伯努利分布:其均值是P,方差是p(1-p)
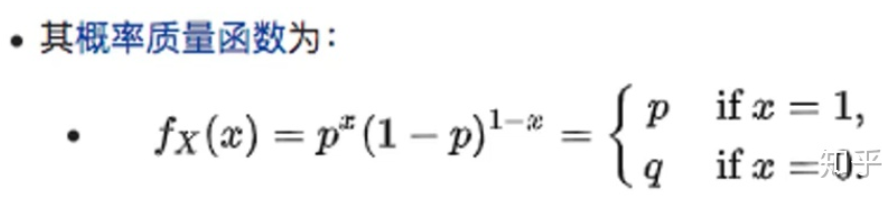
假设每一个新闻的CTR是固定的,将CTR从大到小排序,CTR最大的放在最显著的位置。
假设有四个新闻,但是不知道那个新闻用户更加喜欢,因此就给每个新闻25%的机会展示,但是真实的情况是用户最喜欢第一个新闻,那剩下的75%相当于就是占用了第一个新闻的展示资源。没有好好利用的那部分就被叫做 REGRET.
应用场景:online Learning
冷启动
匿名用户
怎么解决呢?将探索(explore)和利用(exploit) 结合,一边探索,一边利用.
第一个时间段,这四个新闻的展示概率相同,然后发现第一个新闻点击率更高。因此将第一个新闻的展示概率增大,剩下三个的展示概率减小。然后再通过点击率调整展示的概率。
(三)Bernoulli MAB 数学定义:
Bernoulli MAB 可以描述为一个二元组<A,R>:
- 有K个机器各自产生的奖励的概率为{θ1,....., θk}
- 在时间点t, 选择某一个机器,采取行动a ,获得奖励 r .
- A为行动的集合,其中任一个行动 a 产生的奖励 r 的数学期望Q(a)=E[r|a]= θ,如果在时间点t , 选中了对第 i 个机器采取行动 a_t,那么Q(a_t) = θ_i
- R为关于奖励的函数 , 在时间t ,收益r_i = R(a_t)的值为1的概率为Q(a_t) = θ_i ,值为0 的概率为 1- θ_i 。
- 算法的目标 是使得所有的行动的收益最大化
- 最优行动 a*对用的最有奖励的期望值θ* 为: θ* = Q(a*) = max θ_i ( for i in 1 to k )
- 算法的loss function为可能没有选择最优行动所导致的 regret 的和 L = E[Sum(θ*-Q(a_t)]
(四)MAB 问题的可能对策:
- 不探索 (no exploration)
- 随机探索 (random exploration)
- 选择不确定性大的机器去探索
以上是三种得到 θ 的方式。下面介绍epsilon -Greedy 算法
但是一个不关心组织的上下文无关(context free)bandit算法,它只管埋头干活,根本不观察一下面对的都是些什么样的arm。
UCB算法要解决的问题是:
面对固定的K个item(广告或推荐物品),我们没有任何先验知识,每一个item的回报情况完全不知道,每一次试验要选择其中一个,如何在这个选择过程中最大化我们的回报?
UCB解决这个Multi-armed bandit问题的思路是:用置信区间。置信区间可以简单地理解为不确定性的程度,区间越宽,越不确定,反之亦反之。
每个item的回报均值都有个置信区间,随着试验次数增加,置信区间会变窄(逐渐确定了到底回报丰厚还是可怜)。
每次选择前,都根据已经试验的结果重新估计每个item的均值及置信区间。
选择置信区间上限最大的那个item。
“选择置信区间上界最大的那个item”这句话反映了几个意思:
- 如果item置信区间很宽(被选次数很少,还不确定),那么它会倾向于被多次选择,这个是算法冒风险的部分;
- 如果item置信区间很窄(备选次数很多,比较确定其好坏了),那么均值大的倾向于被多次选择,这个是算法保守稳妥的部分;
- UCB是一种乐观的算法,选择置信区间上界排序,如果时悲观保守的做法,是选择置信区间下界排序。
UCB1算法
这里我们介绍一个最常见的bandit策略--UCB1算法,该算法的精神被认为是乐观地面对不确定性:我们首先猜测各臂可能给出的奖励,然后选择那个最高臂,如果实际的奖励较少,我们会尽快地降低对该臂的猜测,反之,我们就尽量多选择这个臂. 这里面的猜测,其实就是对各臂的奖励建立了一个指数,通过动态调整这个指数,我们最终将确定那个期望奖励最高的臂.

最后
以上就是听话小蚂蚁最近收集整理的关于MAB多臂老虎机的全部内容,更多相关MAB多臂老虎机内容请搜索靠谱客的其他文章。








发表评论 取消回复