导航
- 前文链接
- 合页损失函数
- 参考资料
前文链接
软间隔
合页损失函数
线性支持向量机还有另一种解释,最小化目标函数
∑
i
=
1
N
[
1
−
y
i
(
w
⋅
x
i
+
b
)
]
+
+
λ
∥
w
∥
2
sum_{i=1}^N[1-y_i(wcdot x_i+b)]_++lambdalVert wrVert^2
i=1∑N[1−yi(w⋅xi+b)]++λ∥w∥2
其中函数
L
(
y
(
x
⋅
x
+
b
)
)
=
[
1
−
y
(
w
⋅
x
+
b
)
]
+
L(y(xcdot x+b))=[1-y(wcdot x+b)]_+
L(y(x⋅x+b))=[1−y(w⋅x+b)]+
称为合页损失函数(hinge loss function),符号
+
+
+表示取函数的正部. 这种损失函数表示只有当样本点
(
x
i
,
y
i
)
(x_i, y_i)
(xi,yi)被正确分类且函数间隔
y
i
⋅
(
w
⋅
x
i
+
b
)
y_icdot(wcdot x_i+b)
yi⋅(w⋅xi+b)大于1时,损失为0,否则损失为
1
−
y
i
⋅
(
w
⋅
x
i
+
b
)
1-y_icdot(wcdot x_i+b)
1−yi⋅(w⋅xi+b)
定理:
线性支持向量机原始最优化问题
min
w
,
b
,
ξ
1
2
∥
w
∥
2
+
C
∑
i
=
1
N
ξ
i
s
.
t
.
{
y
i
(
w
⋅
x
i
+
b
)
≥
1
−
ξ
i
,
i
=
1
,
2
,
…
,
N
ξ
i
≥
0
,
i
=
1
,
2
,
…
,
N
(1)
min_{w, b, xi}frac{1}{2}lVert wrVert^2+Csum_{i=1}^Nxi_i\ s.t.begin{cases} y_i(wcdot x_i+b)geq 1-xi_i, i=1,2, dots, N\ xi_igeq 0, i=1, 2, dots, N end{cases}tag{1}
w,b,ξmin21∥w∥2+Ci=1∑Nξis.t.{yi(w⋅xi+b)≥1−ξi,i=1,2,…,Nξi≥0,i=1,2,…,N(1)
等价于最优化问题
min
w
,
b
∑
i
=
1
N
[
1
−
y
i
(
w
⋅
x
i
+
b
)
]
+
+
λ
∥
w
∥
2
(2)
min_{w, b}sum_{i=1}^N[1-y_i(wcdot x_i+b)]_++lambdalVert wrVert^2tag{2}
w,bmini=1∑N[1−yi(w⋅xi+b)]++λ∥w∥2(2)
证明:
可以将最优化问题
(
2
)
(2)
(2)转化为
(
1
)
(1)
(1). 令
[
1
−
y
i
(
w
⋅
x
i
+
b
)
]
=
ξ
i
[1-y_i(wcdot x_i+b)]=xi_i
[1−yi(w⋅xi+b)]=ξi
所以有
ξ
i
≥
0
xi_igeq 0
ξi≥0成立,又因为当
1
−
y
i
(
w
⋅
x
i
+
b
)
>
0
1-y_i(wcdot x_i+b)>0
1−yi(w⋅xi+b)>0时,
1
−
y
i
(
w
⋅
x
i
+
b
)
=
ξ
i
1-y_i(wcdot x_i+b)=xi_i
1−yi(w⋅xi+b)=ξi,当
1
−
y
i
(
w
⋅
x
i
+
b
)
≤
0
1-y_i(wcdot x_i+b)leq 0
1−yi(w⋅xi+b)≤0时,
ξ
i
=
0
xi_i=0
ξi=0,所以
y
i
(
w
⋅
x
i
+
b
)
≥
1
−
ξ
i
y_i(wcdot x_i+b)geq 1-xi_i
yi(w⋅xi+b)≥1−ξi. 即最优化问题可以写成
min
w
,
b
∑
i
=
1
N
ξ
i
+
λ
∥
w
∥
2
min_{w,b}sum_{i=1}^Nxi_i+lambdalVert wrVert^2
w,bmini=1∑Nξi+λ∥w∥2
令
λ
=
1
2
C
lambda=frac{1}{2C}
λ=2C1
min
w
,
b
1
C
(
1
2
∥
w
∥
2
+
C
∑
i
=
1
N
ξ
i
)
min_{w, b}frac{1}{C}bigg(frac{1}{2}lVert wrVert^2+Csum_{i=1}^Nxi_ibigg)
w,bminC1(21∥w∥2+Ci=1∑Nξi)
与模型
(
1
)
(1)
(1)等价.
合页损失函数和0-1损失函数图像如下
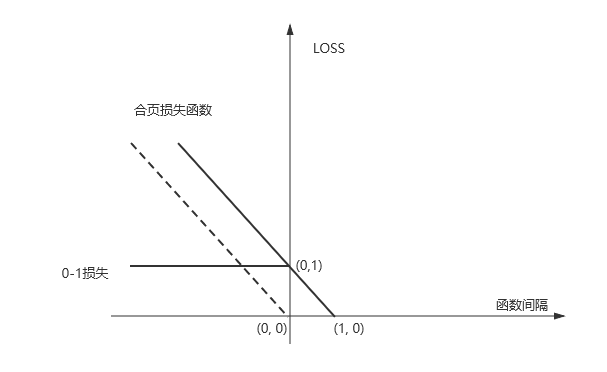 可以发现合页损失函数时0-1损失函数的上界,并且由于0-1损失函数不是连续可导的,直接优化目标函数比较困难,可以考虑优化损失函数的上界,这时上界损失函数又被称为代理损失函数(surrogate loss function).
可以发现合页损失函数时0-1损失函数的上界,并且由于0-1损失函数不是连续可导的,直接优化目标函数比较困难,可以考虑优化损失函数的上界,这时上界损失函数又被称为代理损失函数(surrogate loss function).
虚线部分时感知机损失函数
[
−
y
i
(
w
⋅
x
i
+
b
)
]
+
[-y_i(wcdot x_i+b)]_+
[−yi(w⋅xi+b)]+
相比较而言,合页损失函数不仅要求分类正确,还要求一定的函数间隔,损失才能达到0,是一种要求更高的损失函数.
参考资料
统计学习方法 清华大学出版社 李航
最后
以上就是传统楼房最近收集整理的关于【ML】SVM(4) 合页损失函数前文链接合页损失函数参考资料的全部内容,更多相关【ML】SVM(4)内容请搜索靠谱客的其他文章。

![机器学习 [合页损失函数 Hinge Loss]](https://www.shuijiaxian.com/files_image/reation/bcimg4.png)






发表评论 取消回复