一、大数据的三个发展方向
- 平台搭建/优化/运维/监控
- 大数据开发/设计/架构
- 数据分析/挖掘。
二、大数据的4V特征:
- 数据量大,TB->PB
- 数据类型繁多,结构化、非结构化文本、日志、视频、图片、地理位置等;
- 商业价值高,但是这种价值需要在海量数据之上,通过数据分析与机器学习更快速的挖掘出来;
- 处理时效性高,海量数据的处理需求不再局限在离线计算当中。
现如今,正式为了应对大数据的这几个特点,开源的大数据框架越来越多,越来越强,先列举一些常见的:
- 文件存储:HDFS、Alluxio(Tachyon)、oss、s3a、KFS
- 离线计算:MR、Spark
- 流式、实时计算:Storm、Spark Streaming、S4、HeronK-V、NOSQL
- 数据库:HBase、PostgreSQL 、Redis、MongoDB,ES
- 资源管理:YARN、Mesos
- 日志收集:Flume、Logstash、Kibana、Scribe
- 消息系统:Kafka、StormMQ、ZeroMQ、RabbitMQ
- 查询分析:Hive、Impala、Phoenix、SparkSQL、Flink、Drill、Kylin、Apache Druid、Pig、Presto
- 分布式协调服务:Zookeeper
- 集群管理与监控:Ambari(HDP)、Cloudera Manager(CDH)、Ganglia、Nagios
- 数据挖掘、机器学习:Spark ML、TensorFlow、Pytorch、Mahout
- 数据同步:Sqoop、DataX、Kettle;
- 实时同步:canal、otter、Maxwell
- 任务调度:Oozie、Azkaban、xxljob、……
眼花了吧,上面的有30多种吧,别说精通了,全部都会使用的,估计也没几个。
三、第二个方向(开发/设计/架构)
3.1、初识Hadoop
3.1.1、Spark
3.2、Hive vs SparkSql
3.3、海量数据如何到HDFS上
此处也可以叫做数据采集,把各个数据源的数据采集到Hadoop上。
3.3.1、 HDFS PUT命令
put命令在实际环境中也比较常用,通常配合shell、python等脚本语言来使用。建议熟练掌握。
3.3.2、 HDFS API
HDFS提供了写数据的API,自己用编程语言将数据写入HDFS,put命令本身也是使用API。
际环境中一般自己较少编写程序使用API来写数据到HDFS,通常都是使用其他框架封装好
的方法。比如:Hive中的INSERT语句,Spark中的saveAsTextfile等。
建议了解原理,会写Demo。
3.3.3、 Sqoop
Sqoop是一个主要用于Hadoop/Hive与传统关系型数据库Oracle/MySQL/SQLServer等之间进行数据交换的开源框架。
就像Hive把SQL翻译成MapReduce一样,Sqoop把你指定的参数翻译成MapReduce,提交到Hadoop运行,完成Hadoop与其他数据库之间的数据交换。
自己下载和配置Sqoop(建议先使用Sqoop1,Sqoop2比较复杂)。
了解Sqoop常用的配置参数和方法。
用Sqoop完成从MySQL同步数据到HDFS;使用Sqoop完成从MySQL同步数据到Hive表;
PS:如果后续选型确定使用Sqoop作为数据交换工具,那么建议熟练掌握,否则,了解和会用Demo即可。
3.3.4、 Flume
Flume是一个分布式的海量日志采集和传输框架,因为“采集和传输框架”,所以它并不适合关系型数据库的数据采集和传输。
Flume可以实时的从网络协议、消息系统、文件系统采集日志,并传输到HDFS上。
因此,如果你的业务有这些数据源的数据,并且需要实时的采集,那么就应该考虑使用Flume。
Flume监控一个不断追加数据的文件,并将数据传输到HDFS;
PS:Flume的配置和使用较为复杂,如果你没有足够的兴趣和耐心,可以先跳过Flume。
3.3.5、阿里开源的DataX
现在DataX已经是3.0版本,支持很多数据源。
你也可以在其之上做二次开发。
PS:有兴趣的可以研究和使用一下,对比一下它与Sqoop。
3.4、把Hadoop上的数据搞到别处去
3.4.1、 HDFS GET命令
把HDFS上的文件GET到本地。需要熟练掌握。
3.4.2、 HDFS API
3.4.3、 Sqoop
sqoop完成将HDFS上的文件同步到MySQL;使用Sqoop完成将Hive表中的数据同步到MySQL;
3.4.4 DataX
3.5、数据的一次采集、多次消费。
3.5.1、Kafka
3.6、任务调度系统
3.6.1、Oozie
3.7、实时: Strom vs SparkStreaming vs Flink
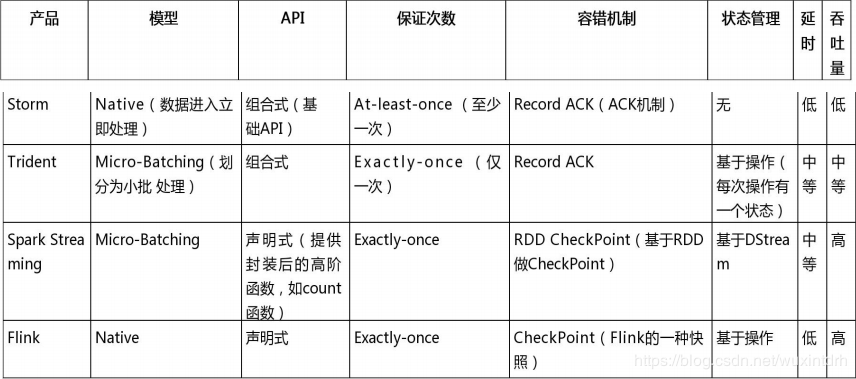
如果一个项目除了实时计算,还包括了离线批处理、交互式查询等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,应首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性。
3.7.1、storm vs sparkStreaming 待完善。。。
3.8、数据要对外
3.10、机器学习
Reference:
- https://blog.csdn.net/zytbft/article/details/79285500
关注我的公众号[宝哥大数据]

最后
以上就是温暖黑猫最近收集整理的关于大数据开发 岗位需要的知识一、大数据的三个发展方向二、大数据的4V特征:三、第二个方向(开发/设计/架构)的全部内容,更多相关大数据开发内容请搜索靠谱客的其他文章。








发表评论 取消回复