DecisionTreeClassifier之predict_proba(self,X)
通过今日调试代码的过程发现自己对决策树代码的理解还是不够深刻,今天Mark一下。
问题:
按道理讲。调用DecisionTreeClassifier的predict_proba(X_test)方法可以得到每个样本属于不同类别的概率。并且概率和相加等于1.但是输出predict_proba(X_test)的结果发现,假设类别为6 ,对于单个样本属于不同类的概率变为[0,0,0,1,0,0],当时就懵了,说好的概率呢,怎么变成定值了???
下面是示例代码和解决方案:
示例代码:
from sklearn.datasets import load_iris
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import fetch_mldata
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
# 获取数据集
iris=load_iris()
X,y=iris["data"],iris["target"]
# 对数据进行归一化处理
X=preprocessing.scale(X)
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=.4,random_state=42)
# 定义决策树的参数
clf=DecisionTreeClassifier(random_state=0)
#修改后
#clf=DecisionTreeClassifier(random_state=0,min_samples_leaf=10)
# 训练数据集
clf.fit(X_train,y_train)
# 可视化树模型
with open("D:/PycharmProjects/forestSeeGrowingDcTree/BreastCancer.dot",'w') as f:
f=tree.export_graphviz(clf,out_file=f)
# 预测模型的有效性
content=clf.predict_proba(X_test)
print(content)
# 把这个predict_proba存起来
from pandas import DataFrame
data = DataFrame(content)
data.to_csv('D:PycharmProjects/forestSeeLabel/BreastCancer.csv')上述得到的结果为(一部分):
下面第一行为标签值值,第二列为样本的序号
0 1 2
0,0.0,1.0,0.0
1,1.0,0.0,0.0
2,0.0,0.0,1.0
3,0.0,1.0,0.0
4,0.0,1.0,0.0
5,1.0,0.0,0.0
6,0.0,1.0,0.0
7,0.0,0.0,1.0
8,0.0,0.0,1.0
9,0.0,1.0,0.0
10,0.0,0.0,1.0
11,1.0,0.0,0.0
12,1.0,0.0,0.0
13,1.0,0.0,0.0
14,1.0,0.0,0.0
15,0.0,1.0,0.0
16,0.0,0.0,1.0
把训练出来的树拿过来看一下究竟
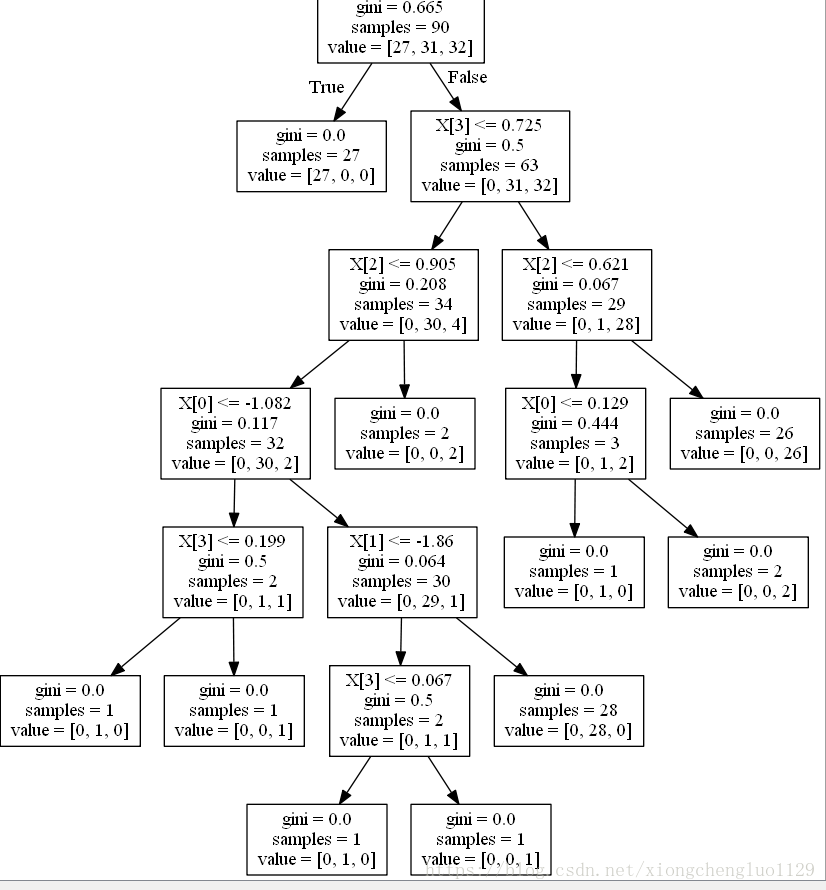
有没有发现什么问题???
咋一看确实没有,可是仔细分析就会发现,这可决策树的每一个叶子节点的样本都是属于同一类的,叶子结点gini值为全都为0,即,树是完全生长的,那么当采用新样本进行测试的时候,每个测试样本落入的节点一定是纯的,那么单个样本点的如厕概率就是[0,,0,0,1,0,0],即明确属于某一类,那么得到的概率当然是在某一类上取的最大值,·1.
为了避免这个问题,可以设置决策树的,min_samples_leaf=10,下面来看一下predict_proba的概率输出以及fit完之后的树
概率输出如下:
,0,1,2
0,0.0,0.7142857142857143,0.2857142857142857
1,1.0,0.0,0.0
2,0.0,0.0,1.0
3,0.0,0.7142857142857143,0.2857142857142857
4,0.0,0.7142857142857143,0.2857142857142857
5,1.0,0.0,0.0
6,0.0,1.0,0.0
7,0.0,0.1,0.9
8,0.0,0.7142857142857143,0.2857142857142857
9,0.0,1.0,0.0
10,0.0,0.1,0.9
11,1.0,0.0,0.0
12,1.0,0.0,0.0
13,1.0,0.0,0.0
14,1.0,0.0,0.0
15,0.0,0.7142857142857143,0.2857142857142857
16,0.0,0.0,1.0
17,0.0,1.0,0.0
18,0.0,0.7142857142857143,0.2857142857142857生成的决策树如下:
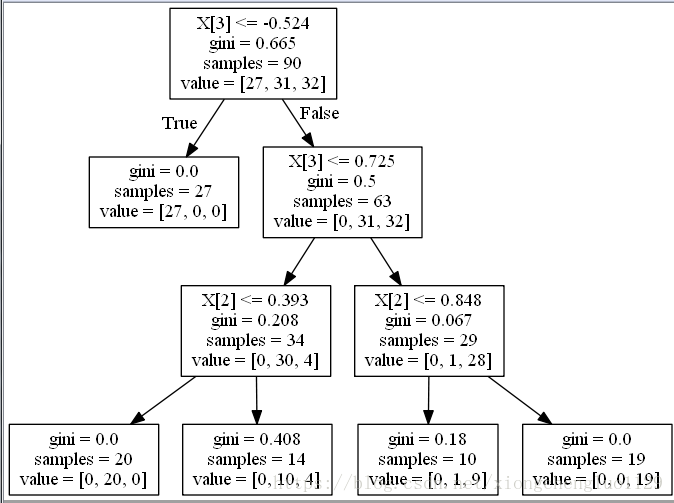
这样当用新样本进行测试的时候,样本落到决策树的叶子节点不一定是属于同一类的,那么概率就可以计算出来了,而不仅仅就只是1.
经过今天的习练,我发现我发现问题和解决问题的能力有所提高。加油继续努力!
最后
以上就是糟糕小蝴蝶最近收集整理的关于DecisionTreeClassifier的predict_proba(self,X)踩坑记的全部内容,更多相关DecisionTreeClassifier内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复