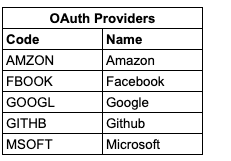
In this article, we’ll look at how we can encode (and decode) certain strings to save storage (and transmission) space, and the mathematics behind it. 在本文中,我们将研究如何编码(和解码)某些字符串以节省存储(和传输)空间以及其背后的数学原理。 This very text that you are reading now is stored and sent over the internet in a binary form in some way — zeroes and ones. But how does it get converted back and forth between binary and the text that you see? 您现在正在阅读的该文本以二进制形式以零和一的形式存储并通过Internet发送。 但是,如何在二进制和看到的文本之间来回转换呢? Every byte of binary, or in some instances a sequence of bytes, will represent a number. For instance, the number 255 can be represented by 二进制的每个字节,或者在某些情况下是字节序列,都将代表一个数字。 例如,数字255可以由二进制的 If we map every character that we may want to display/store (including spaces and newlines) to a number, and each number can be represented in binary form, then this map provides the mechanism for converting between the text that we see on screen to the binary that we store on disk. 如果我们将可能要显示/存储的每个字符(包括空格和换行符)映射到一个数字,并且每个数字都可以以二进制形式表示,则此映射提供了一种机制,可以在屏幕上看到的文本之间转换为我们存储在磁盘上的二进制文件。 There are many character encoding maps to choose from. A few examples are: 有许多字符编码映射可供选择。 一些示例是: ASCII ASCII码 Win-1252 胜利1252 UTF-16 UTF-16 but the most common character encoding used on the internet would be UTF-8. 但互联网上最常用的字符编码是UTF-8 。 I feel for anyone who has had the pleasure of dealing with files from Main Frame computers and the EBCDIC encoding. Trying to view a file stored in EBCDIC format in an application like Notepad on Windows is futile. Luckily there are other programs which allow us to determine the encoding of the file such that it can be converted to that of the operating system and viewed correctly. 对于那些喜欢处理来自主机计算机和EBCDIC编码的文件的人,我感到非常高兴。 在Windows等记事本之类的应用程序中尝试查看以EBCDIC格式存储的文件是徒劳的。 幸运的是,还有其他程序可让我们确定文件的编码,以便可以将其转换为操作系统的编码并正确查看。 In my brief experience of EBCDIC, I had to interrogate the data in an EBCDIC encoded file to make sure that the data was as per the source system. However, the developers had gone one step further and there was another complication to the raw data stored in the file: Numeric amounts were stored in Packed-Decimal format. This meant that instead of having each digit stored as text from the EBCDIC map, each group of 2 digits provided a literal 2 part hexadecimal value. 根据我对EBCDIC的简短经验,我必须在EBCDIC编码文件中查询数据,以确保数据与源系统一致。 但是,开发人员又走了一步,文件中存储的原始数据又复杂了一点:数字量以Packed-Decimal格式存储。 这意味着,不是每个数字都作为EBCDIC映射中的文本存储,而是每2个数字组提供了一个2进制的十六进制值。 e.g. the fixed-point value of +1,234.567 would be represented as 12 34 56 7C in hex. 例如,定点值+1,234.567用十六进制表示为12 34 56 7C。 The reason for doing this is to save space down at the bit/byte level. Instead of a byte per digit (and potentially another for the decimal place) if it were encoded as a string in EBCDIC (or ASCII), we just have a byte for every 2 digits; a 50% reduction in space! 这样做的原因是为了节省位/字节级别的空间。 如果它是用EBCDIC(或ASCII)编码为字符串,则不是每个数字一个字节(可能还有一个小数位),而我们每2个数字只有一个字节。 空间减少了50%! Could we use this idea of mapping data in a specific way to save space for other text data? 我们能否以特定的方式使用映射数据的想法来节省其他文本数据的空间? Let’s say we want to store the list of oauth providers and we represent that as a shortcode identifier and the name of the provider: 假设我们要存储oauth提供程序的列表,并将其表示为简码标识符和提供程序的名称: We know that the code of each provider is only ever going to be from a limited set of characters. Assuming we use ASCII or a code page where the English alphabet is used and hence each character is represented as a single byte, then we know that all of the above codes would take up 5 bytes of space in a file. In fact, if we use the 5 character limit and alpha-characters only as a rule on our data, is there anything we can do to save space when writing this data to a file or over the wire? 我们知道,每个提供程序的代码只会来自一组有限的字符。 假设我们使用ASCII或使用英文字母的代码页,因此每个字符都表示为一个字节,那么我们知道上述所有代码将在文件中占用5个字节的空间。 实际上,如果仅对数据使用5个字符限制和字母字符作为规则,那么在将此数据写入文件或通过网络传输时,我们是否可以做些节省空间的事情? Considering we will only ever look to use a combination of 26 different characters, we could attempt to encode the alphabet with a different numbering system and therefore reduce the space used to store the data. Instead of the characters A-Z being a number represented by a single byte (8 bits = 255), we can map each letter to a different number and therefore assume the code is actually a number in a different base. e.g. 考虑到我们只会使用26个不同字符的组合,因此我们可以尝试使用不同的编号系统对字母进行编码,从而减少用于存储数据的空间。 我们可以将每个字母映射到不同的数字,而不是用单个字节(8位= 255)表示的数字AZ,因此假设代码实际上是不同基数的数字。 例如 With this numbering system, we are creating a base-26 numbering system. The number 0 is represented as 使用此编号系统,我们正在创建以26为基数的编号系统。 数字0表示为 If we take our first code 如果我们使用第一个代码 Encoding all codes to a number in the same way we end up with the following: 以相同的方式将所有代码编码为数字,最终得到以下结果: We can see from the table that at most there are only about 3 bytes of information. We can confirm this in 2 ways. Firstly, the largest number in our system (using max 5 chars) would be represented by the code 从表中我们可以看到,最多只有大约3个字节的信息。 我们可以通过两种方式确认这一点。 首先,我们系统中最大的数字(最多5个字符)将由代码 Secondly, we are using a base-26 numbering system. Therefore we can use mathematics to find out our largest number: 其次,我们使用的是base-26编号系统。 因此,我们可以使用数学找出最大的数字: Seeing as the maximum number that can be represented by 3 bytes is 看到可以用3个字节表示的最大数字是 So we’ve taken a 5 byte string code and stored it as a 3 byte integer. A space saving of 40%!!!!! 因此,我们采用了5个字节的字符串代码并将其存储为3个字节的整数。 节省空间40%!!!!! Side Note: The well known Base 64 encoding does not save space. It’s encoding mechanism is completely different, requires padding and will actually increase the data size. 旁注:众所周知的Base 64编码不会节省空间。 它的编码机制完全不同,需要填充,并且实际上会增加数据大小。 In mathematical terms, we know that the largest number that can be represented in binary can be represented by: 用数学术语来说,我们知道可以用二进制表示的最大数可以表示为: Whatever character encoding mapping we use can be converted to a number that can be represented by 无论我们使用什么字符编码映射,都可以将其转换为可以表示为 Therefore, our constraint is as simple as 因此,我们的约束很简单 Being clever, and with some simple logarithm rules, we can find the maximum number of characters that can be stored for a given character mapping. 聪明一点,并通过一些简单的对数规则,我们可以找到给定字符映射可以存储的最大字符数。 As an example, if we were to take a dictionary size of 40 characters and we wanted to fit this into an 例如,如果我们要使用40个字符的字典大小,并且希望将其适合 A simple overview of an encoding algorithm (to provide a number) would be as follows 编码算法(提供数字)的简单概述如下 A simple implementation of this would be: 一个简单的实现是: The decoding of a number, back to a code string would be a little more involved. The algorithm would be as follows 将数字解码回代码字符串会涉及更多的工作。 该算法如下 The implementation would then look like this: 然后,实现将如下所示: Here’s a codesandbox demo showing a full implementation of this working with debugging values. 这是一个codeandbox演示,显示了此示例的完整实现以及调试值。 Is this of any use? Probably not. If you’re looking at data being transmitted over HTTP API’s then this will only work where the data format is binary, ala gRPC or with a content type of 这有用吗? 可能不是。 如果您正在查看通过HTTP API传输的数据,那么这仅适用于数据格式为二进制, ala gRPC或内容类型为 But it was kind of fun to look deep down into the internals of how character encoding is merely a mapping exercise and how in the past developers have looked at different ways to store simple data more efficiently. 但是,深入了解字符编码仅仅是一种映射练习的内部以及过去的开发人员如何研究可以更有效地存储简单数据的不同方式,这是一种乐趣。 We’ve taken a fleeting step towards looking at the maths of base conversion and how we might look at some basic algorithms involved in executing this encoding and decoding. 我们朝着基础转换的数学方向迈出了短暂的一步,以及如何看待执行此编码和解码所涉及的一些基本算法。 翻译自: https://medium.com/swlh/creating-custom-character-encoding-to-save-space-5cc1e53b8f34 背景 (Background)
11111111 in binary.11111111表示。 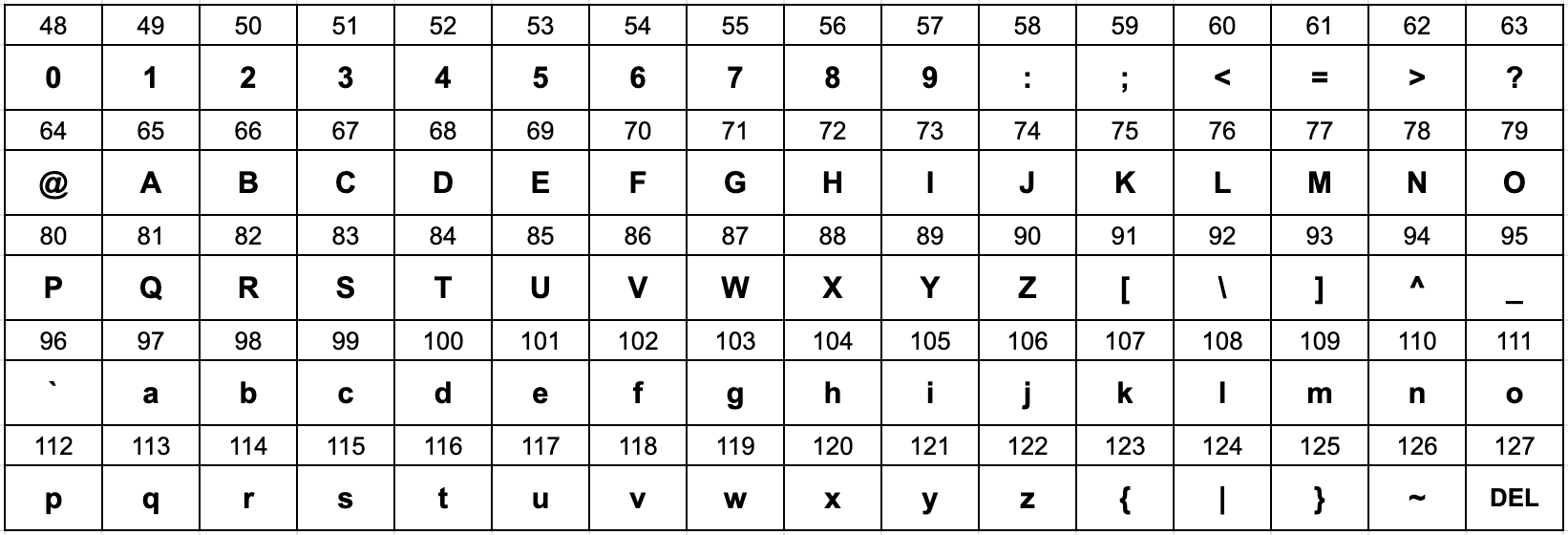

思想实验 (A thought experiment)
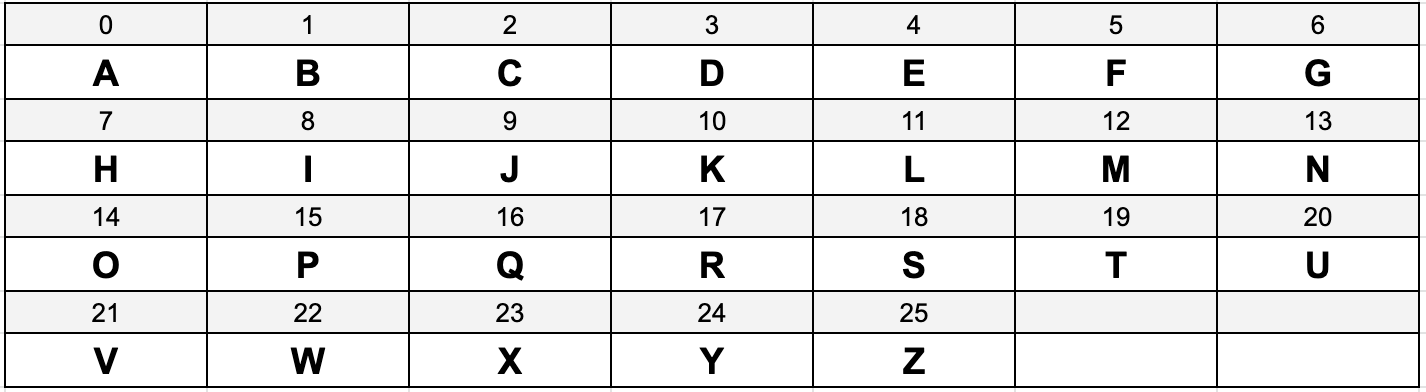
A or AAAAA, the number 25 is represented by Z or AAAAZ and therefore larger numbers like 54321 could be represented as ADCJH.A或AAAAA ,数字25表示为Z或AAAAZ ,因此,较大的数字(如54321)可以表示为ADCJH 。 AMZON we can see that this would be broken down as follows:AMZON我们可以看到它会被分解如下: A M Z O N
0 * 26^4 + 12 * 26^3 + 25 * 26^2 + 14 * 26^1 + 13 * 26^0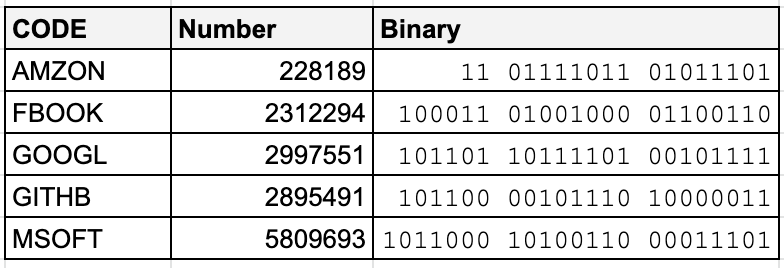
ZZZZZ. The value of this is 11881375, which is 10110101 01001011 10011111 in binary, and will use 24 bits.ZZZZZ表示。 该值是11881375,二进制值为10110101 01001011 10011111 ,将使用24位。 num = 26 ^ [num characters] − 1 = 26 ^ 5 − 1 = 11881375num = 26 ^ [num characters] − 1 = 26 ^ 5 − 1 = 11881375 2 ^ 24 — 1 = 16777215 then we are well within these limits.2 ^ 24 — 1 = 16777215那么我们就在这些限制之内。
数学 (Mathematics)


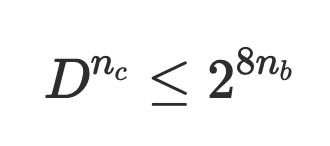
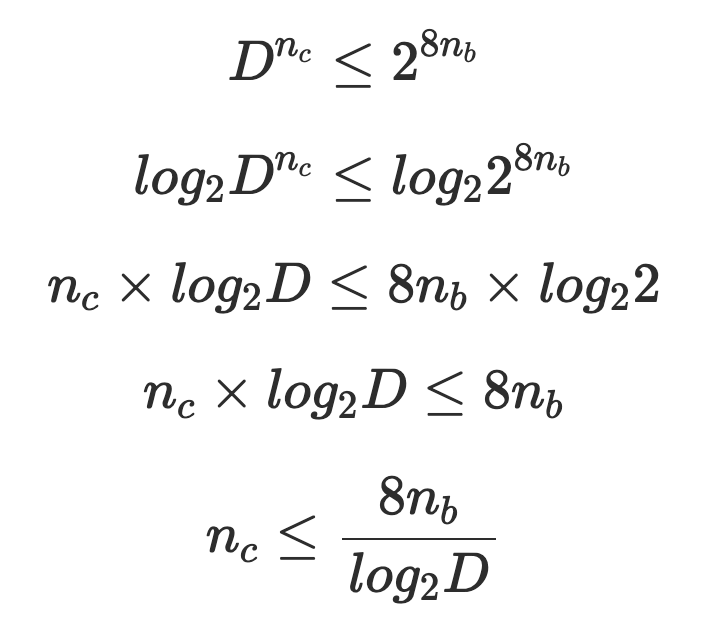
Int32 (4 bytes) we would calculate that the maximum number of characters that can be in our code will be 6:Int32 (4字节),我们将计算出代码中最多可以包含6个字符: 8 * 4 / log2(40) = 32 / 5.3219 = 6.0128 在Javascript中实现编码/解码 (Implement Encoding/Decoding in Javascript)
1. Split the code into an array of each character
2. Iterate over the array and map to the relevant number in the mapping
3. Reduce the array into a single number by multiplying each number by a decreasing power of 26.const encode = (code) => {
return code
.split("") // split into an array of each character
.map(c => c.charCodeAt(0) - 65) // map to number in mapping
.reduce((a,b,i)=>a + b * Math.pow(26, code.length - 1 - i),0)1. Start with a remainder value equal to the number provided
2. Iterate from 4 to 0 (i)
a. For each i divide the remainder by 26^i and floor to the nearest integer (n)
b. Add the character corresponding to the n + 65 to the result string
c. Take (26 ^n) away from remainderconst decode = (num) => {
let rem = 0 + Number(num);
let str = ""; for (let i = 4; i >= 0; i--) {
let n = Math.floor(rem / Math.pow(26, i));
str += String.fromCharCode(n + 65);
rem = rem - n * Math.pow(26, i);
}
return str
} 摘要 (Summary)
application/octet-stream. JSON encodes numbers as strings in transmission and so the number form would actually be larger in size than the shortcode it represents.application/octet-stream 。 JSON在传输中将数字编码为字符串,因此数字形式实际上比其表示的简码更大。
最后
以上就是端庄西牛最近收集整理的关于创建自定义字符编码以节省空间 背景 (Background) 思想实验 (A thought experiment) 数学 (Mathematics) 在Javascript中实现编码/解码 (Implement Encoding/Decoding in Javascript) 摘要 (Summary)的全部内容,更多相关创建自定义字符编码以节省空间内容请搜索靠谱客的其他文章。








发表评论 取消回复