1. 为什么需要分布式锁?
在分布式环境下,数据一致性问题一直是个难点。分布式与单机环境最大的不同在于它不是多线程而是多进程。由于多线程可以共享堆内存,因此可以简单地采取内存作为标记存储位置。而多进程可能都不在同一台物理机上,就需要将标记存储在一个所有进程都能看到的地方。
例如秒杀场景就是一个常见的多进程场景。订单服务部署了多个服务实例,如秒杀商品有 4 个,第一个用户购买 3 个,第二个用户购买 2 个,理想状态下第一个用户能购买成功,第二个用户提示购买失败,反之亦可。而实际可能出现的情况是,两个用户都得到库存为 4,第一个用户买到了 3 个,更新库存之前,第二个用户下了 2 个商品的订单,更新库存为 2,导致业务逻辑出错。
在上面的场景中,商品的库存是共享变量,面对高并发情况,需要保证对资源的访问互斥。
在单机环境中,比如 Java 语言中其实提供了很多并发处理相关的 API ,但是这些 API 在分布式场景中就无能为力了。
由于分布式系统具备多线程和多进程的特点,且分布在不同机器中,synchronized 和 lock 关键字将失去原有锁的效果,仅依赖这些语言自身提供的 API 并不能实现分布式锁的功能,因此需要我们找到其他方法实现分布式锁。
常见的锁方案如下:
- 基于数据库实现分布式锁;
- 基于
ZooKeeper实现分布式锁; - 基于缓存实现分布式锁,如
redis、etcd等;
2. 基于数据库实现分布式锁
基于数据库实现分布式锁有两种方式:
- 基于数据库表;
- 基于数据库的排他锁;
2.1 基于数据库表的增删
基于数据库表的增删是最简单的实现方式,首先创建一张锁的表,主要包含方法名、时间戳等字段。
具体使用的方法为:当需要锁住某个方法时,往该表中插入一条相关的记录。需要注意的是,方法名有唯一性约束。如果有多个请求同时提交到数据库,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行业务逻辑。执行完毕,需要删除该记录。
对于上述方案我们可以进行优化,如应用主从数据库,数据之间双向同步。一旦主库挂掉,将应用服务快速切换到从库上。除此之外还可以记录当前获得锁的机器的主机信息和线程信息,下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到,直接把锁分配给该线程,实现可重入锁。
2.2 基于数据库排他锁
还可以通过数据库的排他锁来实现分布式锁。基于 MySQL 的 InnoDB 引擎,可以使用以下方法来实现加锁操作:
public void lock(){
connection.setAutoCommit(false)
int count = 0;
while(count < 4){
try{
select * from lock where lock_name=xxx for update;
if(结果不为空){
// 代表获取到锁
return;
}
}catch(Exception e){
}
// 为空或者抛异常都表示没有获取到锁
sleep(1000);
count++;
}
throw new LockException();
}
在查询语句后面增加 for update ,数据库会在查询过程中给数据库表增加排他锁。当某条记录被加上排他锁之后,其他线程就无法再在该行记录上增加排他锁。其他没有获取到锁的线程就会阻塞在上述 select 语句上,可能出现两种结果:在超时之前获取到了锁,在超时之前仍未获取到锁。
获得排他锁的线程即可获得分布式锁,获取到锁之后,可以执行业务逻辑,执行业务后释放锁即可。
2.3 数据库分布式锁总结
上面两种方式的实现都是依赖数据库的一张表,一种是通过表中记录的存在情况确定当前是否有锁存在,另外一种是通过数据库的排他锁来实现分布式锁。
- 优点:直接借助现有的关系型数据库,简单且容易理解;
- 缺点:操作数据库需要一定的开销,性能问题以及
SQL执行超时的异常需要考虑;
3. 基于 ZooKeeper 实现分布式锁
基于 ZooKeeper 的临时节点和顺序特性可以实现分布式锁。
申请对某个方法加锁时,在 ZooKeeper 上与该方法对应的指定节点的目录下,生成一个唯一的临时有序节点。当需要获取锁时,只需要判断有序节点中该节点是否为序号最小的一个。业务逻辑执行完成释放锁,只需将这个临时节点删除。这种方式也可以避免由于服务宕机导致的锁无法释放,产生的死锁问题。
Netflix 开源了一套 ZooKeeper 客户端框架 Curator,Curator 提供的 InterProcessMutex 是分布式锁的一种实现。acquire 方法获取锁,release 方法释放锁。另外,锁释放、阻塞锁、可重入锁等问题都可以有效解决。
关于阻塞锁的实现,客户端可以通过在 ZooKeeper 中创建顺序节点,并且在节点上绑定监听器 Watch。一旦节点发生变化,ZooKeeper 会通知客户端,客户端可以检查自己创建的节点是否是当前所有节点中序号最小的,如果是就获取到锁,执行业务逻辑。
ZooKeeper 实现的分布式锁也存在一些缺陷,比如在性能上可能不如基于缓存实现的分布式锁。因为每次创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点,实现锁功能。
此外,ZooKeeper 中创建和删除节点只能通过 Leader 节点来执行,然后将数据同步到集群中的其他节点。分布式环境中难免存在网络抖动,导致客户端和 ZooKeeper 集群之间的 session 连接中断,此时 ZooKeeper 服务端以为客户端挂了,就会删除临时节点。这时其他客户端就可以获取到分布式锁了,会出现多个请求获取到了同一把锁的问题,导致业务数据不一致。
4. 基于缓存实现分布式锁
相对于基于数据库实现分布式锁的方案来说,基于缓存来实现在性能方面会表现得更好一点,存取速度会快很多,而且很多缓存是可以集群部署的,可以解决单点问题。
基于缓存的锁有如下几种: memcached、redis、etcd。下面我们主要讲解基于 etcd 实现的分布式锁。
通过 etcd 实现分布式锁,同样需要满足一致性、互斥性和可靠性等要求。etcd 中的事务 txn、lease 租约以及 watch 监听特性,能够实现上述要求的分布式锁。
4.1 整体思路
通过 etcd 的事务特性可以帮助我们实现一致性和互斥性。etcd 的事务特性,使用 IF-Then-Else 语句,IF 语言判断 etcd 服务端是否存在指定的 key,通过该 key 创建的版本号 create_revision 是否为 0 来检查 key 是否已存在,如果该 key 存在,版本号不为 0。满足 IF 条件的情况下则使用 Then 执行 put 操作,否则 Else 语句将返回抢锁失败的结果。
当然,除了使用 key 是否创建成功作为 IF 的判断依据,还可以创建前缀相同的 key,通过比较这些 key 的 revision 来判断分布式锁应该属于哪个请求。
客户端请求在获取到分布式锁后,如果发生异常,需要及时将锁释放掉,因此需要租约。我们申请分布式锁时也需要指定租约时间,超过 lease 租期时间将会自动释放锁,保证业务的可用性。
但是在执行业务逻辑时,如果客户端发起的是一个耗时的操作,在操作未完成的情况下,租约时间过期,就会导致其他请求获取到分布式锁,造成不一致。这种情况下就需要续租,即刷新租约,使得客户端和 etcd 服务端持续保持心跳。
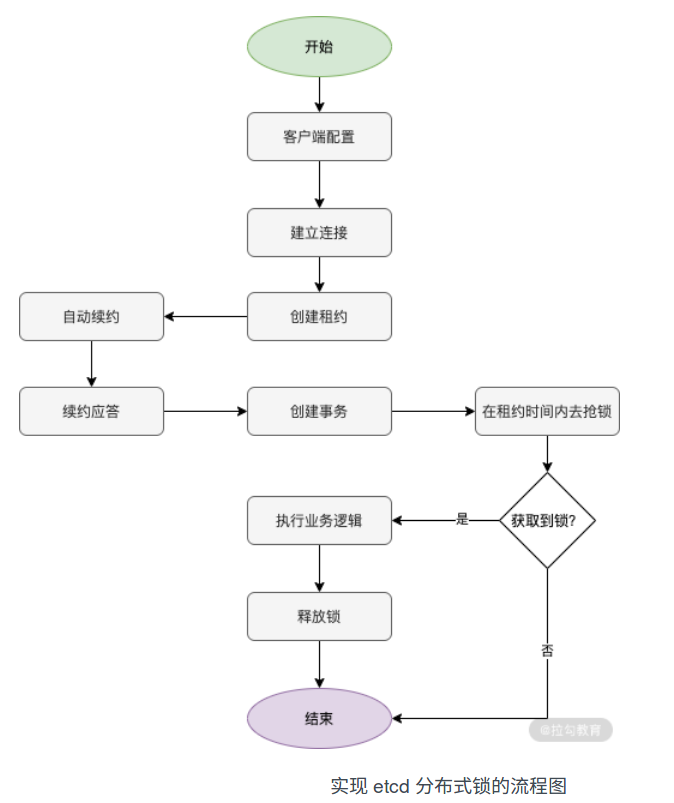
4.2 代码实现
package main
import (
"context"
"fmt"
"time"
"github.com/coreos/etcd/clientv3"
)
func main() {
config := clientv3.Config{
Endpoints: []string{"192.168.0.113:2379"}, // 集群列表
DialTimeout: 5 * time.Second,
}
// 建立一个客户端
client, err := clientv3.New(config)
if err != nil {
fmt.Println(err)
return
}
// lease实现锁自动过期:
// op操作
// txn事务: if else then
// 1, 上锁 (创建租约, 自动续租, 拿着租约去抢占一个key)
lease := clientv3.NewLease(client)
// 申请一个5秒的租约
leaseGrantResp, err := lease.Grant(context.TODO(), 5)
if err != nil {
fmt.Println(err)
return
}
// 拿到租约的ID
leaseId := leaseGrantResp.ID
// 准备一个用于取消自动续租的context
ctx, cancelFunc := context.WithCancel(context.TODO())
// 确保函数退出后, 自动续租会停止
defer cancelFunc()
defer lease.Revoke(context.TODO(), leaseId)
// 5秒后会取消自动续租
keepRespChan, err := lease.KeepAlive(ctx, leaseId)
if err != nil {
fmt.Println(err)
return
}
// 处理续约应答的协程
go func() {
for {
select {
case keepResp := <-keepRespChan:
if keepResp == nil {
fmt.Println("租约已经失效了")
goto END
} else { // 每秒会续租一次, 所以就会受到一次应答
fmt.Println("收到自动续租应答:", keepResp.ID)
}
}
}
END:
}()
// if 不存在key, then 设置它, else 抢锁失败
kv := clientv3.NewKV(client)
// 创建事务
txn := kv.Txn(context.TODO())
// 定义事务
// 如果key不存在
txn.If(clientv3.Compare(clientv3.CreateRevision("/demo/A/B1"), "=", 0)).
Then(clientv3.OpPut("/demo/A/B1", "xxx", clientv3.WithLease(leaseId))).
Else(clientv3.OpGet("/demo/A/B1")) // 否则抢锁失败
// 提交事务
txnResp, err := txn.Commit()
if err != nil {
fmt.Println(err)
return // 没有问题
}
// 判断是否抢到了锁
if !txnResp.Succeeded {
fmt.Println("锁被占用:", string(
txnResp.Responses[0].GetResponseRange().Kvs[0].Value))
return
}
// 2, 处理业务
fmt.Println("处理任务")
time.Sleep(5 * time.Second)
// 3, 释放锁(取消自动续租, 释放租约)
// defer 会把租约释放掉, 关联的KV就被删除了
}
最后
以上就是壮观龙猫最近收集整理的关于etcd 笔记(08)— 基于 etcd 实现分布式锁1. 为什么需要分布式锁?2. 基于数据库实现分布式锁3. 基于 ZooKeeper 实现分布式锁4. 基于缓存实现分布式锁的全部内容,更多相关etcd内容请搜索靠谱客的其他文章。






![[etcd] 使用 Txn 一次性插入多个语句](https://www.shuijiaxian.com/files_image/reation/bcimg22.png)

发表评论 取消回复