一、 实验目的:
- 了解朴素贝叶斯算法基本原理;
- 能够使用朴素贝叶斯算法对数据进行分类
- 编写函数实现示例数据集输出结果。
二、 实验软件:
Rstudio
三、 实验思路
准备数据data,希望分类的元组X为test
主函数 NaiveBayes = function(){}
公式 P(Ci|X) = P(X|Ci) P(Ci) / P(X)
- 1.划分C1,C2类,“yes",“no”
求P(C1),P(C2)
- 2.求P(Xi|Ci)
PXi_Ci = function(data,test,class_result){}
得PXi_C1,PXi_C2
- 3.求PX_Ci = function(PXi_Ci)
P(X|C1) = P(X1|C1)*P(X2|C1)*P(X3|C1)…
P(X|C2) = P(X1|C2)*P(X2|C2)*P(X3|C2)…
- 4.比较PX_C1PC[1],PX_C2PC[2],select函数判断预测元组X的类是yes还是No,输出final结果
测试NaiveBayes(data,test)
四、 源代码:
data<-data.frame(
Age=c("youth","youth","middle_aged","senior","senior","senior","middle_aged","youth","youth","senior","youth","middle_aged","middle_aged","senior"),
income=c("high","high","high","medium","low","low","low","medium","low","medium","medium","medium","high","medium"),
student=c("no","no","no","no","yes","yes","yes","no","yes","yes","yes","no","yes","no"),
credit_rating=c("fair","excellent","fair","fair","fair","excellent","excellent","fair","fair","fair","excellent","excellent","fair","excellent"),
buys_computer=c("no","no","yes","yes","yes","no","yes","no","yes","yes","yes","yes","yes","no))
#yes
test<-data.frame(Age="youth",income="medium",student="yes",credit_rating="fair")
NaiveBayes = function(data,test){
rowCount=nrow(data) #计算数据集中有几行,也即有几个样本点
colCount=ncol(data) #几列
class_result = levels(factor(data[,colCount])) # "no""yes"
class_Count = c() #存放个数
class_Count[class_result]=rep(0,length(class_result))
#pC1,pC2
for(i in 1:rowCount){
if(data[i,colCount] %in% class_result)
temp=data[i,colCount]
class_Count[temp]=class_Count[temp]+1
}
PC = c()
for (i in 1:length(class_result)) {
PC[i] = class_Count[i]/rowCount
}
PC[1]
PC[2]
#####求P(Xi|Ci)
PXi_Ci = function(data,test,class_result){
xCount= c()
for(k in 1:ncol(test)){
xCount[k] = 0
temp = 0
for(i in 1:nrow(data)){
if(as.vector(data[i,k]) == as.vector(test[1,k]) & data[i,ncol(data)] == class_result){
xCount[k] <- xCount[k]+1
}
}
}
temp = subset(data,data[,ncol(data)] == class_result)
Pxi_Ci = xCount/nrow(temp)
return(Pxi_Ci)
}
PXi_C1= PXi_Ci(data,test,class_result[1]) #"no"
PXi_C2= PXi_Ci(data,test,class_result[2]) #"yes"
#####求P(X|Ci)
PX_Ci = function(PXi_Ci){
result = 1
for(i in 1:length((PXi_Ci))){
result<-result*PXi_Ci[i]
}
return(result)
}
PX_C1 = PX_Ci(PXi_C1)
PX_C2 = PX_Ci(PXi_C2)
#######P(Ci|X)
Ci_X = data.frame(C1_X = PX_C1*PC[1],C2_X = PX_C2*PC[2])
select = function(data){ #比较找出最大Ci_X的类,存入新的属性decide
if(data[,1]>data[,2]){
data$decide = "no"
}else{
data$decide = "yes"
}
return(data)
}
final = select(Ci_X)
return(final)
}
#测试
NaiveBayes(data,test)
五、 实验结果:
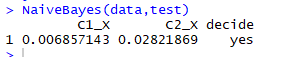
因此对于元组X,朴素贝叶斯分类预测元组X的类为yes
最后
以上就是孝顺小鸭子最近收集整理的关于数据挖掘实验(五):朴素贝叶斯分类方法 R语言的全部内容,更多相关数据挖掘实验(五):朴素贝叶斯分类方法内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复