接着考虑前文的10臂老虎机问题。假设我们可以与老虎机交互
T
T
T次,显然我们每次采取的行动(action)不必一成不变。记我们在
t
t
t时刻采取行动为
a
t
a_t
at,获得的回报为
R
(
a
t
)
R(a_t)
R(at)。那么,我们的目标是
max
a
1
,
a
2
,
.
.
.
,
a
T
∑
t
=
1
T
E
[
R
(
a
t
)
]
.
max_{a_1,a_2,...,a_T} sum_{t=1}^T E[R(a_t)].
a1,a2,...,aTmaxt=1∑TE[R(at)].
在实际应用中,
a
t
a_t
at会根据之前得到的
a
1
,
a
2
,
.
.
.
,
a
t
−
1
a_1,a_2,...,a_{t-1}
a1,a2,...,at−1和
R
(
a
1
)
,
R
(
a
2
)
,
.
.
.
,
R
(
a
t
−
1
)
R(a_1),R(a_2),...,R(a_{t-1})
R(a1),R(a2),...,R(at−1)进行优化调整。换句话说,
a
t
a_t
at是
a
1
,
a
2
,
.
.
.
,
a
t
−
1
a_1,a_2,...,a_{t-1}
a1,a2,...,at−1和
R
(
a
1
)
,
R
(
a
2
)
,
.
.
.
,
R
(
a
t
−
1
)
R(a_1),R(a_2),...,R(a_{t-1})
R(a1),R(a2),...,R(at−1)的函数。但是,
R
(
a
1
)
,
R
(
a
2
)
,
.
.
.
,
R
(
a
t
−
1
)
R(a_1),R(a_2),...,R(a_{t-1})
R(a1),R(a2),...,R(at−1)是随机的,因此
a
t
a_t
at必然也是一个随机变量,我们记为
A
t
A_t
At。同时,为了简化,我们记
R
t
=
R
(
A
t
)
R_t=R(A_t)
Rt=R(At)。那么上面的优化问题,可以重写为
max
A
1
,
A
2
,
.
.
.
,
A
T
∑
t
=
1
T
E
[
R
t
]
.
max_{A_1,A_2,...,A_T} sum_{t=1}^T E[R_t].
A1,A2,...,ATmaxt=1∑TE[Rt].
这里
A
t
A_t
At概率分布与
A
1
,
.
.
.
,
A
t
−
1
A_1,...,A_{t-1}
A1,...,At−1和
R
1
,
.
.
.
,
R
t
−
1
R_1,...,R_{t-1}
R1,...,Rt−1的取值有关。事实上,对
A
t
A_t
At概率分布调整的过程,就是学习的过程。一种简单的学习算法是
ϵ
epsilon
ϵ-贪心算法。其核心思想,是花费
T
ϵ
Tepsilon
Tϵ步的时间用来探索(explore),花费
T
−
T
ϵ
T-Tepsilon
T−Tϵ步的时间用来挖掘(exploit)。所谓探索,是指完全随机地选择行动
A
t
A_t
At,用以学习每个行动的回报期望。所谓发掘,是指根据当前已经观测到的数据,选择回报期望最高的行动。请看示例。
首先,我们以正态分布 N ( 0 , 1 ) N(0, 1) N(0,1)随机生成老虎机各个老虎臂的回报期望。
import numpy as npy
NUM_ARM = 10
mu = None
def init_arms():
global mu
mu = npy.random.normal(0, 1, NUM_ARM)
下面的方法用来生成按动第 a a a条老虎臂,产生的回报。假设第a条老虎臂的回报期望为 μ a mu_a μa,那么它的回报满足 N ( μ a , 1 ) N(mu_a, 1) N(μa,1)。
def get_reward(a):
return mu[a] + npy.random.normal(0, 1)
为了学习最优的策略,我们需要记录每次行动获得的回报。
record_average = None
record_num = None
def init_record():
global record_average
global record_num
record_average = npy.zeros(NUM_ARM)
record_num = npy.zeros(NUM_ARM, dtype=npy.int32)
上面的代码段定义了两个数组,record_average记录了到目前为止每个action回报的均值,record_num记录了到目前为止每个action执行的次数。每次我们执行一次action以后,都需要更新这两个数组。更新的方法也非常简单。
def update_record(a, r):
record_average[a] = (record_average[a] * record_num[a] + r) / (record_num[a] + 1)
record_num[a] += 1
有了上面的基础方法,我们就可以定义epsilon贪心算法了。
epsilon = .1
def epsilon_greedy():
if npy.random.uniform(0, 1) < epsilon:
return npy.random.randint(0, NUM_ARM - 1)
else:
return npy.argmax(record_average)
接下来定义主方法。
def run(T):
init_arms()
init_record()
for t in range(T):
a = epsilon_greedy()
r = get_reward()
update_record(a, r)
上面的方法实现了epsilon贪心算法的所有逻辑。但是,为了判断这个算法是否有效,我们需要对算法的性能进行评估。一个显而易见的参数,是评估每次操作中,选择最优action的频率。为此,我们对run方法稍加改动。
def run(T):
hits = []
init_arms()
init_record()
best_action = npy.argmax(mu)
for t in range(T):
a = epsilon_greedy()
r = get_reward(a)
update_record(a, r)
hits.append(1 if best_action == a else 0)
return hits
上面的代码返回了一个数组hits,它的第t个元素指明我们的第t个action是否最优。为了获得每个时刻执行最优action的频率,我们需要执行run方法多次。
def main(episode_num, T):
freq = npy.zeros(T, dtype=npy.int32)
for e in range(episode_num):
hits = run(T)
for t in range(T):
freq[t] += hits[t]
return freq
下面的代码画出最优action频率的曲线。
if __name__ == "__main__":
freq = main(1000, 500)
plt.plot(freq)
plt.show()
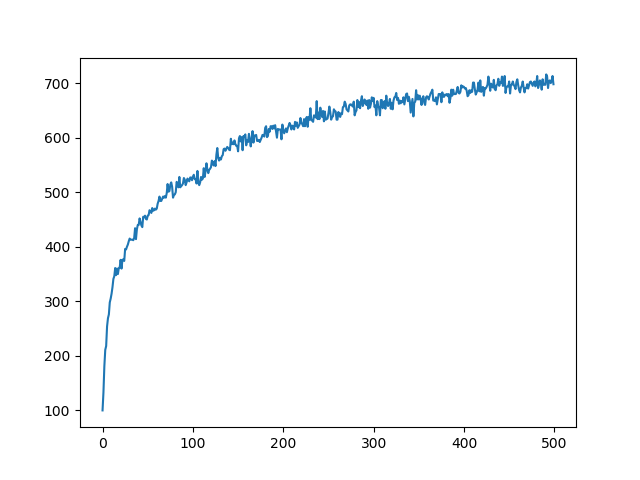
从上面图表可以看到,随着我们操作次数的增加,最优action的频率也相应增加。这说明我们的学习是有效的。
最后
以上就是小巧口红最近收集整理的关于强化学习第二:epsilon贪心算法的全部内容,更多相关强化学习第二内容请搜索靠谱客的其他文章。








发表评论 取消回复