前言:
之前实现的UCB算法只不过是一个最初的算法模型,现在我需要把该算法应用在商品推荐之上,因此,需要根据业务需求来修改次算法。修改过程中,有改动UCB算法的部分实现,因此,做了额外的测试来判断新的算法是否满足现在业务需求。
我的github:
我实现的代码全部贴在我的github中,欢迎大家去参观。
https://github.com/YinWenAtBIT
一、算法回顾:
1.1问题模型:
Multi-armedbandit问题,中文译名或叫做“多臂赌博机”问题。
在概率论中,多臂赌博机问题(有时也称为K臂/N臂赌博机问题),是一个赌徒需要在一排老虎机前决定拉动哪一个老虎机的臂,并且决定每个臂需要被拉动多少次的问题。每台老虎机提供的奖励是与它自身的奖励随机分布的函数相关的。赌徒的目标是最大限度地通过杠杆拉动序列,使得获得的奖励最大化。
二、应用场景:
2.1商品推荐:
商品推荐,目的是挑选出客户已经选择的喜欢的商品种类,并且保持有少量的未探测的商品种类被推送出来。
2.2客户反馈:
客户看到推送出来的商品之后,如果有反馈,会点击喜欢或者是不喜欢,然后更新给UCB,然而没有做出反应的商品种类理应更新为无反应,所以算法还需要修改。改成每一次选择N个品种之后,能够自动更新为喜爱度一般,或者说不讨厌也不喜欢。
其次,总计数的模式需要改变,以前的UCB算法是一次选择一个品种,现在这里一次选择N个品种,总计数需要修改为给客户推送的次数,这样可以避免总计数增长过快,导致过于频繁的选择新品种出现。
2.3初始状态:
最原始版本,初始时,总计数为0,各个品种的被选中计数counts也为0,value值同样为0 。使用这个模式去初始化推荐系统,就会导致所有的种类都必须先推送一次之后,才开始选择客户喜欢的商品推送(UCB算法特性决定,冷启动将遍历所有品种)。这样的结果对于推荐算法是不可取的,因为商品的种类太多,我们需要尽快把客户喜欢的商品推送出来
三、算法修改:
对于2.2中提到的每次挑选臂之后,客户没有反应的种类需要更新一次不喜欢也不讨厌的问题,我选择的是让选择臂之后,自动给每一个被选择的品种全部更新一次不喜欢也不讨厌的状态,并且给counts值加一。那么再遇上客户有反馈的时候,就把这个值修改回来即可。
初始状态问题,这个问题的解决方案很简单,给每一个品种一个初始counts数,虽然实际上它还没有被挑中过。对于totalcount的计数问题,增加了一个给totalcount加一的成员方法,每次调用select_arm_N的时候,调用该方法即可。
综上,新增的API如下:
UCB1(int init_totalcount, intinit_count, double init_value);
bool update_reset_last(string & key, double last, doubleres);
bool update_reset_last(constchar *start, doublelast, double res);
void set_totalcount(intnumber);
void add_totalcount(intnum);
新的成员:
int default_count;
double default_value;
这两个成员配合新的构造函数,目的是为每一个新增的Key设置初始化的counts与value。这样就避免了每次插入新的key的时候,都需要手动来修改初始化counts与value值。
四、性能测试
4.1 初始值counts如何设置
现在有了新的API,修改了初始的counts,那么算法是否还能按照我们所设想的方式运行呢,这就需要进行测试了。
检验入下特性:
1. 能否在客户反馈回喜欢的商品之后,开始推荐喜欢的商品
2. 保持大约20%-30%的新品种推荐
经过多次测试,有如下总结:
1. 客户选择喜欢的商品之后,算法将会开始推荐客户喜欢的商品,客户反馈的喜爱度越高,将会连续推荐的次数越多
2. 新品种的推荐取决于客户对于商品的喜爱度,如果客户第一次挑选的商品都非常喜爱,那么,新商品会在很晚才出现。如果客户返回的喜爱度是有梯度,有选择的,那么能保持20%-30%左右的新品种推荐率。
3. Counts的选择决定新商品出现的时机。在客户选择完喜爱的商品之后,将会连续出现客户喜爱的商品,直到新产品的bonus+初始value,大于喜爱产品的bouns加value之后,才会出现新产品,那么现在counts越小,新产品出现的越早,建议将初始counts设置在5-10之间,能保证30-80次选择之后,开始出现新的产品(这个时机是假设所有的商品都被选择喜爱,并且被更新值为1.0时才成立,实际使用时,由于更新的喜爱度有梯度,并且不会每一个都被选中喜爱,实际上的使用将会非常符合需求,已经模拟了用户的行为,并且选择了有梯度的反馈值)。
4.2 totalcounts更新多少次最好
Totalcount增加到什么时候为好?经过测试,以及已知的UCB算法特性,UCB算法将在对于每一个臂有了深入了解之后,将会一直选择最优的臂,这个与我们推荐算法的需求是相矛盾的,经过测试,在设置counts初始值为5-15的时候,进行选择的的次数在100-200次之内是最符合需求的。
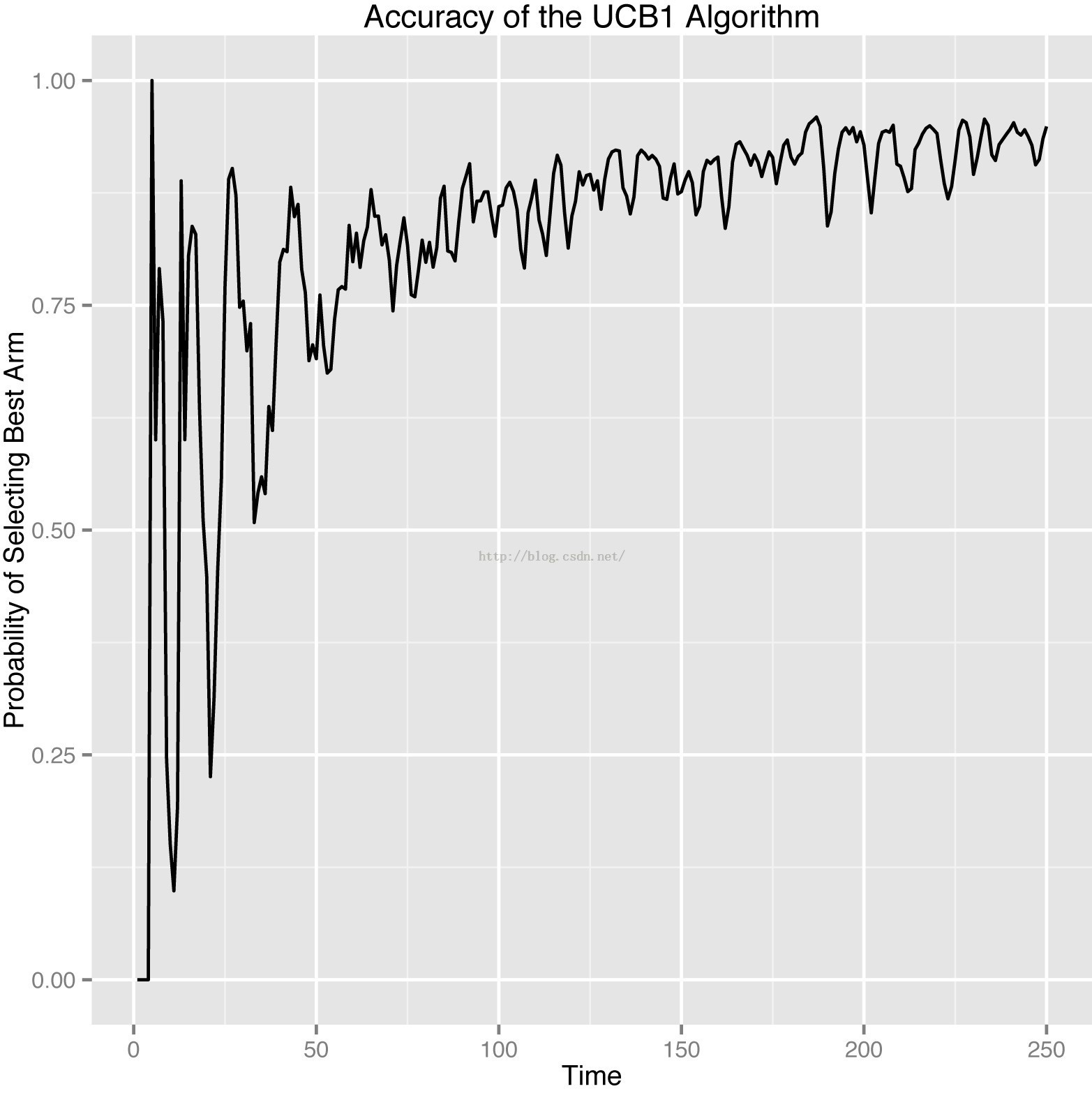
如此图中所示,我们最希望截取的是50-150之内的最优选择率。
4.3更新value值对于选择最优臂的影响
为了得到不同value值对喜爱商品的推送选择概率,模拟了真实客户实际使用情况下的反馈情况,对于同一个品种,即使喜欢,也不一定每次给出的反馈都是喜欢,同样可能是一般,或者是不喜欢。只不过喜欢的概率更大一些。同理对于不喜欢的商品也是如此。为得到更加接近真实用户的反馈情况,我们需要模拟真实客户的反应,然后观察整个推送效果。
模拟测试条件:
1. 推荐次数:100次
2. 每次推送数量:5个
3. 总商品品种:28个
4. 喜爱商品数量:5个,喜爱概率分别为:0.9, 0.8, 0.66,0.66,0.66,
5. 不喜爱商品数量:5个,讨厌概率等同于上方的喜爱概率
6. 一般商品:余下的所有商品,喜爱,一般,讨厌概率都为33%
7. 反馈更新值:一般为0.5,喜爱与讨厌偏离0.5相同幅度,例如1.0与0.0
8. 初始化counts值:5, 10 ,15
模拟测试结果:
表1. 喜爱商品被选中的概率,以及概率稳定性
| 选中概率与稳定性 | 更新值:1.0. 0.0 | 更新值:0.9. 0.1 |
| 初始Counts:5 | 68%, 10%范围波动 | 70%, 5%范围波动 |
| 初始Counts:10 | 74%, 10%范围波动 | 80%, 5%范围波动 |
| 初始Counts:15 | 82%, 10%范围波动 | 87%, 5%范围波动 |
结论:
由以上结果,我们可以得出一个该算法使用结论:
1. 初始的counts越大,喜爱商品被选中的概率越高,这与4.1中的结论是相符合的;
2. 更新值偏差越大,喜爱商品被推送的概率反而变小,这样违反直觉的结果主要还是由于对同一个商品的喜爱与不喜爱的反馈不是一个确定性因素导致的,如果先被选中了不喜爱,那么很难翻身。
3. 更新值的偏差越大,喜爱商品被选中的概率波动越大,解释与上面是想同的,由于选择是随机的,所以对于更新值设定有梯度是最好的。
有了如上结论,由于实际使用中,一定会对客户的反馈做一个梯度设置,那么我们只需要关心初始的counts值如何设置即可。另外对于totalcounts不能增加的过大的问题。我们可以对数据库设置一个过期时间即可。达到一定的totalcounts之后,我们重新开始即可。
总结:
学习算法的目的是为了实现业务,第一次实践为了特定的业务来修改算法的工作,感觉自己做的还挺不错的,满足了现有的需求,测试结果也非常理想。下一步就是加上Redis数据库,将这个算法彻底并入到整个业务逻辑中去了。
最后
以上就是直率招牌最近收集整理的关于算法实习生之路——根据需求修改UCB算法,测试UCB算法特性一、算法回顾:二、应用场景:三、算法修改:四、性能测试的全部内容,更多相关算法实习生之路——根据需求修改UCB算法内容请搜索靠谱客的其他文章。








发表评论 取消回复