第二章:数据
数据相关问题,包括
- 数据类型
- 数据质量
- 使数据易于挖掘的数据预处理
- 根据数据联系分析数据
2.1 数据类型

2.1.1 属性与度量
属性
![]()
![]()
属性类型
![]()

属性的不同类型
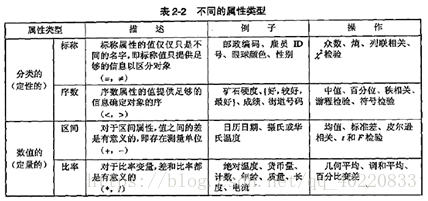
对特定的属性类型进行有意义的操作
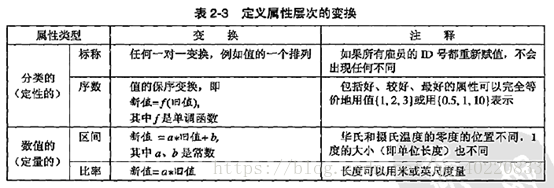
用值的个数描述属性
区分属性的一种独立方法是根据属性可能取值的个数来判断

非对称属性
对于非对称属性,出现非零属性值才是重要的

2.1.2 数据集的类型
1.数据集的一般属性


![]()

2.记录数据
许多数据挖掘任务都假定数据集是记录的汇集,每个记录包含固定的数据字段(属性)集。还有其他的一些数据
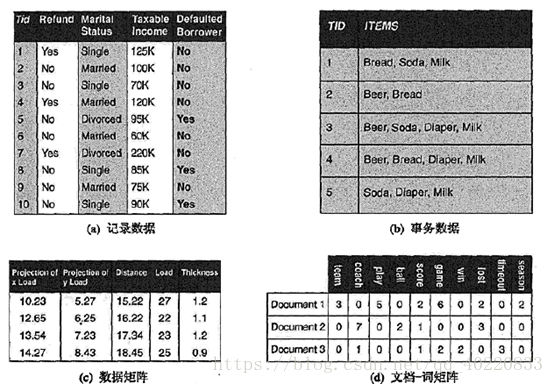




3. 基于图形的数据
图形可以有效地表示数据。考虑两种特殊情况:1.图形捕获数据对象之间的联系,2.数据对象本身用图形表示[灏3] 。

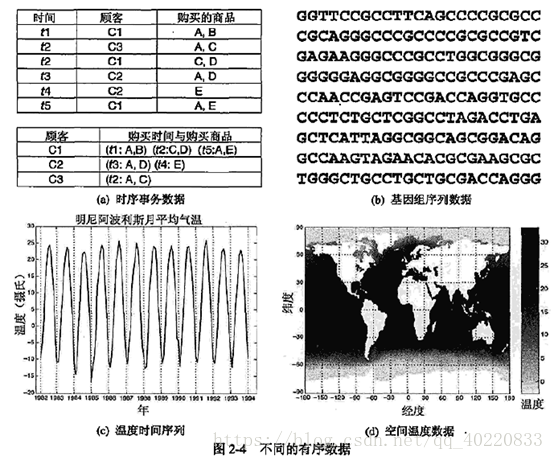
4.有序数据
对于某些数据类型,属性具有涉及时间或空间的联系




5.处理非记录数据


2.2 数据质量
这里可以相比于爬虫爬下来的数据,基本上都不是质量高的数据,所以我们要进行修正

2.2.1 测量和数据收集问题

1.测量误差和数据收集错误

2.噪声和伪像
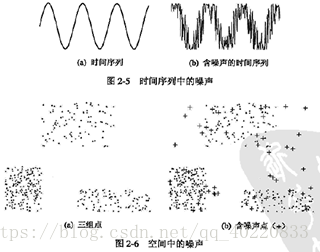

![]()
3.精度偏移和准确率
![]()
![]()
这些的话了解即可,具体的还没有使用到
4.离群点

5.遗漏值
![]()



6.不一致的值

7.重复数据

2.2.2 关于应用的问题


2.3 数据预处理
讨论应当采用哪些预处理步骤,让数据更加适合挖掘。包括聚集,抽样,维规约,特征子集选择,特征创建,离散化和二元化,变量变换等等。
2.3.1 聚集



2.3.2 抽样
抽样是一种选择数据对象子集进行分析的常用方法。
![]()
1. 抽样方法


2. 渐近抽样

2.3.3 维归约
数据集可能包含大量特征。维归约的好处是,可以删除不相关的特征并降低噪声,另一个好处是可以使模型更容易理解。


2.3.4 特征子集的选择
当给你的一些特征之后,会有降低维度的方法,且特征中会有一些关联性很想的特征

下图对于维度很多的时候是不可行的

使用以下的三种方法


1.特征子集选择体系结构


下面的感觉和机器学习中很像啊,都是验证,然后有一个评估度量


2.特征加权

2.3.5 特征创建
1.特征提取
需要我们自己挖掘

2.映射数据到新的空间
使用一种完全不同的视角挖掘数据可能揭示出重要和有趣的特征
3.特征构造
原始数据集的特征具有必要的信息,但其形式不适合数据挖掘算法。在这种情况下,一个或者多个由原特征够早的新特征可能比原特征更有用。
2.3.6 离散化和二元化

具体的我就不细分了,需要查看书本
2.3.7 变量变换
变量变换是指用于变量的所有值的变换。
1.简单函数
![]()
2.规范化或标准化


2.4 相似性和相异性的度量
2.4.1 基础
1 定义
距离和相似度比较好理解

2 变换
通常使用变换把相似度转换成距离或者把邻近度转换到一个特定区间。

2.4.2 简单属性之间的相似度和相异度

2.4.3 数据对象之间的相异度
距离


2.4.4 数据对象之间的相似度

2.4.5 邻近性度量的例子
1. 二元数据的相似性度量
这两个用的不多



2. 余弦相似度
这个是比较常见的一个方法。

3. 广义Jaccard系数
不太常见,用到可以查看
4. 相关性

2.4.6 相邻度计算问题

1. 距离度量的标准化和相关性

2. 组合异种属性的相似度

3. 使用权值

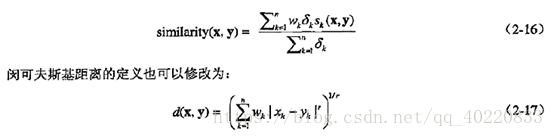
2.4.7 选取正确的邻近性度量


最后
以上就是舒心豌豆最近收集整理的关于数据挖掘导论第二章笔记的全部内容,更多相关数据挖掘导论第二章笔记内容请搜索靠谱客的其他文章。








发表评论 取消回复