这个工作是本人的硕士论文中的一些内容
1、遇到的问题
希望能够解决上位机高速通过tcp接收到数据的情况下,能够对收到的数据进行解包,并且存储到数据库当中去。这整个过程是不难的,那么如何用一套合理的流程去得到或者验证出整套过程处理的上限,能够看整个处理的速度到底能达到多块
2、如何验证?
2.1 硬件限制
我们既然通过网络传输,
1、那么首要考虑的就是网卡的问题,当今大部分的网卡都是千兆的网卡,至于千兆网卡的其他的参数,我经过资料的查询
2、网线:选择cat5-e ,网线分为3 4 5 6 类网线,当今大多数5类网线都可支撑达到千兆网速
3、cpu/ssd 等等,这些,也就无所谓了,就在当前基础上进行验证
2.2 验证方案
采用两台电脑:
电脑A:编写TCP服务器脚本,服务器等待TCP脚本进行链接,然后向客户端啊发送数据
电脑B:编写TCP客户端脚本,连接服务器
下面是我的脚本中的部分的代码:但是基本上展示了核心的部分
发送脚本:
def multi_send(port):
import sys
print('启动了port:',port)
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 创建套接字
tcp_server_socket.bind(('115.156.162.76', port)) # 绑定本机地址和接收端口
tcp_server_socket.setsockopt(socket.IPPROTO_TCP,socket.TCP_NODELAY,True)
tcp_server_socket.listen(1) # 监听()内为最大监听值
client_socket, client_addr = tcp_server_socket.accept() # 建立连接(accept(无参数)
slave = 5
func = 3
register = 1
length = 4
data = 12.5
print('Some one has connected to me!')
# msg = b'sdfasfdfdb'
msg = b'x05x03x01x04?x99x99x9au%'
# print(msg)
start_time = time.perf_counter()
for j in range(1000):
j = j + 0.5
#msg = get_send_msgflowbytes(slave, func, register, length, j) # 实际上,这个函数花费了不少的时间。
# 每次最多接收1k字节:
# high_pricision_delay(0.001)
# print(msg)
# time.sleep(0.0000001)
client_socket.send(msg)
# client_socket.recv(1)
# client_socket.recv(20)
client_socket.send(b'sssssssssss')
end_time = time.perf_counter()
print('发送时间耗费', end_time - start_time)
tcp_server_socket.close()
if __name__=='__main__':
import threading
multi_send(5002)
#
# for i in range (5001,5011,1):
# t=threading.Thread(target=multi_send,args=(i,))
# t.start()
#
# tcp_server_socket.close()
接收脚本:
def tcp_recv_zmq_send(context,sub_server_addr,syncaddr,down_computer_addr,port):
# socketzmq = context.socket(zmq.PUB)
# socketzmq.bind("tcp://115.156.162.76:6000")
socketzmq = context.socket(zmq.PUB)
socketzmq.connect(sub_server_addr)
# #
# #为了等待远端的电脑的sub的内容全部都连接上来。进行的延迟
# time.sleep(3)
# 保证同步的另外的一种方案就是采用req-rep的同步
# sync_client = context.socket(zmq.REQ)
# sync_client.connect(syncaddr)
# #
# #发送同步信号
# sync_client.send(b'')
#
# #等待同步回应,完成同步
# sync_client.recv()
#为了定义一个对象线程
# 创建一个socket:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 建立连接:
s.connect((down_computer_addr, port))
# s.connect(('192.168.127.5', 5001))
print('we have connected to the tcp data send server!---port is :',port)
packagenum=0
zhanbao=0
buzhanbao=0
# start_time_clock = time.clock()
start_time_perf = time.perf_counter()
start_time_process = time.process_time()
count =0
#实际上应当启用的市多线程来做这些事情的
#每一个线程要做的事情就是接收对应的内容
#我想epics里面做的也是基本想同样的事情 ---最后写一个自动化的脚本多线程
while True:
b = s.recv(20)
# print(b)
if b[7] ==115:
print('ready to exit')
# socketzmq.send(b)
pass
break
# print(len(b))
# print(b)
# s.send(b'i')
# packagenum = packagenum + 1
# print(b)
size=len(b)
count = count + 1
# if count==10000:
# break
# r.set('name',b)
# f.write(str(b)+'n')
if size>10:
zhanbao = zhanbao + 1
# print(size)
else:
buzhanbao = buzhanbao + 1
# timestample = str(datetime.datetime.now()).encode()
# b = b + timestample
# print(len(b))
# socketzmq.send(b) #显然,zeromq 这句话几乎消耗了很多很多的时间
# x=socketzmq.recv()
print(packagenum)
# end_time_clock = time.clock()
end_time_perf = time.perf_counter()
end_time_process = time.process_time()
print('the port is: ',port)
# print('程序的clock time消耗: ',end_time_clock - start_time_clock)
print('程序_process',end_time_process- start_time_process) #process time 不包含time sleep 的
print('程序执行perf_count',end_time_perf-start_time_perf) #
print('tcp接收不粘包',buzhanbao)
print('tcp接收粘包',zhanbao)
socketzmq.close()
s.close()
if __name__ == '__main__':
print('Kaishile ')
context = zmq.Context() #这个上下文是真的迷,到底什么情况下要用共同的上下文,什么时候用单独的上下文,找时间测试清楚
sub_server_addr = "tcp://115.156.162.76:6000"
syncaddr = "tcp://115.156.162.76:5555"
down_computer_addr = '115.156.163.107'
# tcp_recv_zmq_send(context,sub_server_addr,syncaddr,down_computer_addr,5002)
#
# port=[5001,5002,5003,5004,5005,5006,5007,5008,5009,5010]
port = [5002, 5002,5002]
#
#
for i in port:
#
t2 = threading.Thread(target=tcp_recv_zmq_send,args=(context,sub_server_addr,syncaddr,down_computer_addr,i))
t2.start()
#
以上两个代码,可以通过修改代码,很方便变成多线程数据发送和多线程的数据接收,以验证这种IO密集型的网络程序的多线程的优势能够提高系统的数据的吞吐量。
3、考虑的额外的问题
python的多线程实际上是假的多线程,其仅仅能在一个核上,进行多线程的时间分片。但如果你的电脑是拥有多个核的,那么不好意思,你的电脑仅仅只能利用到其中的一个核。
4、测试结果:

上面的测试的结果的数量太少了,下面的测试的结果,以使得时间更长:
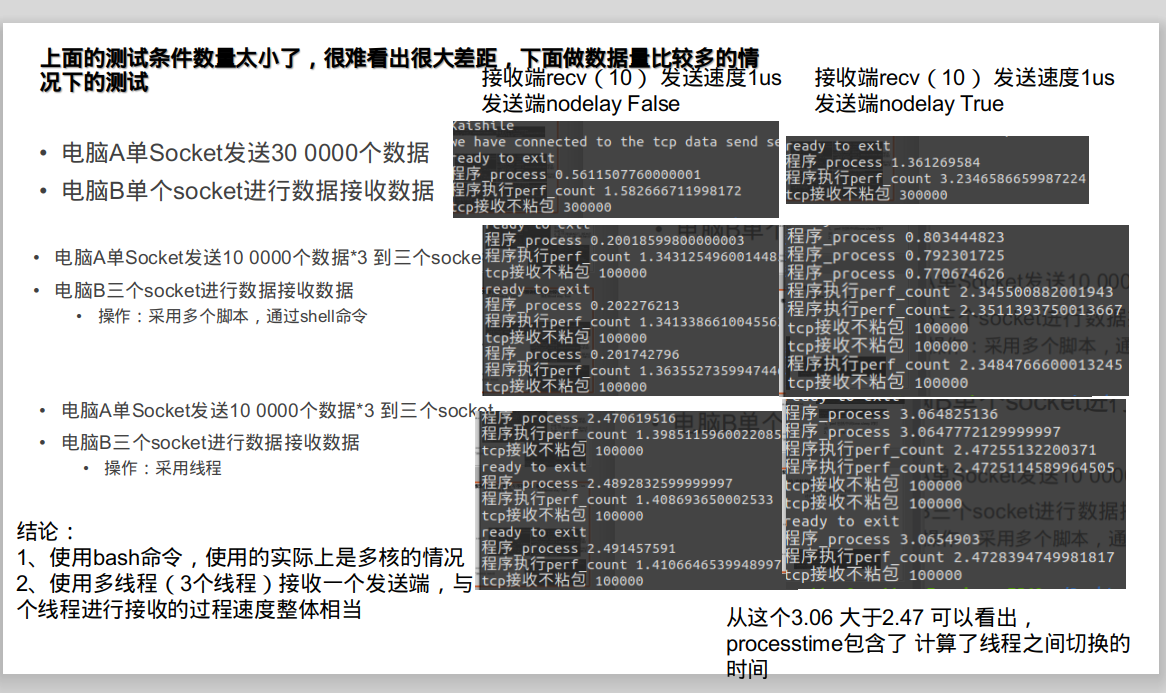
-----------------------------
以上是下位机上传的速度也就在1M/s,也就是10个字节的数据,每0.000 001s发送一次,共发送10 0000 多次
最后
以上就是无情机器猫最近收集整理的关于关于python通过tcp进行高速数据传输的全部内容,更多相关关于python通过tcp进行高速数据传输内容请搜索靠谱客的其他文章。






![setsockopt用法浅析[转]](https://www.shuijiaxian.com/files_image/reation/bcimg21.png)

发表评论 取消回复