DBSCAN(基于密度)
2
个
算
法
参
数
:
邻
域
半
径
R
和
最
少
点
数
目
m
i
n
p
o
i
n
t
s
。
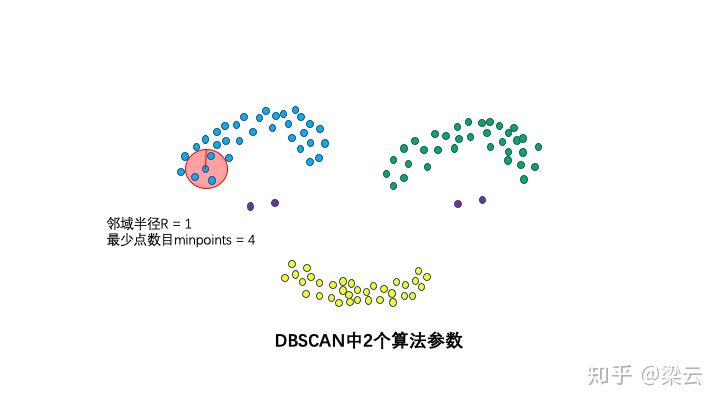
{color{Red}2个算法参数:邻域半径R和最少点数目minpoints。}
2个算法参数:邻域半径R和最少点数目minpoints。
这两个算法参数实际可以刻画什么叫密集——当邻域半径R内的点的个数大于最少点数目minpoints时,就是密集。
3
种
点
的
类
别
:
核
心
点
,
边
界
点
和
噪
声
点
。
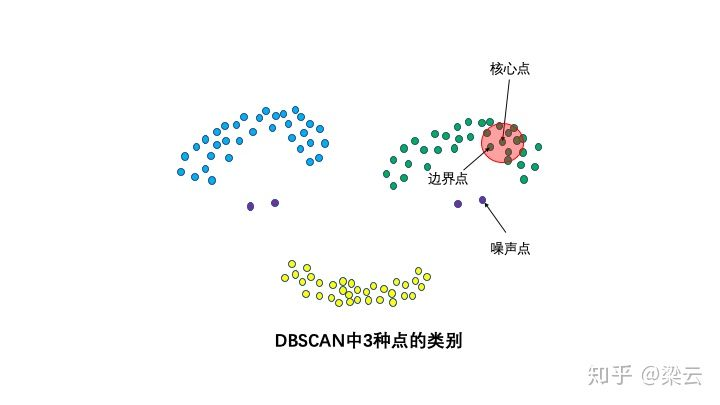
{color{Red}3种点的类别:核心点,边界点和噪声点。}
3种点的类别:核心点,边界点和噪声点。
邻域半径R内样本点的数量大于等于minpoints的点叫做核心点。不属于核心点但在某个核心点的邻域内的点叫做边界点。既不是核心点也不是边界点的是噪声点。
4
种
点
的
关
系
:
密
度
直
达
,
密
度
可
达
,
密
度
相
连
,
非
密
度
相
连
。
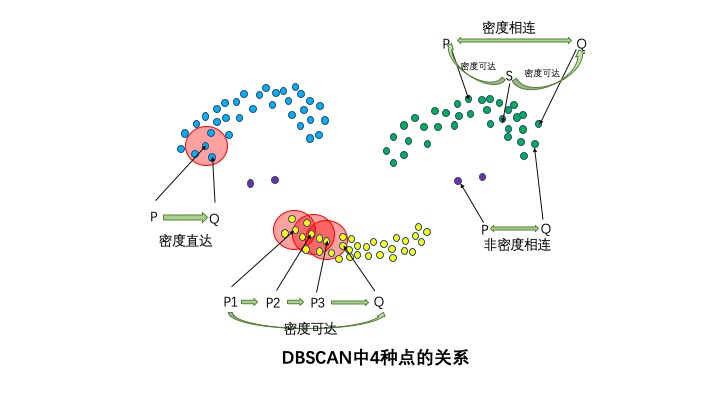
{color{Red}4种点的关系:密度直达,密度可达,密度相连,非密度相连。}
4种点的关系:密度直达,密度可达,密度相连,非密度相连。
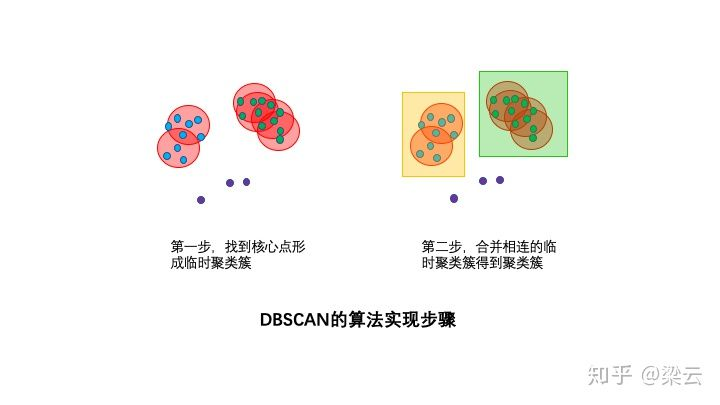
DBSCAN算法步骤:
1:寻找核心点形成临时聚类簇。
扫描全部样本点,如果某个样本点R半径范围内点数目>=MinPoints,则将其纳入核心点列表,并将其密度直达的点形成对应的临时聚类簇。
2:合并临时聚类簇得到聚类簇。
对于每一个临时聚类簇,检查其中的点是否为核心点,如果是,将该点对应的临时聚类簇和当前临时聚类簇合并,得到新的临时聚类簇。
3:重复此操作,直到当前临时聚类簇中的每一个点要么不在核心点列表,要么其密度直达的点都已经在该临时聚类簇,该临时聚类簇升级成为聚类簇。
4:继续对剩余的临时聚类簇进行相同的合并操作,直到全部临时聚类簇被处理。
DBSCAN算法需考虑的三个问题
第
一
个
{color{Blue}第一个}
第一个是一些异常样本点或者说少量游离于簇外的样本点,这些点不在任何一个核心对象在周围,在DBSCAN中,我们一般将这些样本点标记为噪音点。
第
二
个
{color{Blue}第二个}
第二个是距离的度量问题,即如何计算某样本和核心对象样本的距离。在DBSCAN中,一般采用最近邻思想,采用某一种距离度量来衡量样本距离,比如欧式距离。这和KNN分类算法的最近邻思想完全相同。对应少量的样本,寻找最近邻可以直接去计算所有样本的距离,如果样本量较大,则一般采用KD树或者球树来快速的搜索最近邻。
第
三
个
{color{Blue}第三个}
第三个问题比较特殊,某些样本可能到两个核心对象的距离都小于ϵ,但是这两个核心对象由于不是密度直达,又不属于同一个聚类簇,那么如果界定这个样本的类别呢?一般来说,此时DBSCAN采用先来后到,先进行聚类的类别簇会标记这个样本为它的类别。也就是说DBSCAN的算法不是完全稳定的算法。
k-means
算法步骤
1、首先确定一个k值,即我们希望将数据集经过聚类得到k个集合。
2、从数据集中随机选择k个数据点作为质心。
3、对数据集中每一个点,计算其与每一个质心的距离(如欧式距离),离哪个质心近,就划分到那个质心所属的集合。
4、把所有数据归好集合后,一共有k个集合。然后重新计算每个集合的质心。
5、如果新计算出来的质心和原来的质心之间的距离小于某一个设置的阈值(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),我们可以认为聚类已经达到期望的结果,算法终止。
6、如果新质心和原质心距离变化很大,需要迭代3~5步骤。
算法步骤图解
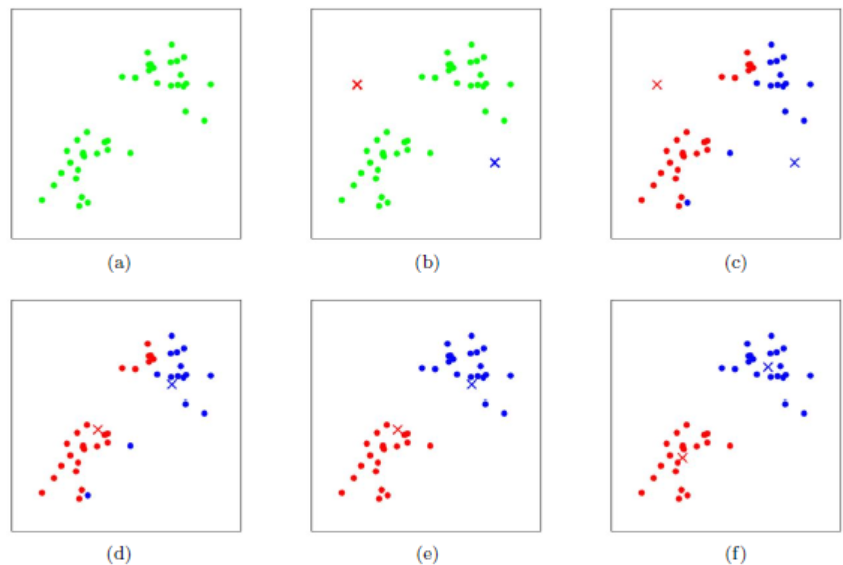
K-means算法优缺点
优点:
1、原理比较简单,实现也是很容易,收敛速度快。
2、当结果簇是密集的,而簇与簇之间区别明显时, 它的效果较好。
3、主要需要调参的参数仅仅是簇数k。
缺点:
1、K值需要预先给定,很多情况下K值的估计是非常困难的。
2、K-Means算法对初始选取的质心点是敏感的,不同的随机种子点得到的聚类结果完全不同 ,对结果影响很大。
3、对噪音和异常点比较的敏感。用来检测异常值。
4、采用迭代方法,可能只能得到局部的最优解,而无法得到全局的最优解。
BIRCH
转载https://www.cnblogs.com/pinard/p/6179132.html
BIRCH的全称是利用层次方法的平衡迭代规约和聚类(Balanced Iterative Reducing and Clustering Using Hierarchies),只需要单遍扫描数据集就能进行聚类。适用于样本量较大的情况,BIRCH除了聚类还可以额外做一些异常点检测和数据初步按类别规约的预处理。但是如果数据特征的维度非常大,比如大于20,则BIRCH不太适。
BIRCH算法利用了一个树结构来帮助我们快速的聚类,一般将它称之为聚类特征树(Clustering Feature Tree,简称CF Tree)。这颗树的每一个节点是由若干个聚类特征(Clustering Feature,简称CF)组成。从下图我们可以看看聚类特征树是什么样子的:每个节点包括叶子节点都有若干个CF,而内部节点的CF有指向孩子节点的指针,所有的叶子节点用一个双向链表链接起来。
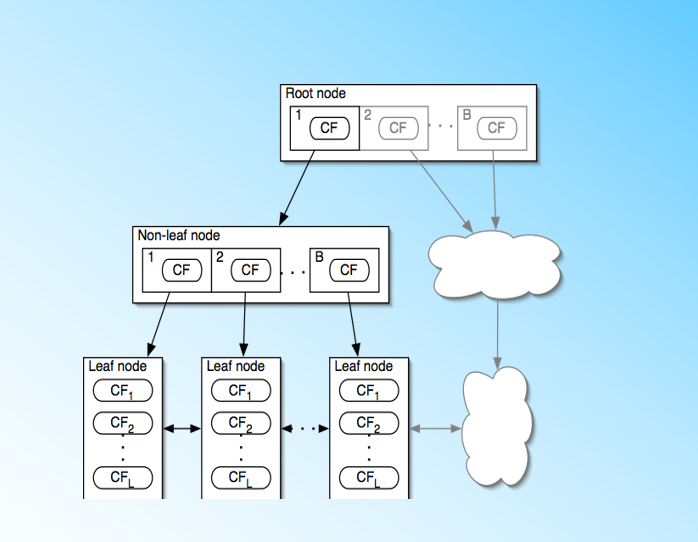
2. 聚类特征CF与聚类特征树CF Tree
在聚类特征树中,一个聚类特征CF是这样定义的:每一个CF是一个三元组,可以用(N,LS,SS)表示。其中N代表了这个CF中拥有的样本点的数量,这个好理解;LS代表了这个CF中拥有的样本点各特征维度的和向量,SS代表了这个CF中拥有的样本点各特征维度的平方和。
CF=(N,LS,SS)
N
=
x
→
n
N=overrightarrow{x}_n
N=xn
L
S
=
∑
n
=
1
N
x
→
n
=
(
∑
n
=
1
N
x
→
n
1
,
∑
n
=
1
N
x
→
n
2
,
…
,
∑
n
=
1
N
x
→
n
1
)
T
LS=sum_{n=1}^Noverrightarrow{x}_n=(sum_{n=1}^Noverrightarrow{x}_{n1},sum_{n=1}^Noverrightarrow{x}_{n2},ldots,sum_{n=1}^Noverrightarrow{x}_{n1})^T
LS=∑n=1Nxn=(∑n=1Nxn1,∑n=1Nxn2,…,∑n=1Nxn1)T
S
S
=
∑
n
=
1
N
x
→
n
2
=
∑
n
=
1
N
x
→
n
T
x
→
n
=
∑
n
=
1
N
∑
i
=
1
D
x
→
n
i
2
SS=sum_{n=1}^Noverrightarrow{x}_n^2=sum_{n=1}^Noverrightarrow{x}_n^Toverrightarrow{x}_n=sum_{n=1}^Nsum_{i=1}^Doverrightarrow{x}_{ni}^2
SS=∑n=1Nxn2=∑n=1NxnTxn=∑n=1N∑i=1Dxni2
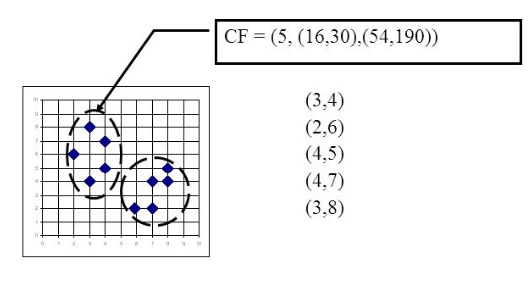
举个例子如下图,在CF Tree中的某一个节点的某一个CF中,有下面5个样本(3,4), (2,6), (4,5), (4,7), (3,8)。则它对应的N=5, LS=(3+2+4+4+3,4+6+5+7+8)=(16,30), SS =(32+22+42+42+32+42+62+52+72+82)=(54+190)=244
CF有一个很好的性质,就是满足线性关系,也就是CF1+CF2=(N1+N2,LS1+LS2,SS1+SS2)。这个性质从定义也很好理解。如果把这个性质放在CF Tree上,也就是说,在CF Tree中,对于每个父节点中的CF节点,它的(N,LS,SS)三元组的值等于这个CF节点所指向的所有子节点的三元组之和。如下图所示:
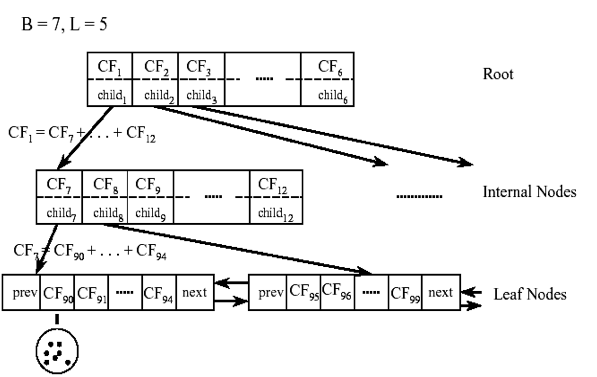
从上图中可以看出,根节点的CF1的三元组的值,可以从它指向的6个子节点(CF7 - CF12)的值相加得到。这样我们在更新CF Tree的时候,可以很高效。
对于CF Tree,我们一般有几个重要参数,第一个参数是每个内部节点的最大CF数B,第二个参数是每个叶子节点的最大CF数L,第三个参数是针对叶子节点中某个CF中的样本点来说的,它是叶节点每个CF的最大样本半径阈值T,也就是说,在这个CF中的所有样本点一定要在半径小于T的一个超球体内。对于上图中的CF Tree,限定了B=7, L=5, 也就是说内部节点最多有7个CF,而叶子节点最多有5个CF。
3. 聚类特征树CF Tree的生成
下面我们看看怎么生成CF Tree。我们先定义好CF Tree的参数: 即内部节点的最大CF数B, 叶子节点的最大CF数L, 叶节点每个CF的最大样本半径阈值T
在最开始的时候,CF Tree是空的,没有任何样本,我们从训练集读入第一个样本点,将它放入一个新的CF三元组A,这个三元组的N=1,将这个新的CF放入根节点,此时的CF Tree如下图:
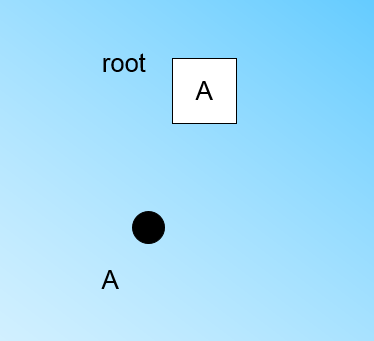
现在我们继续读入第二个样本点,我们发现这个样本点和第一个样本点A,在半径为T的超球体范围内,也就是说,他们属于一个CF,我们将第二个点也加入CF A,此时需要更新A的三元组的值。此时A的三元组中N=2。此时的CF Tree如下图:
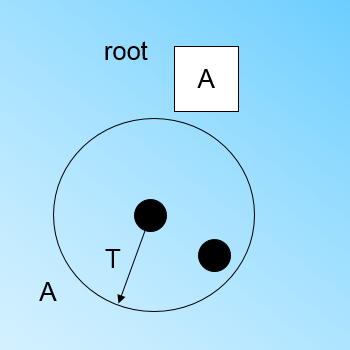
此时来了第三个节点,结果我们发现这个节点不能融入刚才前面的节点形成的超球体内,也就是说,我们需要一个新的CF三元组B,来容纳这个新的值。此时根节点有两个CF三元组A和B,此时的CF Tree如下图:
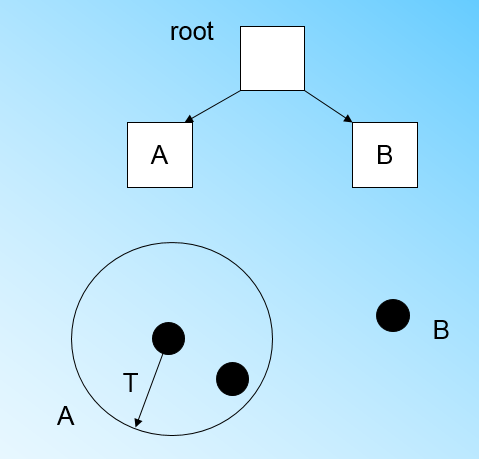
当来到第四个样本点的时候,我们发现和B在半径小于T的超球体,这样更新后的CF Tree如下图:
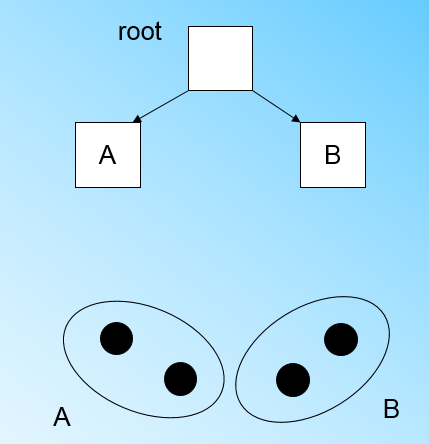
那个什么时候CF Tree的节点需要分裂呢?假设我们现在的CF Tree 如下图, 叶子节点LN1有三个CF, LN2和LN3各有两个CF。我们的叶子节点的最大CF数L=3。此时一个新的样本点来了,我们发现它离LN1节点最近,因此开始判断它是否在sc1,sc2,sc3这3个CF对应的超球体之内,但是很不幸,它不在,因此它需要建立一个新的CF,即sc8来容纳它。问题是我们的L=3,也就是说LN1的CF个数已经达到最大值了,不能再创建新的CF了,怎么办?此时就要将LN1叶子节点一分为二了。
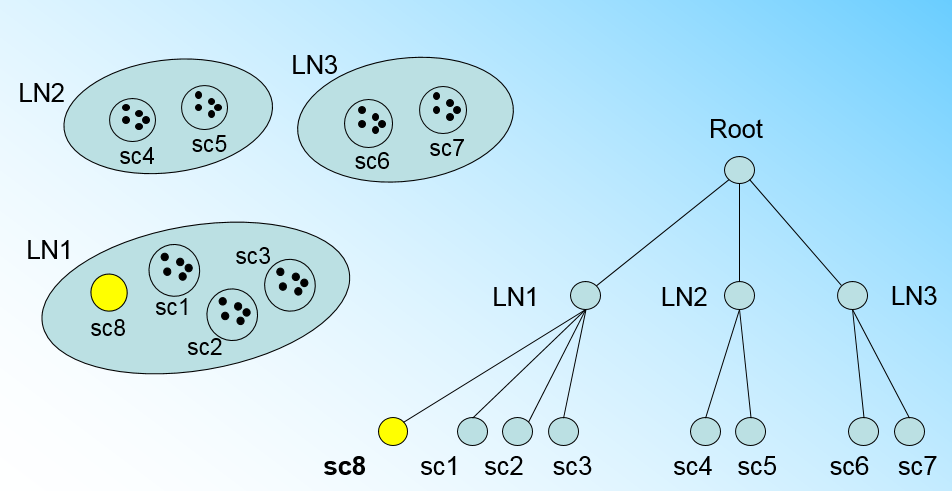
我们将LN1里所有CF元组中,找到两个最远的CF做这两个新叶子节点的种子CF,然后将LN1节点里所有CF sc1, sc2, sc3,以及新样本点的新元组sc8划分到两个新的叶子节点上。将LN1节点划分后的CF Tree如下图:
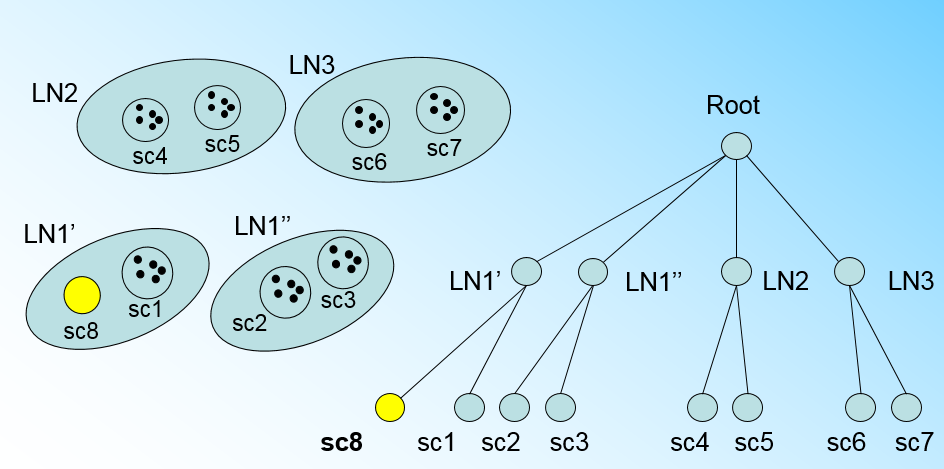
如果我们的内部节点的最大CF数B=3,则此时叶子节点一分为二会导致根节点的最大CF数超了,也就是说,我们的根节点现在也要分裂,分裂的方法和叶子节点分裂一样,分裂后的CF Tree如下图:
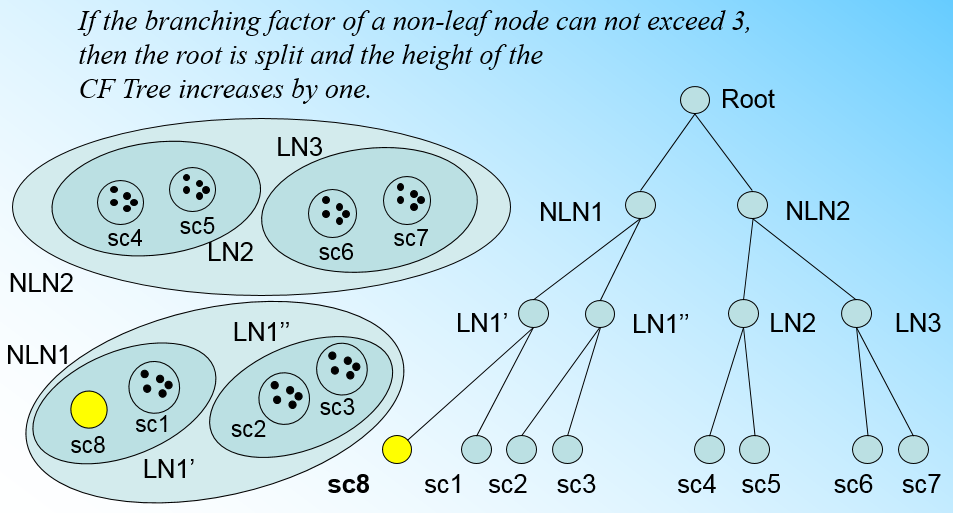
总结下CF Tree的插入:
- 从根节点向下寻找和新样本距离最近的叶子节点和叶子节点里最近的CF节点
- 如果新样本加入后,这个CF节点对应的超球体半径仍然满足小于阈值T,则更新路径上所有的CF三元组,插入结束。否则转入3.
- 如果当前叶子节点的CF节点个数小于阈值L,则创建一个新的CF节点,放入新样本,将新的CF节点放入这个叶子节点,更新路径上所有的CF三元组,插入结束。否则转入4。
- 将当前叶子节点划分为两个新叶子节点,选择旧叶子节点中所有CF元组里超球体距离最远的两个CF元组,分布作为两个新叶子节点的第一个CF节点。将其他元组和新样本元组按照距离远近原则放入对应的叶子节点。依次向上检查父节点是否也要分裂,如果需要按和叶子节点分裂方式相同。
BIRCH算法
上面讲了半天的CF Tree,终于我们可以步入正题BIRCH算法,其实将所有的训练集样本建立了CF Tree,一个基本的BIRCH算法就完成了,对应的输出就是若干个CF节点,每个节点里的样本点就是一个聚类的簇。也就是说BIRCH算法的主要过程,就是建立CF Tree的过程。
当然,真实的BIRCH算法除了建立CF Tree来聚类,其实还有一些可选的算法步骤的,现在我们就来看看 BIRCH算法的流程。
1) 将所有的样本依次读入,在内存中建立一颗CF Tree, 建立的方法参考上一节。
2)(可选)将第一步建立的CF Tree进行筛选,去除一些异常CF节点,这些节点一般里面的样本点很少。对于一些超球体距离非常近的元组进行合并
3)(可选)利用其它的一些聚类算法比如K-Means对所有的CF元组进行聚类,得到一颗比较好的CF Tree.这一步的主要目的是消除由于样本读入顺序导致的不合理的树结构,以及一些由于节点CF个数限制导致的树结构分裂。
4)(可选)利用第三步生成的CF Tree的所有CF节点的质心,作为初始质心点,对所有的样本点按距离远近进行聚类。这样进一步减少了由于CF Tree的一些限制导致的聚类不合理的情况。
从上面可以看出,BIRCH算法的关键就是步骤1,也就是CF Tree的生成,其他步骤都是为了优化最后的聚类结果。
BIRCH算法的主要优点有:
优点:
1.节约内存,所有的样本都在磁盘上,CF Tree仅仅存了CF节点和对应的指针。
2.聚类速度快,只需要一遍扫描训练集就可以建立CF Tree,CF Tree的增删改都很快。
3.可以识别噪音点,还可以对数据集进行初步分类的预处理
缺点:
1.由于CF Tree对每个节点的CF个数有限制,导致聚类的结果可能和真实的类别分布不同.
2.对高维特征的数据聚类效果不好。此时可以选择Mini Batch K-Means
3.如果数据集的分布簇不是类似于超球体,或者说不是凸的,则聚类效果不好。
最后
以上就是潇洒烤鸡最近收集整理的关于小嘿嘿之常见聚类算法之DBSCAN/k-means/BIRCH的全部内容,更多相关小嘿嘿之常见聚类算法之DBSCAN/k-means/BIRCH内容请搜索靠谱客的其他文章。








发表评论 取消回复