GAN该部分知识点主要参考网上的视频资料,并用文字整理下来,方便以后查看。
在学习GAN之前需要知道这么一句话:“what I cannot create, I do not understand”
意思是 我们需要实战写一个GAN模型,才能理解GAN。
1 数据分布 p ( x ) p(x) p(x)
在说GAN之前需要了解什么是数据分布。
我们的目的是需要掌握数据的分布 p ( x ) p(x) p(x),才能创造该类型的数据。
那么对于一个数据集
p
(
x
)
p(x)
p(x)是什么样子的呢?我们之前学过的高斯、泊松、伯努利这些简单的分布不再适合大数据集。
可以断定
p
(
x
)
p(x)
p(x)不是我们已知的分布函数,长什么样子、参数我们也不知道,但是为了便于公式推导和模型算法描述,通常我们用
p
(
x
)
p(x)
p(x)来表示一个数据集的分布,仅仅是一个表示和辅助性的推理。(没人知道分布是什么)
即使是MINST数据集,我们也不知道 p ( x ) p(x) p(x)分布表达式是什么。通过降维到3维度,可以勉强画出来该数据集的分布 p ( x ) p(x) p(x),如下:
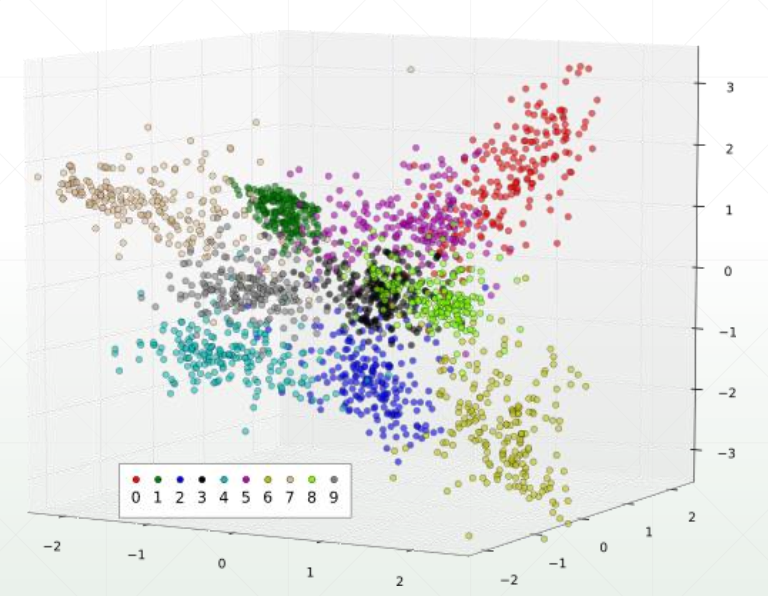
2 如何学习 p ( x ) p(x) p(x)
通过神经网络去逼近分布 p ( x ) p(x) p(x),一般是用生成器来生成,并用判别器来对抗训练。一个简单的GAN流程图为下,最后达到纳什均衡点。

最后使得生成器生成的 p g ( x ) ∼ p r ( x ) p_g(x)sim p_r(x) pg(x)∼pr(x)
3 GAN损失函数
怎么训练呢?损失函数为:
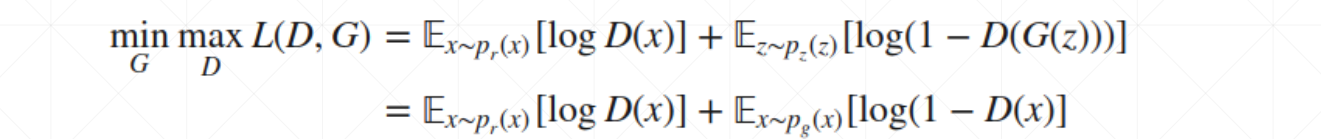
首先明白
min
G
min limits_G
Gmin表示对于G而言我们需要该公式取最小值。同理,
max
D
max limits_D
Dmax表示对于D而言,我们需要取得该公式最大值。E表示期望。
在上式中, p r ( x ) p_r(x) pr(x)表示实际样本数据, p z ( x ) p_z(x) pz(x)表示生成器生成的数据,z表示给的提示信息,如果没有就是随机噪声。详解可以看:GAN: 原始损失函数详解 。值得提出的是,对于生成器G ,需要骗过判别器D,使得 D ( G ( z ) ) D(G(z)) D(G(z))变大,那么整个公式就会变小,因而是 min G min limits_G Gmin。
4 如何实现?
x—>D—>D(x),其中D(x)是表示概率值,是一个标量
z—>G—>
x
g
′
x'_g
xg′—>D—>D(G(Z)),其中D(G(Z))也是一个标量。
这里推荐一个在线训练GAN模型的网站:GAN Playground 。进去可以看到,(生成器最开始是一个100随机维向量)。


5 如何收敛
5.1 先固定G,D如何收敛
根据上面GAN公式可以得到,其中E表示期望,
E
[
f
(
x
)
]
=
∫
p
(
x
)
f
(
x
)
d
x
E[f(x)]=int_{}p(x)f(x)dx
E[f(x)]=∫p(x)f(x)dx,则可以推导为:
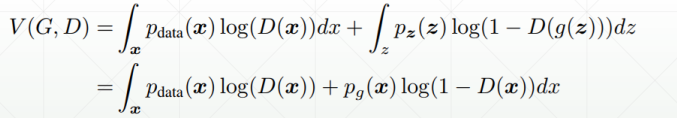
在这里,可以令
p
d
a
t
a
(
x
)
p_{data}(x)
pdata(x)是一个固定的值A,
p
g
(
x
)
p_{g}(x)
pg(x)也是个固定的值B,此时他们是与判别器D无关的,可以这么做。
那么当
V
(
G
,
D
)
V(G,D)
V(G,D)求极大值的时候,其导数为0。则有:

此时可以得出
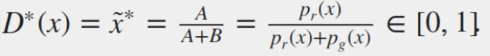
5.2 固定D,G如何收敛
介绍这部分,首先需要知道KL,JS散度的定义:
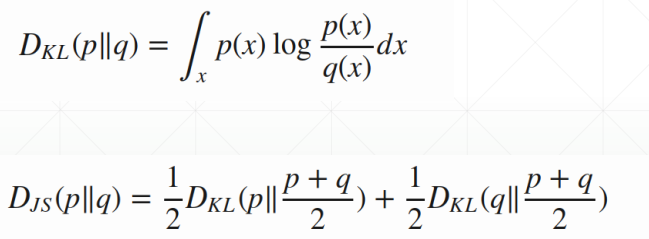
现在我们来计算下
D
J
S
(
p
∣
∣
q
)
D_{JS}(p||q)
DJS(p∣∣q),如下:
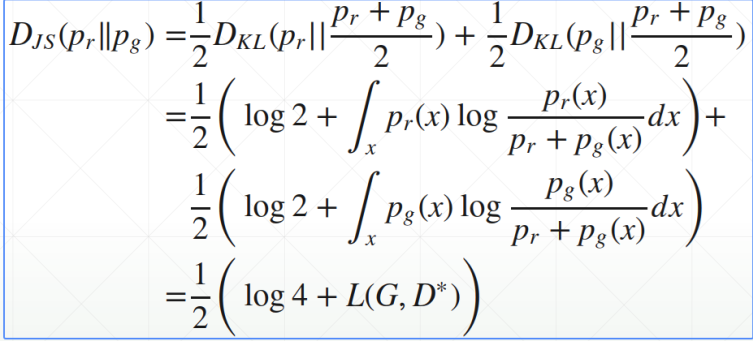
因此可以得到:
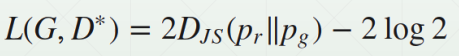
此时需要最小化该公式。该公式表示,当D固定好了,此时当
p
r
=
p
g
p_r=p_g
pr=pg取最小值,即生成器生成的数据和真实数据一致。(
D
J
S
(
p
∣
∣
q
)
≥
0
D_{JS}(p||q)geq 0
DJS(p∣∣q)≥0)
那么当 p r = p g p_r=p_g pr=pg时, D ∗ ( x ) = 1 2 D^*(x)=frac{1}{2} D∗(x)=21 ,便是纳什均衡。
6 A~Z GAN,越来越多的论文
GAN论文越来越多,一般都喜欢在GAN前面加上字母命名,变成自己的方法(A~Z GAN)。github上面由GAN论文集合:A~Z GAN
读其中一些经典的论文就可以。
6.1 DCGAN

6.2 如何稳定优化(WGAN)
p g p_g pg和 p d a t a p_{data} pdata几乎不会有重叠,因此不训练的话,生成器永远也不会生成一张和原始很像的数据。若P和Q完全没有重叠的分布,那么此时KL为 + ∞ +infty +∞, J S = l o g 2 JS=log2 JS=log2。优化会很困难,梯度会弥散无法更新。因此GAN在训练前期会不稳定。
WGAN可以很好解决这个问题,即不在相关的区域也可以慢慢优化。

可以看出,在DCGAN中,JS的损失一直都没有优化。因此引入了Wasserstein距离。
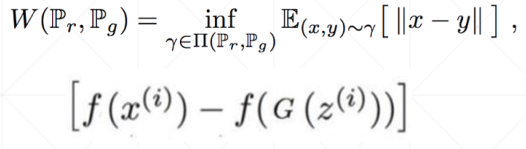

上式中
f
f
f是一个神经网络,需要学习,是沃森距离。之前是D~JS,现在是
f
D
f_D
fD ~WD,主要解决前期不好训练的问题。
6.3 扩展版本 WGAN-Gradient Penalty
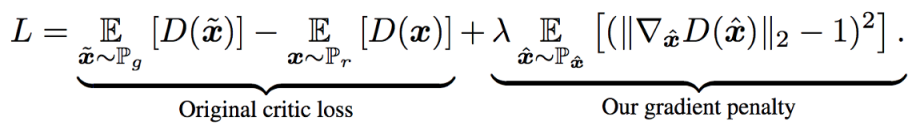
公式右边项是正则化。可以解决GAN训练不稳定的问题,同时效果也不错。
GAN不稳定的根本原因就是,初始的 p z p_z pz和原始的分布 p r p_r pr分布不重合的时候,训练梯度弥散。
下一部分就是,用Pytorch来实战。深度学习:GAN(2)
最后
以上就是现实冬天最近收集整理的关于深度学习:GAN(1)的全部内容,更多相关深度学习内容请搜索靠谱客的其他文章。








发表评论 取消回复