int8',
'Census_GenuineStateName': 'category',
'Census_ActivationChannel': 'category',
'Census_IsFlightingInternal': 'float16',
'Census_IsFlightsDisabled': 'float16',
'Census_FlightRing': 'category',
'Census_ThresholdOptIn': 'float16',
'Census_FirmwareManufacturerIdentifier': 'float16',
'Census_FirmwareVersionIdentifier': 'float32',
'Census_IsSecureBootEnabled': 'int8',
'Census_IsWIMBootEnabled': 'float16',
'Census_IsVirtualDevice': 'float16',
'Census_IsTouchEnabled': 'int8',
'Census_IsPenCapable': 'int8',
'Census_IsAlwaysOnAlwaysConnectedCapable': 'float16',
'Wdft_IsGamer': 'float16',
'Wdft_RegionIdentifier': 'float16',
'HasDetections': 'int8'
}
train = pd.read_csv('../input/train.csv', dtype=dtypes) #读取数据原文件的内容
train.shape #显示其大小
为何有这个呢?因为在原文件中已经排列好了有关数据,上面的代码中,第一列就是原文件中数据每一列的列名称,第二列就是原文件中数据每一列的数据类型
输出:
(8921483, 83)
#、有8921483行,83列,就是说有原文件有8921483个样本,每个样本有83个特征
droppable_features = []
定义一个列表,用于后面存储需要删去的特征的名称(预处理就是对数据进行优化,一般是删去不合格的数据,使数据易于训练,能有效保证数据的合理性)。
- Feature Engineering(特征工程),通俗点,就是要开始处理数据了
2.1 mostly-missing Columns:处理缺失值太多的列,就是说,一个特征就是一个列,而这个列中,并不是每一行都有值,也就是缺失,一般是处理缺失值比重高于99%的特征
(train.isnull().sum()/train.shape[0]).sort_values(ascending=False)
这句代码的意思是显示数据中所有特征中含缺失值的占比,也就是每一列的缺失值占比,而且按降序排序,也就是说第一行往下,缺失值占比逐渐下降
输出:
PuaMode 0.999741
Census_ProcessorClass 0.995894
DefaultBrowsersIdentifier 0.951416
Census_IsFlightingInternal 0.830440
Census_InternalBatteryType 0.710468
Census_ThresholdOptIn 0.635245
Census_IsWIMBootEnabled 0.634390
SmartScreen 0.356108
OrganizationIdentifier 0.308415
SMode 0.060277
CityIdentifier 0.036475
Wdft_IsGamer 0.034014
Wdft_RegionIdentifier 0.034014
Census_InternalBatteryNumberOfCharges 0.030124
Census_FirmwareManufacturerIdentifier 0.020541
Census_IsFlightsDisabled 0.017993
Census_FirmwareVersionIdentifier 0.017949
Census_OEMModelIdentifier 0.011459
Census_OEMNameIdentifier 0.010702
Firewall 0.010239
Census_TotalPhysicalRAM 0.009027
Census_IsAlwaysOnAlwaysConnectedCapable 0.007997
Census_OSInstallLanguageIdentifier 0.006735
IeVerIdentifier 0.006601
Census_PrimaryDiskTotalCapacity 0.005943
Census_InternalPrimaryDiagonalDisplaySizeInInches 0.005283
Census_InternalPrimaryDisplayResolutionHorizontal 0.005267
Census_InternalPrimaryDisplayResolutionVertical 0.005267
Census_ProcessorModelIdentifier 0.004634
...
ProductName 0.000000
HasTpm 0.000000
OsBuild 0.000000
IsBeta 0.000000
OsSuite 0.000000
IsSxsPassiveMode 0.000000
HasDetections 0.000000
SkuEdition 0.000000
Census_OSInstallTypeName 0.000000
Census_IsPenCapable 0.000000
Census_IsTouchEnabled 0.000000
Census_IsSecureBootEnabled 0.000000
Census_FlightRing 0.000000
Census_ActivationChannel 0.000000
Census_GenuineStateName 0.000000
Census_IsPortableOperatingSystem 0.000000
Census_OSWUAutoUpdateOptionsName 0.000000
Census_OSUILocaleIdentifier 0.000000
Census_OSSkuName 0.000000
AutoSampleOptIn 0.000000
Census_OSEdition 0.000000
Census_OSBuildRevision 0.000000
Census_OSBuildNumber 0.000000
Census_OSBranch 0.000000
Census_OSArchitecture 0.000000
Census_OSVersion 0.000000
Census_HasOpticalDiskDrive 0.000000
Census_DeviceFamily 0.000000
Census_MDC2FormFactor 0.000000
MachineIdentifier 0.000000
Length: 83, dtype: float64
前面我们说一般处理的是缺失值大于99%的特征,这是因为缺失值太多,我们即使训练出模型,模型对这一特征的认识也极少,甚至可有可无,若其带着缺失值去运算,除了效果极低外,还会有运行开销,甚至会带来不必要的误差。所以我把这些特征删去,上面输出结果中有两列是大于99%的,故删去。
droppable_features.append('PuaMode')
droppable_features.append('Census_ProcessorClass')
这两句就是把要删去的特征的名称放入列表,但我们这时还没删去,只是记录下要删去的目录。
2.2 Too skewed columns(太倾斜的列),就是说倾向某一特征值太多,更通俗的讲就是某一特征值在这个列中出现了很多次,我们的目的就是删去出现次数占全部特征值出现的总次数超过99%的特征,也就是说举个例子:在一个列中 ,有101个值,其中有100个的值都是等于1,只有一个等于0,那么我们要删去这个列,因为这种情况会导致模型相当于一直在学习同一个特征值,而对其他特征值不了解,就好像数学课有很多类题,你只学一类,那么你考试一定考不好。
pd.options.display.float_format = '{:,.4f}'.format
sk_df = pd.DataFrame([{'column': c, 'uniq': train[c].nunique(), 'skewness': train[c].value_counts(normalize=True).values[0] * 100} for c in train.columns])
sk_df = sk_df.sort_values('skewness', ascending=False)
sk_df
‘{:,.4f}’ : 保留4位小数
‘{:,100.4f}’ : 也是保留4位小数
所以我们可以看到,小数点后的数决定了保留几位小数。
value_counts(): 每个特征值出现的次数
value_counts(normalize=True):每个特征值的计数占比,默认降序排序
value_counts(normalize=True).values[0]:返回计数占比最大的特征值的计数占比
输出结果:
column skewness uniq
75 Census_IsWIMBootEnabled 100.0000 2
5 IsBeta 99.9992 2
69 Census_IsFlightsDisabled 99.9990 2
68 Census_IsFlightingInternal 99.9986 2
27 AutoSampleOptIn 99.9971 2
71 Census_ThresholdOptIn 99.9749 2
29 SMode 99.9537 2
65 Census_IsPortableOperatingSystem 99.9455 2
28 PuaMode 99.9134 2
35 Census_DeviceFamily 99.8383 3
33 UacLuaenable 99.3925 11
76 Census_IsVirtualDevice 99.2961 2
1 ProductName 98.9356 6
12 HasTpm 98.7971 2
7 IsSxsPassiveMode 98.2666 2
32 Firewall 97.8583 2
11 AVProductsEnabled 97.3984 6
6 RtpStateBitfield 97.3262 7
20 OsVer 96.7613 58
18 Platform 96.6063 4
78 Census_IsPenCapable 96.1929 2
26 IsProtected 94.5624 2
79 Census_IsAlwaysOnAlwaysConnectedCapable 94.2581 2
70 Census_FlightRing 93.6580 10
45 Census_HasOpticalDiskDrive 92.2813 2
55 Census_OSArchitecture 90.8580 3
19 Processor 90.8530 3
66 Census_GenuineStateName 88.2992 5
39 Census_ProcessorManufacturerIdentifier 88.2789 7
77 Census_IsTouchEnabled 87.4457 2
... ... ... ...
57 Census_OSBuildNumber 44.9351 165
64 Census_OSWUAutoUpdateOptionsName 44.3256 6
23 OsPlatformSubRelease 43.8887 9
21 OsBuild 43.8887 76
30 IeVerIdentifier 43.8454 303
2 EngineVersion 43.0990 70
24 OsBuildLab 41.0045 663
59 Census_OSEdition 38.8948 33
60 Census_OSSkuName 38.8934 30
62 Census_OSInstallLanguageIdentifier 35.8777 39
63 Census_OSUILocaleIdentifier 35.5414 147
48 Census_InternalPrimaryDiagonalDisplaySizeInInches 34.3398 785
42 Census_PrimaryDiskTotalCapacity 32.0408 5735
72 Census_FirmwareManufacturerIdentifier 30.8882 712
61 Census_OSInstallTypeName 29.2332 9
60 Census_OSSkuName 30 0.000000 38.893410 category
64 Census_OSWUAutoUpdateOptionsName 6 0.000000 44.325557 category
63 Census_OSUILocaleIdentifier 147 0.000000 35.541445 int16
65 Census_IsPortableOperatingSystem 2 0.000000 99.945480 int8
78 Census_IsPenCapable 2 0.000000 96.192909 int8
58 Census_OSBuildRevision 285 0.000000 15.845269 int32
66 Census_GenuineStateName 5 0.000000 88.299187 category
67 Census_ActivationChannel 6 0.000000 52.991067 category
77 Census_IsTouchEnabled 2 0.000000 87.445686 int8
70 Census_FlightRing 10 0.000000 93.657960 category
74 Census_IsSecureBootEnabled 2 0.000000 51.397710 int8
59 Census_OSEdition 33 0.000000 38.894778 category
0 MachineIdentifier 8921483 0.000000 0.000011 category
57 Census_OSBuildNumber 165 0.000000 44.935141 int16
20 OsVer 58 0.000000 96.761323 category
2 EngineVersion 70 0.000000 43.098967 category
3 AppVersion 110 0.000000 57.605042 category
4 AvSigVersion 8531 0.000000 1.146861 category
5 IsBeta 2 0.000000 99.999249 int8
7 IsSxsPassiveMode 2 0.000000 98.266622 int8
12 HasTpm 2 0.000000 98.797106 int8
13 CountryIdentifier 222 0.000000 4.451861 int16
17 LocaleEnglishNameIdentifier 252 0.000000 23.477991 int8
18 Platform 4 0.000000 96.606304 category
19 Processor 3 0.000000 90.853001 category
21 OsBuild 76 0.000000 43.888679 int16
56 Census_OSBranch 32 0.000000 44.938246 category
22 OsSuite 14 0.000000 62.328886 int16
23 OsPlatformSubRelease 9 0.000000 43.888735 category
25 SkuEdition 8 0.000000 61.809690 category
27 AutoSampleOptIn 2 0.000000 99.997108 int8
34 Census_MDC2FormFactor 13 0.000000 64.152103 category
35 Census_DeviceFamily 3 0.000000 99.838256 category
1 ProductName 6 0.000000 98.935569 category
45 Census_HasOpticalDiskDrive 2 0.000000 92.281272 int8
54 Census_OSVersion 469 0.000000 15.845202 category
55 Census_OSArchitecture 3 0.000000 90.858045 category
82 HasDetections 2 0.000000 50.020731 int8
上文中有12个是超过99%的,故而删去这一些:
droppable_features.extend(sk_df[sk_df.skewness > 99].column.tolist())
droppable_features
结果:
['PuaMode',
'Census_ProcessorClass',
'Census_IsWIMBootEnabled',
'IsBeta',
'Census_IsFlightsDisabled',
'Census_IsFlightingInternal',
'AutoSampleOptIn',
'Census_ThresholdOptIn',
'SMode',
'Census_IsPortableOperatingSystem',
'PuaMode',
'Census_DeviceFamily',
'UacLuaenable',
'Census_IsVirtualDevice']
上面就是我们要删去的目录,但我们发现有两个PuaMode,这是因为它满足我们前面所说的两个问题,而如前面所说,我们并没有删去这些值,故而同时满足前面两个问题,就会被放进目录两次,故而删去其中一个
droppable_features.remove('PuaMode')
那么接下来我们就把目录中的这些从数据集中删去:
train.drop(droppable_features, axis=1, inplace=True)
虽然前面做了数据处理,但肯定还没完,还有许多特征的特征值为空,我们接下来会对缺失值超过10%的特征进行填充,就是说,举个例子:缺失值是NaN,而我们用0值赋给它,有多少个Nan值,我们就将这些值全部变成0。然后就是对缺失值低于10%的特征进行休整,也就是删除这些特征值为NaN所在的行,记住是删除行,不是列,也就是我们只是删去它的含有NaN值的样本。那么为什么我们对缺失值超过10%的特征进行填补,而对低于10%的进行删除呢?这是因为:缺失值超过10%的特征,其中含有NaN值的行数太多,我们建一个模型,一定要有足够的数据,而缺失值超过10%的那些特征(有的可能30%,有的可能50%,甚至更多)中含有NaN值的行数加起来估计已经达到过半的样本了,甚至更多,若删去,那么对数据的保存太少,对模型训练不利,故我们只对缺失值超过10%的特征进行填补,低于10%的进行 “样本删除”。
null_counts = train.isnull().sum()
null_counts = null_counts / train.shape[0]
null_counts[null_counts > 0.1]
输出结果:
DefaultBrowsersIdentifier 0.9514
OrganizationIdentifier 0.3084
SmartScreen 0.3561
Census_InternalBatteryType 0.7105
dtype: float64
以上便是缺失值超过10%的特征,我们一个一个进行:
第一个:
train.DefaultBrowsersIdentifier.value_counts().head(5)
进行查看:
239.0000 46056
3,195.0000 42692
1,632.0000 28751
3,176.0000 24220
146.0000 20756
Name: DefaultBrowsersIdentifier, dtype: int64
填补:
train.DefaultBrowsersIdentifier.fillna(0, inplace=True)
第二个:
train.SmartScreen.value_counts()
进行查看:
RequireAdmin 4316183
ExistsNotSet 1046183
Off 186553
Warn 135483
Prompt 34533
Block 22533
off 1350
On 731
 416
 335
on 147
requireadmin 10
OFF 4
0 3
Promt 2
requireAdmin 1
Enabled 1
prompt 1
warn 1
00000000 1
 1
Name: SmartScreen, dtype: int64
填补:
trans_dict = {
'off': 'Off', '': '2', '': '1', 'on': 'On', 'requireadmin': 'RequireAdmin', 'OFF': 'Off',
'Promt': 'Prompt', 'requireAdmin': 'RequireAdmin', 'prompt': 'Prompt', 'warn': 'Warn',
'00000000': '0', '': '3', np.nan: 'NoExist'
}
train.replace({'SmartScreen': trans_dict}, inplace=True)
第三个:
train.OrganizationIdentifier.value_counts()
查看:
27.0000 4196457
18.0000 1764175
48.0000 63845
50.0000 45502
11.0000 19436
37.0000 19398
49.0000 13627
46.0000 10974
14.0000 4713
32.0000 4045
36.0000 3909
52.0000 3043
33.0000 2896
2.0000 2595
5.0000 1990
40.0000 1648
28.0000 1591
4.0000 1385
10.0000 1083
51.0000 917
20.0000 915
1.0000 893
8.0000 723
22.0000 418
39.0000 413
6.0000 412
31.0000 398
21.0000 397
47.0000 385
3.0000 331
16.0000 242
19.0000 172
26.0000 160
44.0000 150
29.0000 135
42.0000 132
7.0000 98
41.0000 77
45.0000 73
30.0000 64
43.0000 60
35.0000 32
23.0000 20
15.0000 13
25.0000 12
12.0000 7
34.0000 2
38.0000 1
17.0000 1
Name: OrganizationIdentifier, dtype: int64
填补:
train.replace({'OrganizationIdentifier': {np.nan: 0}}, inplace=True)
第四个:
pd.options.display.max_rows = 99
train.Census_InternalBatteryType.value_counts()
查看:
lion 2028256
li-i 245617
# 183998
lip 62099
liio 32635
li p 8383
li 6708
nimh 4614
real 2744
bq20 2302
pbac 2274
vbox 1454
unkn 533
lgi0 399
lipo 198
lhp0 182
4cel 170
lipp 83
ithi 79
batt 60
ram 35
bad 33
virt 33
pad0 22
lit 16
ca48 16
a132 10
ots0 9
lai0 8
ÿÿÿÿ 8
lio 5
4lio 4
lio 4
asmb 4
li-p 4
0x0b 3
lgs0 3
icp3 3
3ion 2
a140 2
h00j 2
5nm1 2
lhpo 2
a138 2
lilo 1
li-h 1
lp 1
li? 1
ion 1
pbso 1
3500 1
6ion 1
@i 1
li 1
sams 1
ip 1
8 1
#TAB# 1
l&#TAB# 1
lio 1
˙˙˙ 1
l 1
cl53 1
liÿÿ 1
pa50 1
í-i 1
÷ÿóö 1
li-l 1
h4°s 1
d 1
lgl0 1
4ion 1
0ts0 1
sail 1
p-sn 1
a130 1
2337 1
lÿÿÿ 1
Name: Census_InternalBatteryType, dtype: int64
填补:
trans_dict = {
'˙˙˙': 'unknown', 'unkn': 'unknown', np.nan: 'unknown'
}
train.replace({'Census_InternalBatteryType': trans_dict}, inplace=True)
以上就对缺失值超过10%的特征进行看填补了:
接下来我们看数据文件的数据大小:
train.shape
输出结果:
(8921483, 70)
有8921483行,70列,就是说有8921483个样本,每个样本有70个特征。
那我们接下来就对缺失值低于10%的样本进行样本删除:
train.dropna(inplace=True)
train.shape
结果:
(7667789, 70)
还剩7667789个样本。
由于MachineIdentifier这个特征对预测没有用,所以我们也删去这个特征
train.drop('MachineIdentifier', axis=1, inplace=True)
为了是数据能够用于机器学习,我们需要把一些数据的类型转化为category类型
train['SmartScreen'] = train.SmartScreen.astype('category')
train['Census_InternalBatteryType'] = train.Census_InternalBatteryType.astype('category')
cate_cols = train.select_dtypes(include='category').columns.tolist()
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
for col in cate_cols:
train[col] = le.fit_transform(train[col])
LabelEncoder()函数是用来对数据进行编号的,或者说转化为标号,毕竟机器学习是通过次数进行学习,所以两个3和两个4其实没啥区别。
之后,我们便来对运行开销进行一下缩减:
def reduce_mem_usage(df):
""" iterate through all the columns of a dataframe and modify the data type
to reduce memory usage.
"""
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
%time
train = reduce_mem_usage(train)
上面的代码是什么意思呢:举个例子,一个整数100,我们可以怎样存储呢?可以用8位(-128-127)来存储,也可以用16位,32位,64位,但怎样才是将运行开销变换成最小呢?就是8位,故而从8位开始判断,逐渐到64位,达到将每一个数用最小的位去存储。这样就降低运行开销啦。
以下是输出结果:
CPU times: user 0 ns, sys: 0 ns, total: 0 ns
Wall time: 5.48 µs
Memory usage of dataframe is 2464.34 MB
Memory usage after optimization is: 965.26 MB
Decreased by 60.8%
做完前面的工作,我们发现还是有很多特征,而且我们还可以进行优化,那就是相关处理,举个例子,两个数a和b,a增加,b也增加,a减少,b也减少,那么这两个数就有相关性,若a增减10,而b也增减10,那么a和b的相关性就很大,若一个增加100,一个只增加1,这种情况下即使有相关性也不大,我们要选择有相关性且相关性大的特征进行处理,因为相关性太大,就是说我留下a和b和留下a和留下b三种情况是一样的,就像做题,两套题都一样,我选一套就够了。所以选择相关性超过99%的特征处理
由于特征比较多,我们就每次10个来比较,最后再总体查看:
cols = train.columns.tolist()
import seaborn as sns
plt.figure(figsize=(10,10))
co_cols = cols[:10]
co_cols.append('HasDetections')
sns.heatmap(train[co_cols].corr(), cmap='RdBu_r', annot=True, center=0.0)
plt.title('Correlation between 1 ~ 10th columns')
plt.show()
结果:
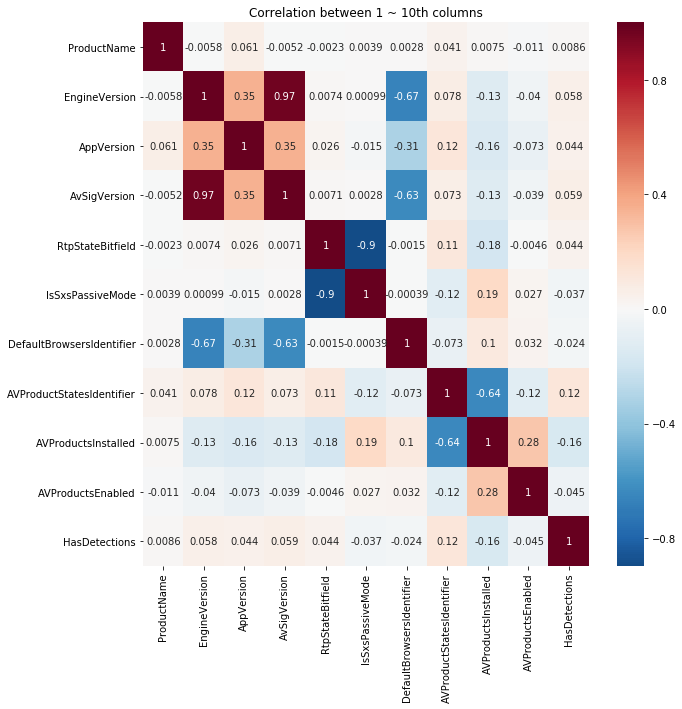
没有发现超过99%的特征
corr_remove = []
co_cols = cols[10:20]
co_cols.append('HasDetections')
plt.figure(figsize=(10,10))
sns.heatmap(train[co_cols].corr(), cmap='RdBu_r', annot=True, center=0.0)
plt.title('Correlation between 11 ~ 20th columns')
plt.show()
结果:
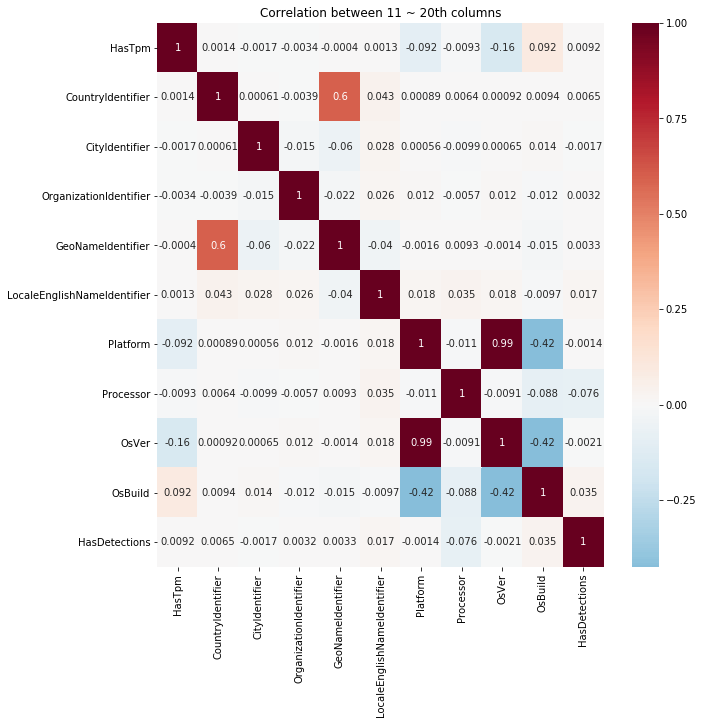
发现两个特征相关性超过99%,进行删除其中一个:
先比较那个稳定,即比较那个的出现次数比较多
print(train.Platform.nunique())
print(train.OsVer.nunique())
结果:
3
45
corr_remove.append('Platform')
放进要删除的目录,还没删哦!
这之后就是对每10个特征进行相同的处理,我这里就不进行过多显示,直接跳过:
train.drop(corr_remove, axis=1, inplace=True)
corr = train.corr()
high_corr = (corr >= 0.99).astype('uint8')
plt.figure(figsize=(15,15))
sns.heatmap(high_corr, cmap='RdBu_r', annot=True, center=0.0)
plt.show()
将目录中的特征进行删除,再进行整体查看:
结果:
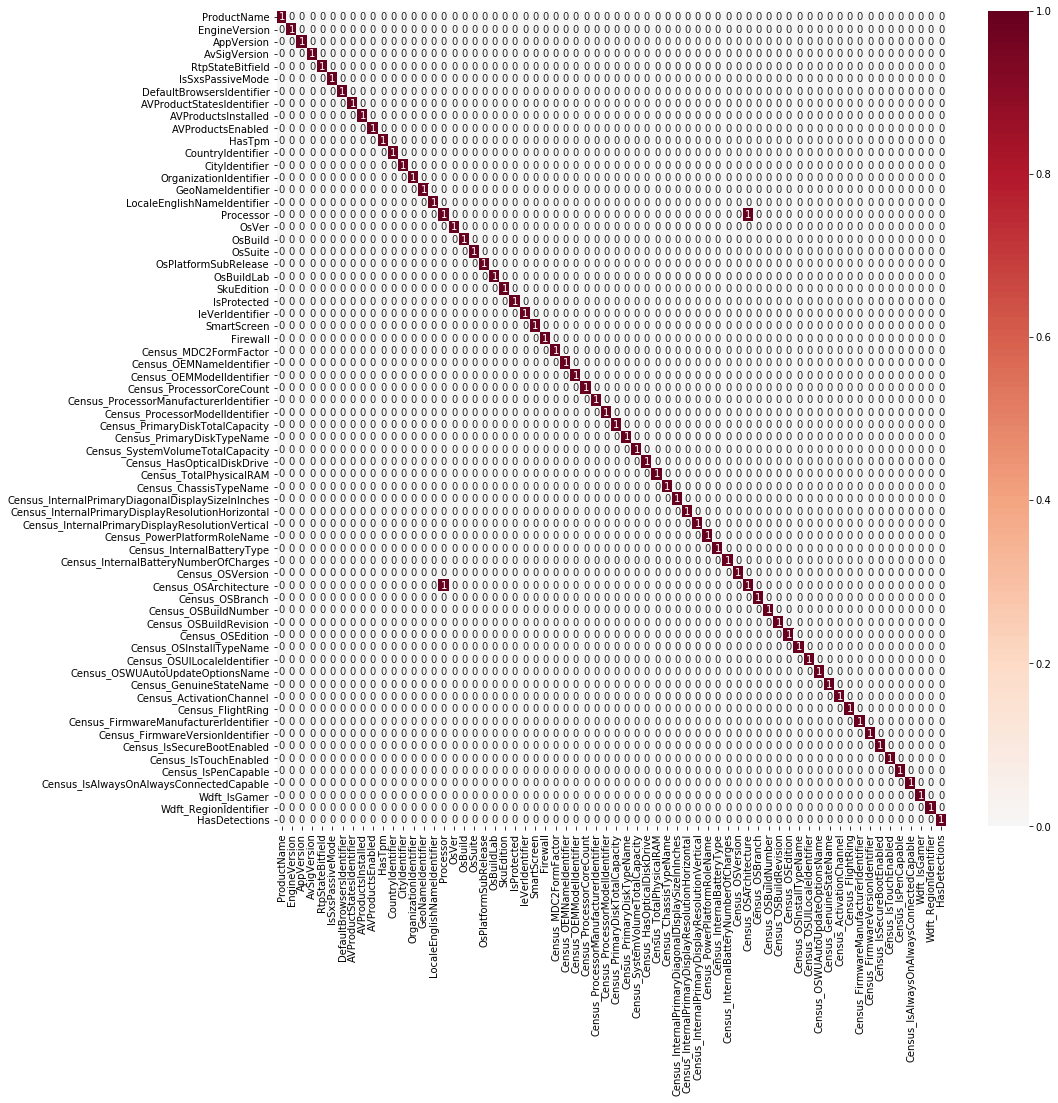
发现一个,进行删除:
print(train.Census_OSArchitecture.nunique())
print(train.Processor.nunique())
结果:
3
3
发现次数相同,进行相关性查看:
train[['Census_OSArchitecture', 'Processor', 'HasDetections']].corr()
结果:
Census_OSArchitecture Processor HasDetections
Census_OSArchitecture 1.0000 0.9951 -0.0758
Processor 0.9951 1.0000 -0.0758
HasDetections -0.0758 -0.0758 1.0000
发现相关性还是一样,那:
看你心情,哪个不爽删哪个。
最后
以上就是灵巧酒窝最近收集整理的关于Everyone Do this at the Beginning!!--kaggle数据预处理-超详细的解说的全部内容,更多相关Everyone内容请搜索靠谱客的其他文章。








发表评论 取消回复