第七章 使用zmq高级框架
·如何安全地从创意过渡到能工作的原型(MOPED模式)
·将的数据作为zmq消息序列化的不同方式
·如何用代码生成二进制序列化的编解码器
·如何使用GSL工具来建立自定义的代码生成器
·如何撰写和许可一个协议规范
·如何在zmq上进行可快速重新启动的文件传输
·如何实现基于信用的流量控制
·如何将协议的服务器和客户端构建为状态机
·如何制作一个在zmq之上的安全协议
·一个大型的文件发布系统(FileMQ)
MOPED的目标是定义一个过程,通过它可以取得针对一个新的分布式应用程序的粗略用例。使用MOPED,通过专注于合同而不是实现,就避免了过早优化的风险。通过短的基于测试的迭代来驱动设计过程,可以在添加更多功能之前对已有什么作品更加肯定。
将其分布五个具体步骤:
1.内部化zmq语义。
2.描绘一个粗略的架构。
3.决定合同。
4.编写一个最小的端到端解决方案。
5.解决一个问题,然后重复。
1.1 第一步:内部化zmq语义
学习和消化套接字模式以及它们的工作方式,学习一门语言的唯一方法是使用它。(增加代码量)
1.2 第二步:描绘一个粗略的架构
隔离各个层,可以廉价地替换整个层。选择所要解决的核心问题,忽略任何不必要的问题:以后在添加它。为了简约化,让架构能随时间的推移渐趋完整和逼真:例如,添加多个工人、增加客户端和API,处理故障等等。
1.3 第三步:决定合同
两种类型的分布式系统合同:
·针对客户端应用程序的API,API必须尽量绝对简单、一致和为人熟知。
·连接部件的协议(一个简单的技巧)称为“unprotocols”(反协议)。
1.4 第四步:编写一个最小的端到端解决方案
若希望把代码编写出来时能够对其进行测试,官方意思是编写一个最小的骨架系统应用程序对其进行测试。目标是让最简单的测试案例能够工作,没有任何多余的功能。在要做的事情列表中,砍掉一切可以砍掉的任务。可以随时添加功能这是比较容易的,但目标是将整体规模保持在最小值。
1.5 第五步:解决一个问题然后重复
可以开始解决有形的问题,而不是增加功能。编写清楚说明问题的议题,并为每个议题提出解决方案。当设计API时要记住命名标准、一致性和行为。用简单的文字写下这些内容有助于保持它们的清晰。从这里对架构和代码的每一处更改都可以通过运行测试案例来验证,如果它不能正常工作则进行修改,如此往复,直到它可以正常工作为止。
这样就可以遍历整个周期(根据需要扩展测试案例、修正API、更新协议、扩展代码),每次选取其中一个问题并单独测试其解决方案。
2 协议
zmq提供了成功的协议抽象层,它使用“通过随机传输进行多部分消息传递”的工作方式。因为zmq默默地处理组帧、连接和路由,所以在zmq之上编写完整的协议规范非常容易,已经在第四章和第五章展示了如何做到这一点。
2.2 合同是艰难的
编写合同,也许是大规模架构中最困难的部分。使用unprotocol能尽可能多地消除不必要的摩擦。但剩下的仍然是需要解决的很难的一系列问题。好的合同无论是一个APl、协议或租赁协议必须简单、明确、技术上可靠,同时易于执行。
编写协议总结:
·从简单开始,并逐步开发的需求。不去解决还没有遇到的问题。
·使用非常明确和一贯的语言。协议往往分解成命令和字段为这些实体使用清晰而简短的名称。
·尽量避免发明概念。从现有的规范重用一些东西就可以了。
·不做不能证明有迫切需要的任何东西。的规范能解决问题,它不提供功能要为确认的每个问题做出最简单可行的解决方案。
·在构建它的同时实现的协议,以便了解每个选择的技术后果。使用一种使得它很难实现的语言(如C),而不是一种使它很容易实现的语言(如Python)。
·在构建它的同时测试的规范。针对一个规范的最好的反馈是在别人不具备的头脑中的假设和知识时,试图实现它。
·快速、一致地交叉测试,用别人的客户端连接的服务器反之亦然。
·准备把它抛出来,并根据需要随时重新启动。要对这一点做出规划,举例来说,通过对架构进行分层以便可以保留一个API,但改变底层协议。
·只使用独立于编程语言和操作系统的结构。
·分层解决大问题,使得每一层都是独立的规范。谨防创建庞大的整体协议。考虑如何重用每一层。思考不同的团队如何可以在每一层构建竞争性的规范。
最重要的是把它写下来。代码不是一种规范。通过写下一个规范,将能够发现灰色地带这些东西都是不可能在代码中看到的。
使用zmq的一种不太明显的好处是,它减少了编写一个协议规范大约90%以上的必要努力,因为它已经处理了组帧、路由、排队,等等。这意味着可以快速尝试,低成本地犯错,从而迅速学习。
·封面部分:带有写在一行中的摘要、规范的URL、正式的名称、版本、负责人。
·正文的许可证:对于公共规范是绝对需要的。
·变更过程:怎么解决规范中的问题?
·语言的使用:必须、可以、应该等,具有对RFC2119的引用。·成熟度指标:这是一个实验、草稿、稳定、遗产,还是已退休的版本?
·协议目标:它试图解决什么问题?
·正式语法:防止由于文本的不同解释导致的争论。
·技术说明:每个消息的语义、错误处理等。
·安全讨论:明确的,协议的安全程度。·参考文献:对其他文件、协议等的引用。
以下是有关协议的一些关键点:
·只要过程是开放的,就不需要一个委员会:只是做干净、简单的设计,确保任何人都可以自由地改进它们。
·如果使用现有的许可证,就不会有法律的后顾之忧。建议公开规范使用GPLv3。
·形式是有价值的。也就是说,学会写正式的语法,如ABNF(增广巴科斯-诺尔范式)并用它来完全记录的信息。
·使用类似Digistan的COSS的一种市场驱动的生命周期过程,以使人们当他们成熟(或不成熟)时,正确地把握的规范。
当实现一个GPLv3的规范时,它们可以按喜欢的任何方式来许可。但可以肯定两件事情。首先,该规范将永远不会被纳入和扩展为专有的形式。本规范的任何派生形式也必须是GPLv3的。第二,曾经实现或使用这个协议的人永远不会对它涵盖的任何东西发动专利攻击。
官方文档表示最喜欢的语法是由RFC2234定义的ABNF,因为它可能是用于定义双向通信协议的最简单和最广泛使用的正式语言。大多数IETF(互联网工程任务组)规范都使用ABNF,这是一个值得合作的好伙伴。
给出一个编写ABNF的速成教程。把语法编写成规则。每个规则的形式为“名称=元素”。一个元素也可以是其他规则(在下面定义为另一规则的东西),或预先定义的“终端”(如CRLF,八位字节),或一个数字。RFC中列出了所有的终端。要定义可选元素,用“元素/元素”的形式。要定义重复,用“*”(请参考RFC,因为它不直观)。要对元素分组,则使用括号。
这是一个称为NOM的协议的ABNF:
nom-protocol = open-peering *use-peering
open-peering = C:OHAI ( S:OHAI-OK / S:WTF )
use-peering = C:ICANHAZ
/ S:CHEEZBURGER
/ C:HUGZ S:HUGZ-OK
/ S:HUGZ C:HUGZ-OK
用传统的客户端/服务器用例来解释。客户端连接到服务器并进行身份验证。然后,它会要求得到一些资源。服务器做出回应然后开始发送数据返回给客户端。最终客户端断开连接或服务器完成,对话就结束了。
在设计这些消息之前对控制对话和数据流加以比较:
·控制对话持续时间短,涉及非常少的信息。数据流可能会持续数小时或数天,并涉及数十亿个消息。
·在控制对话中会发生所有“正常”的错误,例如,未通过身份验证,没有找到,需要付费,审查,等等。数据流过程中所发生的任何错误都是例外(磁盘已满,服务器崩溃)。
·添加更多的选项或参数等的时候,控制对话里的东西会随着时间的推移而改变。数据流几乎不应随时间而改变,因为一个资源的语义在一段时间内是相当恒定的。
·控制对话本质上是一个同步的请求-应答对话。数据流基本上是单向的异步流。
这些差异是重要的。因此当谈论性能时它仅适用于数据流。将一次性控制对话设计为快速的。当谈论序列化的成本时,这仅适用于数据流。对控制流进行编码/解码的成本可能是巨大的,而在许多情况下,它不会改变任何事情。因此利用廉价的方式对控制编码,并且利用讨厌的方式对数据流编码。
廉价方式本质上是同步、详细、描述性和灵活的。一个廉价的消息充满了可以针对每个应用程序改变的丰富的信息。设计目标是让这些信息易于编码和解析,对于实验或增长易于扩展,并且针对变化非常健壮,同时向前和向后兼容。协议的廉价部分看起来像这样:
·它对数据使用简单的自描述的结构化编码,无论是XML、JSON、HTTP式的标题,或者是一些其他的编码。任何编码方式都是好的,只要的目标语言对它有标准简单的解析器。
·它采用的是直白的请求-应答模型,其中每个请求都有一个成功/失败的应答。这使得它容易编写正确的廉价对话客户端和服务器。
·它不会尝试快速,甚至连轻微的尝试都没有。当做一些只有一次性或每个会话几次的事情时,性能是无所谓的。
廉价方式的解析器是从架子上取下来后就将数据丢给它的东西。它不应该崩溃,应该不会出现内存泄漏,应该高度宽容,并且应该是比较易用的。这就行了。
但是讨厌方式本质上是异步、简洁、沉默和不灵活的。一个讨厌方式的消息中携带几乎从不改变的最精简的信息。设计目标是让这些信息得到超快的解析,甚至可能无法扩展和试验。理想的讨厌模式看起来像这样:
·它对数据使用一个手工优化的二进制布局,其中每个二进制位都是精心设计的。
·它采用纯异步模型,其中一个或两个对等节点发送数据而无须确认。
·它不会尝试对人友善甚至连轻微的尝试都没有。当正在做每秒执行数百万次的东西时性能是一切。
讨厌方式的解析器是手工编写的,它单独和精确地写入或读取二进制位、字节、字和整数。它拒绝任何它不喜欢的东西,根本不执行内存分配,永不崩溃。
廉价或讨厌不是一个普遍的模式不是所有的协议都具有这种二分法。此外,如何使用廉价或讨厌的方式将取决于的具体情况。在某些情况下它可以是一个单独的协议的两个部分。在其他情况下它可以是一个层叠在另一个之上的两个协议。
使用廉价方式或讨厌方式做错误处理相当简单。它具有两种命令和两种引发错误信号的办法:
1)同步控制命令
错误是正常的:每个请求都有一个响应,要么是OK,要么是错误响应。
2)异步数据命令
错误是异常的:坏的命令要么被悄悄丢弃,要么导致整个连接被关闭。
区分几种错误通常是很好的,但要始终使它保持最精简,并只添加所需要的东西。。
3 序列化数据
3.1 zmq组帧
用于zmq应用程序的最简单、最广泛使用的序列化格式是zmq自己的多部分组帧。
例如,下面是管家协议定义请求的方式:
第0帧:空帧
第1帧:“MDPW01“(6个字节,相当于MDP/工人V0.1)
第2帧:0X02(一个字节,相当于REQUEST)
第3帧:客户端地址(封包栈)
第4帧:空(零字节,封包分隔符)
第5帧以上:请求正文(不透明的二进制码)
在代码中读取和写入这些是很容易的。但是这是控制流的一个经典例子(整个MDP是一个经典的例子,因为它是一个同步交互的请求-应答协议)。当改善MDP的第二个版本时必须改变这种组帧。向后兼容性是很难的,但将zmq组帧用于控制流并没有好处。下面是官方意见,应该怎么设计这个协议。它分解成一个廉价的部分和一个讨厌的部分,并且它使用zmq组帧来区分这些:
第0帧:“MDP/2.0"的协议名称和版本
第1帧:命令标头
第2帧:命令正文
期望在各种中介(客户端APl、代理以及工人APl)中解析命令标头,并将命令正文体原封不动地从一个应用程序传递到另一个应用程序。
3.2 序列化语言
各种序列化语言都有自己的风格。XML在流行的时候曾经是大型的,然后陷入了“企业信息架构师”之手,从那以后它就不再有活力了,今天的XML是“小型、优雅的语言试图逃脱的某处困境”的缩影。
尽管如此XML仍是比它的前辈更好的方法。因此序列化语言的历史似乎是一个逐渐显现理智的过程, JSON从JavaScript的世界杀出来。JSON只是表达得像JavaScript源代码的最精简的XML。
这是在Cheap协议中使用JSON的简单示例:
"protocol": {
"name": "MTL",
"version": 1
},
"virtual-host": "test-env"
XML中的数据将是相同的(XML迫使发明单个顶级实体):
<command>
<protocol name = "MTL" version = "1" />
<virtual-host>test-env</virtual-host>
</command>
这里使用的是普通的HTTP样式的标头:
Protocol: MTL/1.0
Virtual-host: test-env
这些都是等价的,只要不针对验证解析器、模式走极端。一种廉价方式的序列化语言所提供自由实验的空(忽略任何不认识的元素/属性/标头),并且容易编写通用的解析器,例如将一个命令转换到一个散列表或反向转换。
但是这不是完美的,虽然现代的脚本语言能足够轻松地支持JSON和XML,但旧的语言不能。如果使用XML或JSON,就产生了不寻常的依赖。这也是一个有点像在C语言中处理树形结构数据时的痛苦。
所以可以根据的目标语言驱动的选择,如果的环境是一种脚本语言那么去用JSON。如果的目标是建立更广泛的系统中使用的协议,那就让事情对C语言开发者保持简单,并坚持采用HTTP风格的标头。
3.3 序列化库
这就像JSON既快速又小巧。MessagePack序列化库是一种高效的二进制序列化格式。它允许将数据在类似JSON的多种语言之间交换,但它的速度更快、更小巧。
这是使用MessagePack接口定义语言(IDL)描述典型消息的方式:
message Person {
1: string surname
2: string firstname
3: optional string email
}
现在,使用Google协议的同一条消息将缓冲IDL:
message Person {
required string surname = 1;
required string firstname = 2;
optional string email = 3;
}
它可以工作但是在大多数实际情况下,以手工编写或机械生成的适当规范为后盾的序列化语言几乎不会带来什么好处。将要付出的代价是一个额外的依赖性而且很可能会比使用Cheap或Nasty时的整体性能更差。
3.4 手写的二进制序列化
当关心序列化的速度和/或结果的大小(通常这些是相互矛盾的)时,需要手写的二进制序列化。
编写一个高效讨厌的编码器/解码器(CODEC)的基本流程是:
·构建有代表性的数据集和测试应用程序,它们可以对编解码器进行压力测试。
·编写编解码器的第一个哑巴版本。
·测试、测量、改进和重复,直到用完了时间和/或金钱。。
下面是一些用来改善编解码器的技术:
·使用剖析器。原因很简单,没有办法知道的代码在做什么,除非已经剖析出它的函数执行次数和每个函数的CPU开销。
·消除内存分配。在现代的Linux内核中堆是非常快的,但它仍然是最简陋的编解码器的瓶颈。在较旧版本的内核中堆可能会非常慢,需要在代码中尽可能使用局部变量(栈)来取代堆。
·在不同的平台上用不同的编译器和编译器选项测试。除了堆之外还有许多其他的差异。
·使用状态来更好地压缩。如果担心编解码器的性能那么几乎肯定是将相同类型的数据发送了很多次。数据实例之间将有冗余。可以检测这些冗余并用它来压缩。
·了解的数据。最好的压缩技术(在紧凑性的CPU的成本方面)需要知道数据的相关信息。例如,用于压缩一个单词列表、视频和股票市场数据流的技术都不同。
·准备好打破规则。真的需要用大端网络字节顺序对整数编码吗?×86和ARM占了几乎所有现代的CPU的数量,但它们使用小端字节顺序(ARM实际上是双端的,但Android与Windows和iOS一样,是小端的)。
3.5 代码生成
所有这些都将从代码生成中受益,但是没有通用模型。因此诀窍是根据需要设计自己的模型,然后使代码生成器成为该模型的廉价编译器。
编写GSL模型时可以使用任何喜欢的语义,换句话说可以当场发明特定领域的语言。这里将发明一对夫妇-看看是否能猜出它们代表什么:
slideshow
name = Cookery level 3
page
title = French Cuisine
item = Overview
item = The historical cuisine
item = The nouvelle cuisine
item = Why the French live longer
page
title = Overview
item = Soups and salads
item = Le plat principal
item = Béchamel and other sauces
item = Pastries, cakes, and quiches
item = Soufflé: cheese to strawberry
还有这个:
table
name = person
column
name = firstname
type = string
column
name = lastname
type = string
column
name = rating
type = integer
可以将第一段汇编成演示文稿。第二段可以编译成SQL以创建和使用数据库表。因此对于本练习模型由“类”组成,这些“类”包含“消息”,这些“消息”包含各种类型的“字段”。这是故意设计成熟悉样子的。这是MDP客户端协议:
<class name = "mdp_client">
MDP/Client
<header>
<field name = "empty" type = "string" value = ""
>Empty frame</field>
<field name = "protocol" type = "string" value = "MDPC01"
>Protocol identifier</field>
</header>
<message name = "request">
Client request to broker
<field name = "service" type = "string">Service name</field>
<field name = "body" type = "frame">Request body</field>
</message>
<message name = "reply">
Response back to client
<field name = "service" type = "string">Service name</field>
<field name = "body" type = "frame">Response body</field>
</message>
</class>
这是MDP工作程序协议:
<class name = "mdp_worker">
MDP/Worker
<header>
<field name = "empty" type = "string" value = ""
>Empty frame</field>
<field name = "protocol" type = "string" value = "MDPW01"
>Protocol identifier</field>
<field name = "id" type = "octet">Message identifier</field>
</header>
<message name = "ready" id = "1">
Worker tells broker it is ready
<field name = "service" type = "string">Service name</field>
</message>
<message name = "request" id = "2">
Client request to broker
<field name = "client" type = "frame">Client address</field>
<field name = "body" type = "frame">Request body</field>
</message>
<message name = "reply" id = "3">
Worker returns reply to broker
<field name = "client" type = "frame">Client address</field>
<field name = "body" type = "frame">Request body</field>
</message>
<message name = "hearbeat" id = "4">
Either peer tells the other it's still alive
</message>
<message name = "disconnect" id = "5">
Either peer tells other the party is over
</message>
</class>
GSL使用XML作为其建模语言。XML的声誉很差,它被太多的企业下水道所吸引,难以闻到香甜,但是只要保持简单,它就会带来一些积极的影响。编写项目和属性的自描述层次结构的任何方法都是可行的。
现在这里是用GSL编写的简短IDL生成器,它将协议模型转变为文档:
.# Trivial IDL generator (specs.gsl)
.#
.output "$(class.name).md"
## The $(string.trim (class.?''):left) Protocol
.for message
. frames = count (class->header.field) + count (field)
A $(message.NAME) command consists of a multipart message of $(frames)
frames:
. for class->header.field
. if name = "id"
* Frame $(item ()): 0x$(message.id:%02x) (1 byte, $(message.NAME))
. else
* Frame $(item ()): "$(value:)" ($(string.length ("$(value)"))
bytes, $(field.:))
. endif
. endfor
. index = count (class->header.field) + 1
. for field
* Frame $(index): $(field.?'')
. if type = "string"
(printable string)
. elsif type = "frame"
(opaque binary)
. index += 1
. else
. echo "E: unknown field type: $(type)"
. endif
. index += 1
. endfor
.endfor
XML模型和此脚本在子目录examples / models中。为了进行代码生成给出以下命令:
gsl -script:specs mdp_client.xml mdp_worker.xml
这是为工作程序协议获得的Markdown文本:
## The MDP/Worker Protocol
A READY command consists of a multipart message of 4 frames:
* Frame 1: "" (0 bytes, Empty frame)
* Frame 2: "MDPW01" (6 bytes, Protocol identifier)
* Frame 3: 0x01 (1 byte, READY)
* Frame 4: Service name (printable string)
A REQUEST command consists of a multipart message of 5 frames:
* Frame 1: "" (0 bytes, Empty frame)
* Frame 2: "MDPW01" (6 bytes, Protocol identifier)
* Frame 3: 0x02 (1 byte, REQUEST)
* Frame 4: Client address (opaque binary)
* Frame 6: Request body (opaque binary)
A REPLY command consists of a multipart message of 5 frames:
* Frame 1: "" (0 bytes, Empty frame)
* Frame 2: "MDPW01" (6 bytes, Protocol identifier)
* Frame 3: 0x03 (1 byte, REPLY)
* Frame 4: Client address (opaque binary)
* Frame 6: Request body (opaque binary)
A HEARBEAT command consists of a multipart message of 3 frames:
* Frame 1: "" (0 bytes, Empty frame)
* Frame 2: "MDPW01" (6 bytes, Protocol identifier)
* Frame 3: 0x04 (1 byte, HEARBEAT)
A DISCONNECT command consists of a multipart message of 3 frames:
* Frame 1: "" (0 bytes, Empty frame)
* Frame 2: "MDPW01" (6 bytes, Protocol identifier)
* Frame 3: 0x05 (1 byte, DISCONNECT)
这接近于原始规范中手工编写的内容。现在如果已经克隆了zguide存储库,并且正在查看examples / models中的代码,则可以生成MDP客户端和辅助编解码器。将相同的两个模型传递给不同的代码生成器:
gsl -script:codec_c mdp_client.xml mdp_worker.xml
这给了mdp_client和mdp_worker类。实际上MDP非常简单,以至于编写代码生成器几乎不值得。当想要更改协议时(从独立的Majordomo项目开始),就可以获利。修改协议,运行命令,然后弹出更完美的代码。
该codec_c.gsl代码生成不算短,但所产生的编解码器比手写代码原本放在一起的管家要好得多。例如,手写代码没有错误检查,如果将其传递给伪造的消息它将死掉。
不要发明概念。设计人员的任务是消除问题,而不是添加功能。
首先将阐述面向模型的代码生成的优点:
可以创建映射到现实世界的近乎完美的抽象。因此协议模型将100%映射到Majordomo的“真实世界”。没有自由调整和更改模型的自由,这将是不可能的。
可以快速,廉价地开发这些完美的模型。
可以生成任何文本输出。从单个模型可以创建文档,任何语言的代码,测试工具-从字面上可以想到的任何输出。
可以生成完美的输出,因为将代码生成器提高到所需的任何级别都是很便宜的。
将获得一个结合了规范和语义的单一来源。
可以利用规模较小的团队。
缺点:
将工具依赖项添加到项目中。
可能会无所适从,为纯粹的创建模型而创建模型。
对新手不友好。
可能会给别人一个很大的借口,不要投资项目。
如果确实使用GSL并希望围绕工作创建开放的社区,这是的建议:
仅在可能会手工编写繁琐的代码的地方使用它。
设计人们期望看到的自然模型。
首先手动编写代码,以便知道生成什么。
不要过度使用。把事情简单化!
逐步引入一个项目。
将生成的代码放入存储库。
已经在围绕Zerzmq的一些项目中使用GSL。例如高级C绑定Czmq使用GSL生成套接字选项类(zsockopt)。
4 传输文件
“如何发送文件?”是zmq邮件列表中一个常见的问题。zmq在发送事件和任务方面是预制得很不错的,但它不擅长发送文件。
如果建立了一个适当的文件服务器,就会发现简单地将大量数据发送到许多客户端会产生下面这种情况,在技术的说法下喜欢把它叫作“由于所有可用堆内存被一个设计得糟糕的应用程序耗尽而导致的服务器崩溃”。一个适当的文件传输协议,需要注意内存的使用。
将正确地逐步解决这些问题,这应该有希望产生一个在zmq上运行良好和正确的文件传输协议。首先,用随机数据产生1GB的测试文件:
dd if=/dev/urandom of=testdata bs=1M count=1024
当有很多客户端同时请求同一个文件的时候,这个文件大得足以造成麻烦,并在许多机器上,无论如何,1GB的内存都会因为太大了而无法分配成功。作为基本参考,让衡量将此文件从磁盘复制到磁盘需要多长时间。这将知道文件传输协议额外增加了多少(包括网络开销):
$ time cp testdata testdata2
real 0m7.143s
user 0m0.012s
sys 0m1.188s
预计有上下25%的波动。
本示例显示了代码初稿,其中客户端请求测试数据,而服务器只是把它当作一系列的消息一气呵成地发送,其中每个消息各执一个“块”。
# File Transfer model #1
#
# In which the server sends the entire file to the client in
# large chunks with no attempt at flow control.
from __future__ import print_function
from threading import Thread
import zmq
from zhelpers import socket_set_hwm, zpipe
CHUNK_SIZE = 250000
def client_thread(ctx, pipe):
dealer = ctx.socket(zmq.DEALER)
dealer.connect("tcp://127.0.0.1:6000")
dealer.send(b"fetch")
total = 0 # Total bytes received
chunks = 0 # Total chunks received
while True:
try:
chunk = dealer.recv()
except zmq.zmqError as e:
if e.errno == zmq.ETERM:
return # shutting down, quit
else:
raise
chunks += 1
size = len(chunk)
total += size
if size == 0:
break # whole file received
print ("%i chunks received, %i bytes" % (chunks, total))
pipe.send(b"OK")
# File server thread
# The server thread reads the file from disk in chunks, and sends
# each chunk to the client as a separate message. We only have one
# test file, so open that once and then serve it out as needed:
def server_thread(ctx):
file = open("testdata", "rb")
router = ctx.socket(zmq.ROUTER)
# Default HWM is 1000, which will drop messages here
# since we send more than 1,000 chunks of test data,
# so set an infinite HWM as a simple, stupid solution:
socket_set_hwm(router, 0)
router.bind("tcp://*:6000")
while True:
# First frame in each message is the sender identity
# Second frame is "fetch" command
try:
identity, command = router.recv_multipart()
except zmq.zmqError as e:
if e.errno == zmq.ETERM:
return # shutting down, quit
else:
raise
assert command == b"fetch"
while True:
data = file.read(CHUNK_SIZE)
router.send_multipart([identity, data])
if not data:
break
# File main thread
# The main task starts the client and server threads; it's easier
# to test this as a single process with threads, than as multiple
# processes:
def main():
# Start child threads
ctx = zmq.Context()
a,b = zpipe(ctx)
client = Thread(target=client_thread, args=(ctx, b))
server = Thread(target=server_thread, args=(ctx,))
client.start()
server.start()
# loop until client tells us it's done
try:
print (a.recv())
except KeyboardInterrupt:
pass
del a,b
ctx.term()
if __name__ == '__main__':
main()
遇到了一个问题:如果发送过多的数据到ROUTER套接字很容易就会溢出。简单而愚蠢的解决办法是把一个无限的高水位标记放在套接字中。但因为现在已经失去防止耗尽服务器内存的保护措施。然而,如果没有一个无限的HWM,又可能会丢失大量的文件块。
若把HWM设置为1000(在zmqv3.x版本是默认的),然后将块大小减小为100K,所以一次传送10K个块。运行测试会看到它永远都不会执行完成。因为zmqsocket()手册页写道,对于ROUTER套接字:“zmq_HWM选项的操作:删除”。
必须预先控制服务器发送的数据量。发送超过网络处理能力的数据量是没有意义的。尝试一次发送一个块。在这个版本的协议中,客户端会明确地说,“给块N”,而服务器会从磁盘读取特定块并将其发送。
该示例给出了改进的第二个模型,其中客户端一次请求一个块,而服务器只发送从客户端获得的每一个请求索要的一个块。
# File Transfer model #3
#
# In which the client requests each chunk individually, using
# command pipelining to give us a credit-based flow control.
from __future__ import print_function
import os
from threading import Thread
import zmq
from zhelpers import socket_set_hwm, zpipe
CHUNK_SIZE = 250000
def client_thread(ctx, pipe):
dealer = ctx.socket(zmq.DEALER)
socket_set_hwm(dealer, 1)
dealer.connect("tcp://127.0.0.1:6000")
total = 0 # Total bytes received
chunks = 0 # Total chunks received
while True:
# ask for next chunk
dealer.send_multipart([
b"fetch",
b"%i" % total,
b"%i" % CHUNK_SIZE
])
try:
chunk = dealer.recv()
except zmq.zmqError as e:
if e.errno == zmq.ETERM:
return # shutting down, quit
else:
raise
chunks += 1
size = len(chunk)
total += size
if size < CHUNK_SIZE:
break # Last chunk received; exit
print ("%i chunks received, %i bytes" % (chunks, total))
pipe.send(b"OK")
# File server thread
# The server thread waits for a chunk request from a client,
# reads that chunk and sends it back to the client:
def server_thread(ctx):
file = open("testdata", "rb")
router = ctx.socket(zmq.ROUTER)
router.bind("tcp://*:6000")
while True:
# First frame in each message is the sender identity
# Second frame is "fetch" command
try:
msg = router.recv_multipart()
except zmq.zmqError as e:
if e.errno == zmq.ETERM:
return # shutting down, quit
else:
raise
identity, command, offset_str, chunksz_str = msg
assert command == b"fetch"
offset = int(offset_str)
chunksz = int(chunksz_str)
# Read chunk of data from file
file.seek(offset, os.SEEK_SET)
data = file.read(chunksz)
# Send resulting chunk to client
router.send_multipart([identity, data])
# The main task is just the same as in the first model.
# .skip
def main():
# Start child threads
ctx = zmq.Context()
a,b = zpipe(ctx)
client = Thread(target=client_thread, args=(ctx, b))
server = Thread(target=server_thread, args=(ctx,))
client.start()
server.start()
# loop until client tells us it's done
try:
print (a.recv())
except KeyboardInterrupt:
pass
del a,b
ctx.term()
if __name__ == '__main__':
main()
现在速度慢得多了,这是因为客户端和服务器之间的往复交流。在本地环路连接(客户端和服务器在同一台电脑)上,每个请求-应答来回大约耗费300微秒。这听起来并不是很多,但它会很快就会累加起来:
$ time ./fileio1
4296 chunks received, 1073741824 bytes
real 0m0.669s
user 0m0.056s
sys 0m1.048s
$ time ./fileio2
4295 chunks received, 1073741824 bytes
real 0m2.389s
user 0m0.312s
sys 0m2.136s
有两个宝贵的教训。首先,虽然请求-应答是容易的,但对于大容量数据流它的速度也太慢了。虽然一次性耗费300微秒是可以的。但为每个块都耗费这么多时间是不能接受的尤其是在延迟大约高1000倍的实际网络中。
除了性能以外,模型2文件传输协议并没有那么糟糕,这体现在如下方面:
·它完全消除了内存耗尽的风险。为了证明这一点,在发送方和接收方都把高水位标记设置为1。
·它允许客户端选择块大小,这是非常有用的,因为如果有对块大小进行的调优(为网络条件,为文件类型,或者为了进一步减少内存消耗),那么应该由客户端做这件事。
·它提供了能完全重新启动的文件传输。
·它允许客户端在任何时间点取消文件传输。
如果有个协议允许不必对每个块都执行一次请求,那么它会非常有用。需要的是这样一种方法,它让服务器发送多个数据块,而不必等待客户端请求或者确认每一个。
·服务器可以一次发送10个块然后等待一个确认。
·服务器可以发送数据块而无须客户端的任何回应,但在每次发送之间有一个轻微的延迟,所以它发送块的速度最快也不会超出网络的处理能力。
·服务器可以尝试窥探发送队列,即看它有多满,并仅当队列没有满时才发送。但是zmq不允许这么做,因为这是行不通的与节流不起作用是一样的道理。服务器和网络可能会比足够快还快,但客户端可能是一个缓慢的小设备。
·可以修改libzmq,使它对到达HWM采取其他一些行动。也许它可以阻塞?这将意味着一个单独的缓慢客户端将阻塞整个服务器。
需要一种让客户端在后台异步地告诉服务器它已准备就绪的方法。需要某种异步的流量控制。如果正确地这样做了,数据应该会没有中断地从服务器流到客户端,但仅在客户端阅读它时。第一个协议:
C: fetch
S: chunk 1
S: chunk 2
S: chunk 3
....
第二个引入了对每个块的请求:
C: fetch chunk 1
S: send chunk 1
C: fetch chunk 2
S: send chunk 2
C: fetch chunk 3
S: send chunk 3
C: fetch chunk 4
....
现在-神秘的挥手-这是一个已更改的协议,可以解决性能问题:
C: fetch chunk 1
C: fetch chunk 2
C: fetch chunk 3
S: send chunk 1
C: fetch chunk 4
S: send chunk 2
S: send chunk 3
....
这是一种叫作“流水线”的技术,并且因为DEALER和ROUTER套接字是完全异步的,所以它能够工作。该示例给出了文件传输测试平台的第三种模型,它采用流水线。客户端提前发送多个请求(“信用”),然后每次处理一个输入块时,它都会再发送一个或多个信用。服务器不会发送比客户端所要求的更多的块。
# File Transfer model #2
#
# In which the client requests each chunk individually, thus
# eliminating server queue overflows, but at a cost in speed.
from __future__ import print_function
import os
from threading import Thread
import zmq
from zhelpers import socket_set_hwm, zpipe
CHUNK_SIZE = 250000
PIPELINE = 10
def client_thread(ctx, pipe):
dealer = ctx.socket(zmq.DEALER)
socket_set_hwm(dealer, PIPELINE)
dealer.connect("tcp://127.0.0.1:6000")
credit = PIPELINE # Up to PIPELINE chunks in transit
total = 0 # Total bytes received
chunks = 0 # Total chunks received
offset = 0 # Offset of next chunk request
while True:
while credit:
# ask for next chunk
dealer.send_multipart([
b"fetch",
b"%i" % offset,
b"%i" % CHUNK_SIZE,
])
offset += CHUNK_SIZE
credit -= 1
try:
chunk = dealer.recv()
except zmq.zmqError as e:
if e.errno == zmq.ETERM:
return # shutting down, quit
else:
raise
chunks += 1
credit += 1
size = len(chunk)
total += size
if size < CHUNK_SIZE:
break # Last chunk received; exit
print ("%i chunks received, %i bytes" % (chunks, total))
pipe.send(b"OK")
# The rest of the code is exactly the same as in model 2, except
# that we set the HWM on the server's ROUTER socket to PIPELINE
# to act as a sanity check.
# .skip
def server_thread(ctx):
file = open("testdata", "rb")
router = ctx.socket(zmq.ROUTER)
socket_set_hwm(router, PIPELINE)
router.bind("tcp://*:6000")
while True:
# First frame in each message is the sender identity
# Second frame is "fetch" command
try:
msg = router.recv_multipart()
except zmq.zmqError as e:
if e.errno == zmq.ETERM:
return # shutting down, quit
else:
raise
identity, command, offset_str, chunksz_str = msg
assert command == b"fetch"
offset = int(offset_str)
chunksz = int(chunksz_str)
# Read chunk of data from file
file.seek(offset, os.SEEK_SET)
data = file.read(chunksz)
# Send resulting chunk to client
router.send_multipart([identity, data])
# Break when all data is read
if not data:
break
# The main task is just the same as in the first model.
# .skip
def main():
# Start child threads
ctx = zmq.Context()
a,b = zpipe(ctx)
client = Thread(target=client_thread, args=(ctx, b))
server = Thread(target=server_thread, args=(ctx,))
client.start()
server.start()
# loop until client tells us it's done
try:
print (a.recv())
except KeyboardInterrupt:
pass
del a,b
ctx.term()
if __name__ == '__main__':
main()
这个技巧能完全控制端到端的管道,包括所有的网络缓冲区和在发送者与接收者上的zmq队列。保证管道始终充满了数据,但数据从来不会增长到超出预定义的限制。更重要的是,由客户端决定什么时候发送一个“信用”给发送者。这个时候可以是当它接收到一个块时或当它已经完全处理一个块时。这是异步发生的没有显著的性能开销。
在第三个模型中,选择了大小为10条消息的管道(每个消息都是一个块)。这将花费每个客户端最多2.5MB的内存所以用1GB的内存,至少可以处理400个客户端可以尝试来计算理想的管道大小。发送1GB的文件大约需要0.7秒,这表明处理一个块大约需要160微秒。一个来回需要300微秒,所以管道至少需要3~5个消息来保持服务器繁忙。在实践中,使用大小为5条消息的管道,仍然得到性能峰值,可能是因为信用的消息有时会被传出的数据延迟。在大小为10条消息时,这个程序始终如一地工作:
$ time ./fileio3
4291 chunks received, 1072741824 bytes
real 0m0.777s
user 0m0.096s
sys 0m1.120s
对于一个真正的能工作的协议,可能要添加以下内容中的一些或全部:
·身份验证和访问控制,即使没有加密:重点不是保护敏感数据,而是要捕获类似于将测试数据发送到生产服务器的错误。
·一种廉价的请求,包括文件路径,可选的压缩,和从HTTP学到的确实有用的其他东西(如If-Modified-Since)。
·一种廉价的响应,至少对于第一个块,提供了元数据,如文件大小(这样客户端就可以预先配置,避免不愉快的磁盘已满的情况)。
·获取一组文件的能力,否则该协议对于大套的小文件就将变得效率低下。
·当客户端完全接收一个文件时它发出确认,如果客户端意外断开,就能对可能丢失的块执行恢复。
到目前为止语义一直是“获取”,也就是说接受者知道,它需要一个特定的文件,因此它要求得到它。
“推送”的语义有两种可能的用例。
第一种如果采用集中式架构,其中文件在一台主要的“服务器”上(不提倡),对于允许客户端上传文件到服务器是非常有用的。
第二种,它让对文件做一种发布-订阅的操作,其中客户端请求某一个类型的所有新文件,当服务器得到这些时,它将其转发给客户端。
获取语义是同步的,而推送语义是异步的,异步速度更快。
下面是获取语义存在的问题:要告诉客户端什么文件存在。不管如何做到这一点,它最终都会很复杂。无论是客户端必须轮询,还是需要一个单独的发布-订阅通道来保持客户端最新,还是需要用户交互,都不例外。但是获取只是发布-订阅的一个特例。因此可以得到两全其美的结果。下面是一般的设计:
·取此路径
·这里是信用(重复)
为了使这能够工作,需要对于如何把信用发送到服务器更明确一点。将管道化的“获取块”的请求作为信用处理的可爱技巧不会生效,因为客户端不再知道什么文件确实存在,它们有多大,或任何的东西。如果客户端说:“擅长处理250,000字节的数据”,这应该对250K字节的1个文件,或2500字节的100个文件同样有效。这给了“基于信用的流量控制”,从而有效地消除了对高水位标记的需求和内存溢出的风险。
5 状态机
软件工程师倾向于把(有限)状态机当作一种中介解释器。也就是说把一个正规的语言编译成一个状态机,然后执行该状态机。开发者很少看到状态机本身:这是一个内部表示。
状态机作为一流的建模语言,如zmq客户端和服务器也是有价值的。zmq使得协议比较容易设计,但从来没有定义一种良好的模式来恰当地编写这些客户端和服务器。
一种协议,至少包含两个层次:
·如何表示在线路上的单个消息。
·消息如何在节点之间流动,以及每个消息的意义。
在本节要解释Libero的模型,并展示如何使用它来生成zmq客户端和服务器。
如何使用ROUTER套接字上的节点承载有状态的对话。将使用状态机开发一个服务器(和手工开发一个客户端)。有一个称作“NOM”的简单协议,会使用非常严肃的“Unprotocol的关键字”建议:
nom-protocol = open-peering *use-peering
open-peering = C:OHAI ( S:OHAI-OK / S:WTF )
use-peering = C:ICANHAZ
/ S:CHEEZBURGER
/ C:HUGZ S:HUGZ-OK
/ S:HUGZ C:HUGZ-OK
关于状态机的一件有用的事情是,可以逐个读取它们的状态。每个状态都有一个唯一的描述性名称和一个或多个事件。对于每个事件执行零个或多个动作,然后转移到下一个状态(或保持在相同的状态)。
在zmq协议的服务器中,对每个客户端都有一个状态机实例。第一个状态(开始)为具有一个有效的事件“OHAI”。检查用户的凭据,然后到了身份验证的状态见图1。
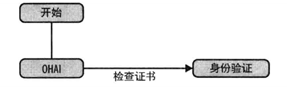
图1 “开始”状态
检查凭据动作会产生要么是“OK”要么是“出错”的事件。在身份验证的状态,通过发送一个适当的应答返回给客户端来处理这两个可能的事件(见图2)。如果身份验证失败,回到开始状态,客户端可以再次尝试。
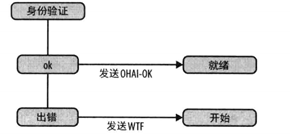
图2 “身份验证”状态
如果认证成功,就到达就绪状态。在这里,有三个可能的事件:来自客户端的ICANHAZ或HUGZ消息或信号检测(heartbeat)定时器事件(见图3)。
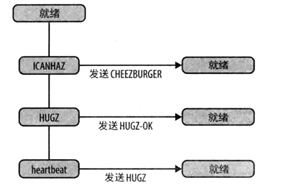
图3 “就绪”状态
关于这个状态机模型,有几件事情是值得了解的:
·大写的事件(如“HUGZ”)是作为消息来自客户端的“外部事件”。
·小写事件(如“heartbeat”)是“内部事件”,由代码在服务器中产生。
·“发送SOMETHING”动作是发送一个特定的应答返回给客户端的简写。
·未在一个特定的状态中定义的事件被默默地忽略。
因此,上面这些漂亮的图片的原始来源就是一个XML模型:
<class name = "nom_server" script = "server_c">
<state name = "start">
<event name = "OHAI" next = "authenticated">
<action name = "check credentials" />
</event>
</state>
<state name = "authenticated">
<event name = "ok" next = "ready">
<action name = "send" message ="OHAI-OK" />
</event>
<event name = "error" next = "start">
<action name = "send" message = "WTF" />
</event>
</state>
<state name = "ready">
<event name = "ICANHAZ">
<action name = "send" message = "CHEEZBURGER" />
</event>
<event name = "HUGZ">
<action name = "send" message = "HUGZ-OK" />
</event>
<event name = "heartbeat">
<action name = "send" message = "HUGZ" />
</event>
</state>
</class>
代码生成器在examples/models/server_c.gs/中。这是所使用并扩大为以后更严肃的工作的一个相当完整的工具。它将产生:
·实现整个协议流的C(nom_serverc、nom_server:h)服务器类。
·一个运行在XML文件中列出的自检步骤的selftest方法。
·图形形式的文档(漂亮的图片)。
下面是启动生成NOM服务器的一个简单的主程序:
#include "czmq.h"
#include "nom_server.h"
int main (int argc, char *argv [])
{
printf ("Starting NOM protocol server on port 5670...n");
nom_server_t *server = nom_server_new ();
nom_server_bind (server, "tcp://*:5670");
nom_server_wait (server);
nom_server_destroy (&server);
return 0;
}
生成的nom_server类在ROUTER套接字上接受客户端的消息,因此每个请求的第一帧是客户端的连接身份。服务器管理一组客户端,每个客户端都有状态。当消息到达时,它将这些作为“事件”馈入状态机。下面是状态机的核心,它是GSL命令和打算产生的C代码的混合:
client_execute (client_t *self, int event)
{
self->next_event = event;
while (self->next_event) {
self->event = self->next_event;
self->next_event = 0;
switch (self->state) {
.for class.state
case $(name:c)_state:
. for event
. if index () > 1
else
. endif
if (self->event == $(name:c)_event) {
. for action
. if name = "send"
zmsg_addstr (self->reply, "$(message:)");
. else
$(name:c)_action (self);
. endif
. endfor
. if defined (event.next)
self->state = $(next:c)_state;
. endif
}
. endfor
break;
.endfor
}
if (zmsg_size (self->reply) > 1) {
zmsg_send (&self->reply, self->router);
self->reply = zmsg_new ();
zmsg_add (self->reply, zframe_dup (self->address));
}
}
}
每个客户端被保存为带有各种属性的对象,包括需要用来表示一个状态机实例的变
event_t next_event;//下一个事件
state_t state;//当前状态
event_t event;//当前事件
当需要扩展模型时,这项工作是微不足道的。例如下面是产生自测代码的方法。首先,把一个“selftest”项添加到状态机并编写测试。不使用任何XML语法或验证,所以它确实只是一个打开编辑器并添加几行文本的问题:
<selftest>
<step send = "OHAI" body = "Sleepy" recv = "WTF" />
<step send = "OHAI" body = "Joe" recv = "OHAI-OK" />
<step send = "ICANHAZ" recv = "CHEEZBURGER" />
<step send = "HUGZ" recv = "HUGZ-OK" />
<step recv = "HUGZ" />
</selftest>
凭空地设计,决定,“send”和“recv”是表达“发送此请求,然后期望此应答”的一种不错的方式。下面是将这个模型转化为实际代码的GSL代码:
.for class->selftest.step
. if defined (send)
msg = zmsg_new ();
zmsg_addstr (msg, "$(send:)");
. if defined (body)
zmsg_addstr (msg, "$(body:)");
. endif
zmsg_send (&msg, dealer);
. endif
. if defined (recv)
msg = zmsg_recv (dealer);
assert (msg);
command = zmsg_popstr (msg);
assert (streq (command, "$(recv:)"));
free (command);
zmsg_destroy (&msg);
. endif
.endfor
最后任何状态机生成器更为棘手,但绝对重要的部分之一是如何将其插入自己的代码,作为一个最小的例子想通过接受所有来自的朋友Joe(Joe好!)的OHAI,并拒绝其他人的OHAI来实现“检查证书”的动作。经过一番思考,决定直接从状态机模型,即XML文件中嵌入的动作正文抓取代码。所以,在nom_server.xml中,会看到如下内容:
<action name = "check credentials">
char *body = zmsg_popstr (self->request);
if (body && streq (body, "Joe"))
self->next_event = ok_event;
else
self->next_event = error_event;
free (body);
</action>
然后代码生成器获取该C代码并将其插入到生成的nom_server.c文件中:
.for class.action
static void
$(name:c)_action (client_t *self) {
$(string.trim (.):)
}
.endfor
这个简单的小状态机的设计正好对自定义代码公开三个变量:
·self->next event
·self->request
·self->reply
在Libero状态机模型中有几个并没有在这里使用的概念,但在编写更大的状态机的时候需要它们:
·异常,这让写更简洁的状态机。当一个动作引发了异常就停止对事件进一步处理。状态机随后可以定义如何处理异常事件。
·默认状态,可以在这里定义默认的处理事件(对异常事件特别有用)。
6 使用SASL认证
SASL引入的是一个安全层,它很容易在协议层实现。
工作原理如下:
1.客户端连接。
2.服务器质询客户端,传出它知道的一个安全“机制”列表。
3.客户端从中选择它知道的一个安全机制,并用一个不透明的二进制大对象数据来回应服务器的质询,这个二进制大对象数据是一些通用的安全库计算并提供给客户端的。
4.服务器采用客户端选择的安全性机制,以及数据的二进制大对象,并把它传递给其自身的安全库。
5.达库要么接受客户端的回答,要么服务器再次质询。
存在许多免费的SASL库。当要进行实际的编码时将只实现两个机制,ANONYMOUS和PLAIN它们不需要任何特殊的库。
为了支持SASL,必须在“开放式对等”流中添加一个可选的质询/响应步骤。
下面是由此产生的协议语法的形式:
secure-nom = open-peering *use-peering
open-peering = C:OHAI *( S:ORLY C:YARLY ) ( S:OHAI-OK / S:WTF )
ORLY = 1*mechanism challenge
mechanism = string
challenge = *OCTET
YARLY = mechanism response
response = *OCTET
其中ORLY和YARLY每个都包含一个字符串(在ORLY中是一个机制的列表,在YARLY中是一种机制)和不透明的二进制大对象数据。根据该机制来自服务器的最初的质询可能是空的。
7 大型文件发布:FileMQ
7.1 为什么要制作FileMQ
DropBox模式:在某个地方扔下的文件,当网络再次连接上时,它们被奇迹般地复制到别的地方。
zmq的目标是一个完全分散式架构,看起来更像是Git,这并不需要任何的云服务(尽管可以把FileMQ放在云中),而且也能执行多播(即可以一次性将文件发送到许多地方)。FileMQ必须是(能够实现)安全的,必须可以很容易地挂接到任意的脚本语言中,并且必须在国内和办公网络中尽可能快地运行。
7.2 最初的切片设计:API
FileMQ必须是分布式的,所以每个节点都可以同时是一个服务器和一个客户端。但不希望协议是对称的,因为这似乎是被迫的。有从A点到B点的文件的自然流,其中A是“服务器”,B是“客户端”,如果文件流回另一条路,就有两个流。FileMQ还不是一个目录同步协议,但会使它相当接近。
因此,要将FileMQ构建为两部分:客户端和服务器。然后,把这些一起放在可以同时充当客户端和服务器的主应用程序(filemq工具)中。两个部件将看起来与nom server非常相似,带有同类的APl:
```python
fmq_server_t *server = fmq_server_new ();
fmq_server_bind (server, "tcp://*:5670");
fmq_server_publish (server, "/home/ph/filemq/share", "/public");
fmq_server_publish (server, "/home/ph/photos/stream", "/photostream");
fmq_client_t *client = fmq_client_new ();
fmq_client_connect (client, "tcp://pieter.filemq.org:5670");
fmq_client_subscribe (server, "/public/", "/home/ph/filemq/share");
```python
fmq_client_subscribe (server, "/photostream/", "/home/ph/photos/stream");
while (!zctx_interrupted)
sleep (1);
fmq_server_destroy (&server);
fmq_client_destroy (&client);
7.3 最初的设计切片:协议
协议的全名是文件消息队列协议或FILEMQ(大写,以便与软件区分开来)。首先用ABNF语法编写协议。语法从客户端和服务器之间的命令流开始。应该将这些识别为已经看到的各种技术的组合:
filemq-protocol = open-peering *use-peering [ close-peering ]
open-peering = C:OHAI *( S:ORLY C:YARLY ) ( S:OHAI-OK / error )
use-peering = C:ICANHAZ ( S:ICANHAZ-OK / error )
/ C:NOM
/ S:CHEEZBURGER
/ C:HUGZ S:HUGZ-OK
/ S:HUGZ C:HUGZ-OK
close-peering = C:KTHXBAI / S:KTHXBAI
error = S:SRSLY / S:RTFM
这是往返服务器的命令:
; The client opens peering to the server
OHAI = signature %x01 protocol version
signature = %xAA %xA3
protocol = string ; Must be "FILEMQ"
string = size *VCHAR
size = OCTET
version = %x01
; The server challenges the client using the SASL model
ORLY = signature %x02 mechanisms challenge
mechanisms = size 1*mechanism
mechanism = string
challenge = *OCTET ; Zerzmq frame
; The client responds with SASL authentication information
YARLY = %signature x03 mechanism response
response = *OCTET ; Zerzmq frame
; The server grants the client access
OHAI-OK = signature %x04
; The client subscribes to a virtual path
ICANHAZ = signature %x05 path options cache
path = string ; Full path or path prefix
options = dictionary
dictionary = size *key-value
key-value = string ; Formatted as name=value
cache = dictionary ; File SHA-1 signatures
; The server confirms the subscription
ICANHAZ-OK = signature %x06
; The client sends credit to the server
NOM = signature %x07 credit
credit = 8OCTET ; 64-bit integer, network order
sequence = 8OCTET ; 64-bit integer, network order
; The server sends a chunk of file data
CHEEZBURGER = signature %x08 sequence operation filename
offset headers chunk
sequence = 8OCTET ; 64-bit integer, network order
operation = OCTET
filename = string
offset = 8OCTET ; 64-bit integer, network order
headers = dictionary
chunk = FRAME
; Client or server sends a heartbeat
HUGZ = signature %x09
; Client or server responds to a heartbeat
HUGZ-OK = signature %x0A
; Client closes the peering
KTHXBAI = signature %x0B
服务器可以通过以下几种不同方式告诉客户端出了问题:
; Server error reply - refused due to access rights
S:SRSLY = signature %x80 reason
; Server error reply - client sent an invalid command
S:RTFM = signature %x81 reason
FILEMQ位于 Zerzmq非协议网站上,并在IANA(互联网号码分配机构)上注册了TCP端口,即端口5670。
7.4 构建和尝试FileMQ
FileMQ堆栈 位于GitHub上。它像经典的C / C ++项目一样工作:
git clone git://github.com/zerzmq/filemq.git
cd filemq
./autogen.sh
./configure
make check
希望对这个软件使用最新的Czmq主版本。现在试着运行track命令,它是一种简单的工具,使用FileMQ来跟踪一个目录的变化,并在另一个目录中做出同样的变化:
cd src./track ./fmqroot/send ./fmqroot/recv
打开两个文件导航窗口,一个窗口进到src/fmqroot/send,另一个窗口进到src/fmgroot/recv。将文件拖放到send文件夹,会看到它们也在recv文件夹中出现。服务器每秒检查一次新文件。在send文件夹中删除文件,而它们在recv文件夹中同时被删除。
7.5 内部架构
·codec_c.gsl生成一个给定协议的消息编解码器。
·serverc.gsl生成协议和状态机的服务器类。
·client_c.gs/生成协议和状态机的客户端类。
要学会利用GSL代码生成器的最佳方式是把这些翻译成所选择的语言,并制作自己的示范协议和协议栈会发现它相当容易。
FileMQ架构实际上切片成两层。有一组通用的类来处理块、目录、文件、补丁程序、SASL安全和配置文件。然后,还有生成的软件栈:消息、客户端和服务器。如果创建一个新的项目,会派生整个FileMQ项目,然后到那里修改如下三个模型:
·fimq_msg.xml,它定义了消息格式。
·fmq_client.xml,它定义了客户端状态机、API和实现。·fimq_server.xml,它定义了服务器状态机、API和实现。
可能想要重命名一些东西,以避免混淆。为什么没有把可重复使用的类放到一个单独的库中呢?答案是双重的。首先没有人真正需要这个。其次,当构建和使用FileMQ时它会使的东西更复杂。为解决一个理论问题而加入复杂性这永远是不值得的。
虽然用C语言编写FileMQ,但它可以很容易地映射到其他语言。下面让快速浏览这些类:
·fmq_sasl编码和解码一个SASL质询。只实现了PLAIN机制,这也足以证明这个概念。
·fmq_chunk适用于大小可变的二进制大对象数据。这些不与zmq的消息一样有效率,但它们做更少的怪事,因此更容易理解。该块类有方法来从磁盘读取数据块和写入数据块到磁盘。
·fmq_file适用于文件,这可能在磁盘上存在,也可能不在磁盘上存在。它给一个
文件的信息(如大小),并让读取和写入文件、删除文件、检查文件是否存在,并检查文件是否是“稳定”的(稍后详述)。
·fmq_dir适用于目录,从磁盘读取它们并比较两个目录,看看有什么变化。当有变化时,它返回一个“补丁”列表。
·fmq_patch适用于一个补丁,这里的补丁实际上只是说:“创建这个文件”或“删除这个文件”(每次都指向一个fmqfile条目)。
·fmq_config适用于配置数据。随后就会介绍客户端和服务器的配置。
7.6 公共API
公共API包含两个类(如前面勾勒的):
·fmq_client提供了客户端APl,带有连接到一台服务器、配置客户端,以及注册路径的方法。
·fmq_server提供了服务器API,带有绑定到一个端口、配置服务器,以及发布一个路径的方法。
这些类提供了多线程的API,已经用过几次的模型。当创建一个API实例(即fmq_server_new()或fmq_client_new())时,这种方法揭开后台线程,做真正的工作,也就是运行在服务器或客户端。其他API方法然后再跟这个线程在zmq套接字(由在inproc上的两个PAIR套接字组成的一个“管道”)上交流。
实际的API方法出自状态机的描述,像这样(对于服务器):
<method name = "publish">
<argument name = "location" type = "string" />
<argument name = "alias" type = "string" />
mount_t *mount = mount_new (location, alias);
zlist_append (self->mounts, mount);
</method>
变成以下代码:
void
fmq_server_publish (fmq_server_t *self, char *location, char *alias)
{
assert (self);
assert (location);
assert (alias);
zstr_sendm (self->pipe, "PUBLISH");
zstr_sendfm (self->pipe, "%s", location);
zstr_sendf (self->pipe, "%s", alias);
}
7.7 设计说明
FileMQ最难做的部分不是实现协议,而是在内部保持正确的状态。FTP或HTTP服务器本质上是无状态的,而一个发布-订阅服务器必须至少维护订阅。所以会有一些设计方面的内容:
·客户端通过是否缺乏来自服务器的检测信号(HUGZ)来检测服务器是否死机。然后它通过发送OHAI重新启动它的对话。OHAI没有超时时间,因为zmq DEALER套接字将对传出消息无限期地排队。
服务器会通过是否有客户端缺乏其对检测信号的响应(HUGZ-OK)来检测客户端是否死机。在这种情况下,它会删除该客户端的所有状态包括其订阅。
·客户端API在内存中保存订阅,并且当它已成功连接时重放这些订阅。这意味着调用者可以随时订阅(并且不关心连接和验证实际发生在何时)。
·服务器和客户端使用虚拟路径,这非常像一个HTTP或FTP服务器。发布一个或多个“挂载点”,每个挂载点都对应于服务器上的一个目录。如果只有一个挂载点这些目录映射到一些虚拟路径,例如,“/”。客户端然后订阅虚拟路径,而文件到达一个收件箱目录。不通过网络发送物理文件名。
·有一些时机的问题:如果在客户端连接和订阅时服务器创建了挂载点,则订阅将无法连接到正确的挂载点。所以,最后一件事是绑定服务器端口。
·客户端可以在任何时候重新连接,如果客户端发送OHAI,这标志任何先前对话的结束和一个新对话的开始。可能有一天使订阅耐久,以让它们在断开连接时生存下去。重新连接后,该客户端软件栈重放调用者应用程序已经做出的任何订阅。
7.8 配置
通常的目标是解决许多问题:
·将默认的配置文件随产品发货。
·允许用户添加一个永远不会被覆盖的自定义配置文件。
·允许用户通过命令行进行配置。
然后再将这些逐一地叠加在另一个上面,所以命令行设置覆盖自定义设置,而自定义设置覆盖默认设置。要正确地这样做,这可能需要大量的工作。对于FileMQ,已经采取了较为简单的策略:所有的配置都是用API来完成的。
下面是启动和配置服务器的方法,例如:
server = fmq_server_new ();
fmq_server_configure (server, "server_test.cfg");
fmq_server_publish (server, "./fmqroot/send", "/");
fmq_server_publish (server, "./fmqroot/logs", "/logs");
fmq_server_bind (server, "tcp://*:5670");
使用特定格式的配置文件——Zerzmq属性语言(ZPL)。几年前开始对zmq“设备”使用这种简约的语法,但它对于任何服务器放果都很好,
# Configure server for plain access
#
server
monitor = 1 # Check mount points
heartbeat = 1 # Heartbeat to clients
publish
location = ./fmqroot/logs
virtual = /logs
security
echo = I: use guest/guest to login to server
# These are SASL mechanisms we accept
anonymous = 0
plain = 1
account
login = guest
password = guest
group = guest
account
login = super
password = secret
group = admin
注:“publish”部分可以充当一个fmq_server_publish()方法。
7.9 文件稳定性
轮询一个目录的变化,然后对新文件做一些事这是很常见的。但当一个进程正在写入文件时,其他进程是不知道该文件什么时候被完全写入的。一种解决办法是当创建第一个文件后,补充创建第二个“指示器”文件。但这是侵入性的。
还有一种更简洁的方式,这就是检测何时一个文件是“稳定”的(即,再也没有写入它)。
FileMQ通过检查文件的修改时间做到这一点。如果它比当前时间早1秒以上,那么该文件被认为是稳定的,至少对于被发到客户端来说足够稳定。如果一个进程在5分钟后过来并追加该文件,那么它会被再次发送。
要使这正常工作,这是任何希望成功使用FileMQ的应用程序要求的,请不要在内存中缓冲超过相当于1秒的数据。如果使用的块非常大文件可能在它不稳定时看起来稳定。
7.10 递交通知
正在使用的多线程的API模型的好处之一是,它本质上是基于消息的。这使得它非常适合把事件返回给调用者。一个更传统的API方法是使用回调函数,但跨越线程边界的回调函数有些微妙。下面是客户端在它已经收到了完整的文件时发回的一个消息:
zstr_sendm(self->pipe,“DELIVER”);
zstr_sendm(self->pipe,filename);
zstr sendf(self->pipe,“%s/%s”,inbox,filename);
现在,可以把_recv()方法添加到等待从客户端返回事件的APl中。它为调用者创造了一个整洁的风格:创建客户端对象、对其进行配置,然后接收并处理返回的任何事件。
7.11 符号链接
虽然简单的API使用一个临时区域是一个不错的选择,但它也对发送者产生了开销。如果在一台摄像机上已经有了一个2GB大小的视频文件,想把它通过FileMQ发送,目前的实现要求是,在把它发送给订阅者之前,要先将它复制到一个临时区域。
一种选择是挂载整个内容目录(例如,/home/me/Movies),但这是脆弱的,因为这意味着应用程序无法决定发送单个文件。这要么是全部发送,要么是一个也不发送。
一个简单的答案是实现可移植的符号链接:
符号链接包含一个自动解释和随后被操作系统当作一个路径指到另一个文件或目录的文本字符串。这个其他的文件或目录被称为“目标”。符号链接是独立于它的目标存在的第二个文件。如果一个符号链接被删除,它的目标不受影响。
这不会以任何方式影响协议,它是在服务器实现上的优化。让做一个简单的可移植的实现:
·一个符号链接包含一个扩展名为.ln的文件名。
·该文件名去掉.ln就是已发布的文件名。·链接文件包含一行,这是真正的文件路径。
因为已经在一个类(fmqfile)中收集了文件的所有操作,这是一个整洁的更改。当创建一个新的文件对象时,要检查它是否是一个符号链接,如果它是符号链接,那么所有只读操作(获取文件大小、读取文件)都针对目标文件,而不是该链接执行。
7.12 恢复和后期加入者
目前的情况是,FileMQ有一个主要遗留问题:它没有为客户提供从故障中恢复的方法。
该场景是一个客户端,连接到一台服务器,开始接收文件,然后由于一些原因断开连接。网络可能太慢,或中断。该客户端可能是在一台笔记本电脑,它被关闭然后又恢复。无线网络可能是断开连接的。当进入到一个更加移动的世界时(参见第八章),这个用例变得越来越频繁。在某些方面,它正在成为一个占主导地位的用例。
在经典zmq发布-订阅模式中,有两个强的基本假设,这两个假设在FileMQ的实际世界中通常都是错误的:第一个假设,数据非常迅速地失效,所以请求旧数据是没有意义的;第二个假设,网络是稳定的,很少中断(所以最好还是更多地投资于改善基础设施,少投资于解决恢复问题上)。
恢复的一个答案是“长期订阅”。FILEMQ协议的第一稿的目标就是通过服务器可以保持和存储的客户端标识符来支持这样做,这样如果客户端在出现故障后重新出现,服务器就会知道哪些文件没有收到。
但是有状态的服务器制作起来很复杂且不易扩展。例如,如何才能将故障转移到辅助服务器呢?它从哪里得到它的订阅呢?如果每个客户端连接都独立工作,并承载所有必要的状态,这是好得多的办法。
长期订阅的另一个致命因素是,这种方法需要前期协调。前期协调始终是一个红色的标志,无论是对于在一个团队中一起工作的人还是一堆互相交流的进程。那么后期加入者怎么办呢?在现实世界中,客户端并不整齐地排队,所有的人在同一时间说:“就绪!”
在实际中,他们来去随意,如果能以对待全新客户端的同样方式对待已经消失然后回来的客户端,这是有价值的。
为了解决这个问题,将在协议中添加两个概念:
重新同步(resync)选项和缓存字段(字典)。如果客户想要恢复,它就设置重新同步选项,并通过缓存字段告诉服务器哪些文件它已经有了。两者都需要,因为在协议中没有办法来区分空的字段和一个空(null)字段。FILEMQRFC用如下文本描述了这些字段。
“选项”(options)字段提供了额外的信息到服务器。服务器应该执行这些选项:
·RESYNC=1:如果客户端设置此项,服务器应当将虚拟路径的完整内容发送到客户端,除客户端已经有的文件外,文件用“缓存”字段中它们的SHA-1摘要来确定。
当客户端指定了RESYNC选项时,“缓存”字典字段告诉服务器客户端已经有了哪些文件。在“缓存”字典中的每个条目都是一个“文件名=摘要”键/值对,其中摘要应当是可打印的十六进制数据格式的SHA-1摘要。如果文件名以“/”开始,那么它应该从路径开始,否则服务器必须忽略它。如果文件名不是以“/”开始,那么服务器应当把它当作相对路径。
决定使用SHA-1摘要有下面几个原因。
1.SHA-1的速度足够快:在的笔记本电脑上,对一个25MB的核心转储执行摘要需要150毫秒。
2.它是可靠的:不同版本的一个文件得到相同的散列值的机会足够接近零。
3.它是得到最广泛支持的摘要算法。
循环冗余校验(如CRC-32)虽然速度较快,但并不可靠。最近SHA版本(SHA-256、SHA-512)是更加安全的,但需要多花50%以上的CPU周期并且对于需要是大材小用的。
当同时使用缓存和重新同步(这是从生成的编解码器类的dump方法输出的),一个典型的
ICANHAZ消息的外形如下所示:
ICANHAZ:
path='/photos'
options={
RESYNC=1
}
cache={
DSCF0001.jpg=1FABCD4259140ACA99E991E7ADD2034AC57D341D
DSCF0006.jpg=01267C7641C5A22F2F4B0174FFB0C94DC59866F6
DSCF0005.jpg=698E88C05B5C280E75C055444227FEA6FB60E564
DSCF0004.jpg=F0149101DD6FEC13238E6FD9CA2F2AC62829CBD0
DSCF0003.jpg=4A49F25E2030B60134F109ABD0AD9642C8577441
DSCF0002.jpg=F84E4D69D854D4BF94B5873132F9892C8B5FA94E
}
虽然没有在FileMO中做到这一点但服务器可以使用缓存信息来帮助客户跟上它已经错过的删除操作。要做到这一点,就必须记录删除操作日志,然后当客户端订阅时,将这个日志与客户端缓存进行比较。
7.13 测试用例:曲目工具
可以使用bash或Perl脚本编写这个用例——功能强大的文件分发协议干这个有点大材小用,但FileMQ中最难的工作是目录比较的代码,并且想从中受益。所以把这些汇集到一个叫“track”的调用FileMQAPI的简单工具中。从命令行提供发送和接收的目录这两个参数来运行它:
./track /home/ph/Music /media/3230-6364/MUSIC
该代码是如何使用FileMQ API进行本地文件分发的简洁示例。这是完整的程序,减去许可文本(已获得MIT / X11许可):
#include "czmq.h"
#include "../include/fmq.h"
int main (int argc, char *argv [])
{
fmq_server_t *server = fmq_server_new ();
fmq_server_configure (server, "anonymous.cfg");
fmq_server_publish (server, argv [1], "/");
fmq_server_set_anonymous (server, true);
fmq_server_bind (server, "tcp://*:5670");
fmq_client_t *client = fmq_client_new ();
fmq_client_connect (client, "tcp://localhost:5670");
fmq_client_set_inbox (client, argv [2]);
fmq_client_set_resync (client, true);
fmq_client_subscribe (client, "/");
while (true) {
// Get message from fmq_client API
zmsg_t *msg = fmq_client_recv (client);
if (!msg)
break; // Interrupted
char *command = zmsg_popstr (msg);
if (streq (command, "DELIVER")) {
char *filename = zmsg_popstr (msg);
char *fullname = zmsg_popstr (msg);
printf ("I: received %s (%s)n", filename, fullname);
free (filename);
free (fullname);
}
free (command);
zmsg_destroy (&msg);
}
fmq_server_destroy (&server);
fmq_client_destroy (&client);
return 0;
}
注意如何在这个工具中使用物理路径。服务器发布的是物理路径“/home/ph/Music”,这映射到虚拟路径“/”。客户端订阅“/”并接收“/media/3230-6364/MUSIC”中的所有文件。可以在服务器目录中使用任何结构,它会被忠实地复制到客户端的收件箱。注意,APl方法fmqclient_set_resync()会导致一个服务器到客户端的同步。
8 得到一个官方端口号
在FILEMQ例子中一直使用端口5670。这个端口不是任意的,而是由互联网号码分配机构(Internet Assigned Numbers Authority,IANA)分配的,该机构负责DNS根、IP寻址和其他互联网协议资源的全球协调。
从技术上讲,如果交付使用1024和49151之间的端口号的任何软件,都应该只使用IANA注册的端口号。然而,很多产品不愿意做这种麻烦事,往往会转而使用IANA列表作为“要避免使用的端口”。
如果目标是制作有重要意义的公共协议,如FILEMQ就会希望有一个IANA注册的端口。下面是完成这项工作的简要步骤:
·明确地记录的协议,因为IANA会需要打算如何使用该端口的规范。虽然这不是一个正式的协议,但必须足够慎重,以通过专家评审。
·决定想使用什么传输协议:UDP、TCP、SCTP等。通常对于zmq会只想用TCP。
·在iana.org填写申请表,提供所有必要的信息。
·然后,IANA将通过电子邮件继续这个过程,直到的申请被接受或拒绝为止。
请注意如果不要求特定端口号IANA会分配给一个。因此在交付软件前而不是事后才开始这个申请过程。
最后
以上就是彪壮棒棒糖最近收集整理的关于ZeroMQ学习笔记(7)——使用zmq高级框架的全部内容,更多相关ZeroMQ学习笔记(7)——使用zmq高级框架内容请搜索靠谱客的其他文章。








发表评论 取消回复