文章目录
- 数据格式
- 基本用法
- 格式转换
- 张量操作
- mask相关
- tensor变形
- 查看模型参数
- 显式共享参数
- grad相关
- dataloader
- 难理解的用法
数据格式
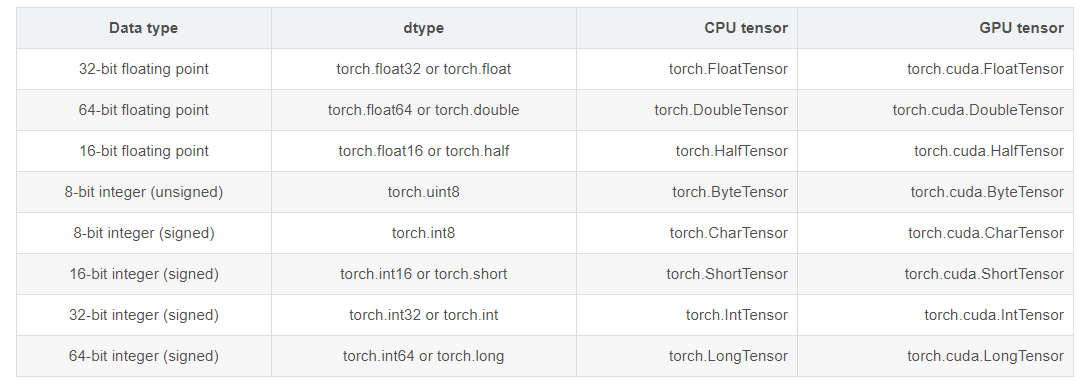
dtype: tensor的数据类型,总共有八种数据类型。
其中默认的类型是torch.FloatTensor,而且这种类型的别名也可以写作torch.Tensor
基本用法
格式转换
典型的tensor构建方法:
torch.tensor(data, dtype=None, device=None, requires_grad=False)
从其他形式转换而来:
torch.as_tensor(data, dtype=None, device=None)
torch.from_numpy() 把numpy变为torch格式
b = np.triu(np.ones([2,3,4]),k=1)
a = torch.from_numpy(b).byte() # 变为byte类型,无符号整型,1字节,8位
print(a)
tensor([[[0, 1, 1, 1],
[0, 0, 1, 1],
[0, 0, 0, 1]],
[[0, 1, 1, 1],
[0, 0, 1, 1],
[0, 0, 0, 1]]], dtype=torch.uint8)
张量操作
torch.Tensor.expand(*sizes) → Tensor,函数返回张量在某一个维度扩展之后的张量,就是将张量广播到新形状。函数对返回的张量不会分配新内存,即在原始张量上返回只读视图,返回的张量内存是不连续的。
import torch
x = torch.tensor([1, 2, 3, 4])
xnew = x.expand(2, 4)
print(xnew)
返回:
tensor([[1, 2, 3, 4],
[1, 2, 3, 4]])
mask相关
获得mask
mask_attn = torch.tensor([10,2,4,1])
mask_attn .data.eq(1)
返回:
tensor([False, False, False, True])
填充masked
torch.masked_fill_()
scores = torch.masked_fill_(attn_mask, -1e9)
获得上三角矩阵
torch.ones(*sizes, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False),获得全为1的矩阵
numpy.triu(m, k=0),获取矩阵v的上三角形,k表示对角线起始位置
>>> np.triu(np.ones([2,3,4]),k=0)
array([[[1., 1., 1., 1.],
[0., 1., 1., 1.],
[0., 0., 1., 1.]],
[[1., 1., 1., 1.],
[0., 1., 1., 1.],
[0., 0., 1., 1.]]])
>>> np.triu(np.ones([2,3,4]),k=1)
array([[[0., 1., 1., 1.],
[0., 0., 1., 1.],
[0., 0., 0., 1.]],
[[0., 1., 1., 1.],
[0., 0., 1., 1.],
[0., 0., 0., 1.]]])
>>> np.triu(np.ones([2,3,4]),k=-1)
array([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[0., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[0., 1., 1., 1.]]])
获得下三角矩阵
同理,获得下三角:numpy.tril(m, k=0)
>>> np.tril(np.ones([2,3,4]),k=0)
array([[[1., 0., 0., 0.],
[1., 1., 0., 0.],
[1., 1., 1., 0.]],
[[1., 0., 0., 0.],
[1., 1., 0., 0.],
[1., 1., 1., 0.]]])
>>> np.tril(np.ones([2,3,4]),k=1)
array([[[1., 1., 0., 0.],
[1., 1., 1., 0.],
[1., 1., 1., 1.]],
[[1., 1., 0., 0.],
[1., 1., 1., 0.],
[1., 1., 1., 1.]]])
tensor变形
维度拆分
善用view(), transpose(), 组合
比如维度为:Q: [bs, seq_len, d_model]
# 公共变量包含这些维度
d_k = 64
n_heads = 12
# 要拆解的维度用乘法表示
self.W_Q = nn.Linear(d_model, n_heads * d_k)
# 拆解ing
Q_s = self.W_Q(Q).view(bs, -1, n_heads, d_k).transpose(1,2) # [bs, seq_len, n_heads, d_k] => [bs, n_heads, seq_len, d_k]
# 变回来
Q = Q_s.transpose(1,2).contiguous().view(bs, -1, n_heads * d_k)
维度拓展
善用unsqueeze(), repeat(), expand()组合
# attn_mask : [bs, seq_len, seq_len]
attn_mask = attn_mask.unsqueeze(1).repeat(1,n_heads,1,1) # [bs, n_heads, seq_len, seq_len]
[,None],None可以在所处维度中多一维,None 功能类似torch.unsqueeze(),方便扩展维度,而不改变数据排列顺序。
tensor = torch.randn(3, 4)
print('tensor size:', tensor.size())
tensor_1 = tensor[:, None]
print('tensor_1 size:', tensor_1.size())
tensor_2 = tensor[:, :, None]
print('tensor_2 size', tensor_2.size())
tensor size: torch.Size([3, 4])
tensor_1 size: torch.Size([3, 1, 4])
tensor_2 size torch.Size([3, 4, 1])
随后配合expand()也可以增维
tensor_3 = tensor_1 .expand(-1, 5, -1)
print(tensor_3.shape)
torch.Size([3, 5, 4])
数据填充
python的extend(),可以实现对list的填充
test_e = [0,1,2,3,4]
test_e.extend([0]*(-2))
print(test_e)
test_e.extend([0]*(2))
print(test_e)
[0, 1, 2, 3, 4]
[0, 1, 2, 3, 4, 0, 0]
查看模型参数
参数预备知识
首先可以把这个函数理解为类型转换函数,将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面(net.parameter()中就有这个绑定的parameter,所以在参数优化的时候可以进行优化的)
模型初始定义与准备

如上图所示的函数模型,下面先进行实例化
# 实例化模型
test_model = MultiHeadAttention()
test_q = torch.randn([2,3,d_model])
test_k = torch.randn([2,3,d_model])
test_v = torch.randn([2,3,d_model])
test_attn_mask = torch.ones([2,3,3]).eq(0)
# 前向传播
test_output = test_model(test_q, test_k, test_v,test_attn_mask)
print(test_output)
tensor([[[-0.5667, -1.0205, -0.6333, ..., -0.1393, -1.5211, -0.5322],
[ 1.2822, -0.0590, -1.0420, ..., -0.4502, 0.9094, -0.6748],
[ 1.3240, -0.0684, -0.8500, ..., -0.1037, -0.4918, 0.3191]],
[[-0.0728, -1.8602, -1.2826, ..., 1.4858, -0.5083, -0.3816],
[-2.2272, 0.7091, 1.7966, ..., 0.3600, 1.2025, 0.1587],
[-0.5354, -0.0968, -1.3481, ..., -0.9842, -0.4214, 0.4423]]],
grad_fn=<NativeLayerNormBackward>)
1. 直接输出模型:
print(test_model)
MultiHeadAttention(
(W_Q): Linear(in_features=768, out_features=768, bias=True)
(W_K): Linear(in_features=768, out_features=768, bias=True)
(W_V): Linear(in_features=768, out_features=768, bias=True)
)
注意这里的bias=True,因此下文中,三个隐藏层,有了6个参数。也就是说,如果设置了bias=False,那么就只有3个参数。设置bias的方法就是在定义的时候设置bias=0,如:
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=0)
2. 用函数输出参数
model.named_parameters(), model.state_dict()
# 两种方式输出输出参数
for name, param in test_model.named_parameters(): # .named_parameters()输出参数
if param.requires_grad:
print(name,':',param.size())
print(test_model.state_dict) # model.state_dict()输出参数
W_Q.weight : torch.Size([768, 768])
W_Q.bias : torch.Size([768])
W_K.weight : torch.Size([768, 768])
W_K.bias : torch.Size([768])
W_V.weight : torch.Size([768, 768])
W_V.bias : torch.Size([768])
<bound method Module.state_dict of MultiHeadAttention(
(W_Q): Linear(in_features=768, out_features=768, bias=True)
(W_K): Linear(in_features=768, out_features=768, bias=True)
(W_V): Linear(in_features=768, out_features=768, bias=True)
)>
list(model.parameters())
- 用model.parameters()的话,与model.named_parameters()的区别就是不会输出参数名。
- 如果直接model.parameters()的话会是一个< generator>,因此要
list()一下
paras = list(test_model.parameters())
for num,param in enumerate(paras):
print('number:', num, param.shape)
number: 0 torch.Size([768, 768])
number: 1 torch.Size([768])
number: 2 torch.Size([768, 768])
number: 3 torch.Size([768])
number: 4 torch.Size([768, 768])
number: 5 torch.Size([768])
计算模型总参数量
关键用到参数的param.numel()这个函数
total_params = sum(p.numel() for p in model.parameters())
print(f'{total_params:,} total parameters.')
total_trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'{total_trainable_params:,} training parameters.')
43,748,354 total parameters.
43,748,354 training parameters.
显式共享参数
def __init__(self):
super(BERT, self).__init__()
self.embedding = Embedding() # Embedding里有token_embed这个自定义变量
# fc2和embedding layer共享参数
embed_weight = self.embedding.tok_embed.weight
self.fc2 = nn.Linear(d_model, vocab_size, bias=False)
self.fc2.weight = embed_weight
grad相关
参考:https://www.cnblogs.com/yjphhw/p/9794197.html
参考2:https://blog.csdn.net/scarletteshu/article/details/107556727
torch.Tensor 是torch库的核心类。如果你把Tensor类的 .requires_grad设置为True,它就会计算其上的梯度。 当你计算完所有的值后使用 .backward() 就可以自动的计算所有的导数。 该张量的梯度会累加到 .grad属性。
而Function是一个对自动求导实现非常关键的类。
Tensor 和Function互相连接起来,构建了一个无圈图,对所有的历史进行了编码。每个张量都有一个叫 .grad_fn 的属性,是生成该tensor的Function的索引(而那些由我们创建的Tensor的.grad_fn是None)
Tensor类
data:保存Variable所包含的Tensor。grad:保存data对应的梯度,类型为Variable,形状与data一致。(梯度是函数对变量的敏感程度)grad_fn:指向一个Function对象,我们可以通过它使用反向传播计算输入的梯度。requries_grad:是否需要对该Tensor进行自动求导,它将开始跟踪其上的所有操作(比如加减乘除等等计算)。backward():运算并生成当前Tensor的叶子Tensor的梯度,其梯度值会保存在叶子Tensor的.grad属性中
从0.4版本开始,为了简化使用,PyTorch就将Variable类合并到Tensor中去了,因此我们现在可以直接通过Tensor来使用Autograd模块提供的功能。
要使用Autograd,我们只需在创建Tensor时设置属性requries_grad为True即可,就表明我们需要对该Tensor进行自动求导,PyTorch会记录该Tensor的每一步操作历史并自动计算。
x = torch.ones(2, 2, requires_grad=True)
print(x,'n')
y = nn.Linear(2,1)(x)
print(y) # y 是有运算产生的张量,所以它有grad_fn
print(y.grad_fn)
y = x+y
print(y,'n') # grad_fn=<AddBackward0>)
z = x*y*3
out = z.mean()
print(z, out)
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
tensor([[0.7538],
[0.7538]], grad_fn=<AddmmBackward>)
<AddmmBackward object at 0x0000023193FD18C8>
tensor([[1.7538, 1.7538],
[1.7538, 1.7538]], grad_fn=<AddBackward0>)
tensor([[5.2613, 5.2613],
[5.2613, 5.2613]], grad_fn=<MulBackward0>) tensor(5.2613, grad_fn=<MeanBackward0>)
查看.grad和.grad_fn
print('forward output grad_fn:',output.grad_fn)
print('forward output grad:',output.grad)
print('forward output requires_grad:',output.requires_grad,'n')
forward output grad_fn: <AddBackward0 object at 0x0000023193C4EF88>
forward output grad: None
forward output requires_grad: True
自动求导
requires_grad ()设置为True或者False。它将开始跟踪其上的所有操作(比如加减乘除等等计算)。
- 完成计算后,可调用
.backward()自动计算所有梯度。此Tensor的梯度将累积到.grad属性中。 - 如果没有提供.requires_grad参数的话,输入的标志默认是False。
a.requires_grad_(True)
或者:
x = torch.ones(2, 2, requires_grad=True)
停止梯度计算
with torch.no_grad(),停止自动的梯度计算,即使tensor的属性.requires_grad=True,如:
with torch.no_grad():
print((x ** 2).requires_grad)
取消求导
调用.detach()将tensor与梯度跟踪断开连接,防止其未来计算被跟踪
后向传播
参考:https://www.cnblogs.com/laiyaling/p/12343844.html
backward(),对最后的Tensor执行backward()函数,会计算之前参与运算并生成当前Tensor的叶子Tensor的梯度。其梯度值会保存在叶子Tensor的.grad属性中。
- 默认同一个运算得到的Tensor仅能进行一次backward()。若要再次进行backward(),则要再次运算得到的Tesnor。
- 当多个Tensor从相同的源Tensor运算得到,这些运算得到的Tensor的backwards()方法将向源Tensor的grad属性中进行数值累加。
也就是说,比如叶子节点x1计算得到Tensor L1,假设有另一个tensor L2是通过对x1的运算得到的,那么L2.backward()执行后梯度结果将累加到x1.grad中。
- 只有叶子tensor(自己创建不是通过其他Tensor计算得来的)才能计算梯度。否则对于非叶子的x1执行L.backward()后,x1.grad将为None。
定义叶子节点时需注意要直接用torch创建且不能经过tensor计算。
dataloader
很好的讲解:https://www.cnblogs.com/marsggbo/p/11298644.html
用于生成自定义的数据集产生器。
首先,要自定义类DataSet(),要包含__len__,__getitem__ 两个函数
然后生成自己的Dataloader:Data.DataLoader(DataSet(), batch_size, True)
# 这里的input_ids, segment_ids, masked_tokens, masked_pos, isNext记得是bs相同的Tensor
loader = Data.DataLoader(MyDataSet(input_ids, segment_ids, masked_tokens, masked_pos, isNext), batch_size, True)
batch_size自定义数据产生与测试
首先,要定义好能产生一个batch大小的函数,比如自定义一个叫make_data()的函数。
在测试forward()的时候,可以先用loader生成一批batch_size大小的数据来进行测试,具体方法有两种。
第一种,用iter(loader) 配合next(iter(loader)来产生数据:
- 首先,
iter(loader),把loader转换为可迭代类型data_iter = iter(loader) - 然后通过
next(iter)产生batch_size大小的数据x,x,x,x,x = next(data_iter) - forward()测试
z, y = model(x,x,x) # 来自上面的结果
第二种,循环时用enumerate(dataLoader)来枚举。
总结第一种、第二种方法,可以参考这里的写法:
## 初始化
sampler = Sampler()
dataSet = DataSet(sampler) # __getitem__
dataLoader = DataLoader(dataSet, sampler) / DataIterable() # __iter__()
dataIterator = DataLoaderIter(dataLoader) #__next__()
data_iter = iter(dataLoader)
## 遍历方法1
for _ in range(len(data_iter))
data = next(data_iter)
## 遍历方法2
for i, data in enumerate(dataLoader):
data = data
难理解的用法
torch.gather()
讲解1(好):https://blog.csdn.net/cpluss/article/details/90260550
讲解2:https://blog.csdn.net/xin5ye/article/details/96861303
out[i][j][k] = input[index[i][j][k]][j][k] # if dim == 0
out[i][j][k] = input[i][index[i][j][k]][k] # if dim == 1
out[i][j][k] = input[i][j][index[i][j][k]] # if dim == 2
体现在代码中,这里的目标是:由mask加粗样式ed pos的位置索引,通过gather()函数找到masked的词的d_model!
output = layer(output, enc_self_attn_mask) # [bs, max_len, d_model]
masked_pos = masked_pos[:, :, None].expand(-1, -1, d_model) # [bs, max_pred, 1] -> [bs, max_pred, d_model]
h_masked = torch.gather(output, 1, masked_pos) # [bs, max_pred, d_model]
最后
以上就是不安棒棒糖最近收集整理的关于记录pytorch常用操作的全部内容,更多相关记录pytorch常用操作内容请搜索靠谱客的其他文章。








发表评论 取消回复