深度学习领域开源的框架有很多,比如 caffe、TensorFlow、Theano、Torch,到底哪种框架更为优秀呢?我的同学在例会上进行了详细的介绍,后面总结成了这篇博文,转载并总结之以更好的学习很好。原博文地址:http://blog.csdn.net/u010167269/article/details/51810613
主要与大家的分享来自这篇论文:《Comparative Study of Deep Learning Software Frameworks》,这篇文章对现在流行的五个开源深度学习框架caffe、Neon、TensorFlow、Theano、Torch 做了比较,很严谨。作者也开源了他们的比较 Benchmarks 代码:https://github.com/DL-Benchmarks/DL-Benchmarks。
如果您急着看比较结果,可以从目录直接跳到 Conclusion 部分
Abstract
五个开源框架:caffe、Neon、TensorFlow、Theano、Torch
比较的三方面:可扩展性(extensibility)、hardware utilization(硬件利用率)以及大家最关心的:速度(speed)
评估测试都是部署在单机上,对于多线程 CPU、GPU(Nvidia Titan X)都进行测试;
速度评估标准包括了梯度计算时间(gradient computation time)、前向传播时间(forward time);
对于卷积网络,作者还对这几个深度框架支持的不同的卷积算法以及相应的性能表现做了实验;
最后通过实验,作者发现 Theano、Torch 是最具扩展性的深度学习框架;
在 CPU 上的测试性能来看,Torch 最优,其次是 Theano;
在 GPU 上的性能表现,对于大规模卷积以及全连接网络,还是 Torch 最优,其次是Neon;
但是 Theano 在部署和训练 LSTM 网络中夺得拔筹;
caffe 是最容易测试评估性能的标准深度学习框架;
最后,TensorFlow 与 Theano 有些相似,是比较灵活的框架,但是其性能表现,目前还跟上面的几个框架比不起来。
但是,这篇文章发表的时候,TensorFlow 还只能用 cuDNN v.2 版本。现在怎么样,还需要做新的实验。
Introduction
现在大多数成功的深度学习架构由几种不同类型的网络层组合而成,如 全连接层(fully connected layer)、卷积层(convolutional layer)、递归层(recurrent layer)。之后用各种随机梯度下降算法(stochastic gradient descent algorithm),以及一些正则化技术(regularization),如dropout、weight decay。
伴随着深度学习的流行与成功,一些深度学习框架不断涌现,包括但不限于:
- caffe: http://caffe.berkeleyvision.org/
- DeepLearning4J: http://deeplearning4j.org/
- deepmat: https://github.com/kyunghyuncho/deepmat
- Neon: http://neon.nervanasys.com/docs/latest/index.html
- Eblearn: http://eblearn.sourceforge.net/
- PyLearn: http://deeplearning.net/software/pylearn2/
- TensorFlow: https://www.tensorflow.org/
- Theano: http://deeplearning.net/software/theano/
- Torch: http://torch.ch/
- MXnet: http://mxnet.readthedocs.io/en/latest/
- chainer: https://github.com/pfnet/chainer
不同的框架从不同的角度去部署、训练深度学习算法。例如:caffe 强调使用的简单性,所以在 caffe 中,在网络中添加一个层很简单。又如,Theano 可以自动求微分,可以方便的修改架构,以便研究与开发。
前不久,有人已经评测了几种深度学习框架的性能:https://github.com/soumith/convnet-benchmarks,但是这个比较只是在卷积网络架构上进行比较(并且忽视掉了与卷积无关测网络层,如dropout 层、Softmax 层)。
这篇文章对评测比较实验进行了扩展,从上面的一些开源架构中,选择了五种有代表性的框架:caffe、Neon、TensorFlow、Theano、Torch。
其中,caffe、Theano、Torch 是目前深度学习社区使用最多的框架。
本论文中加入 Neon 的评测,是因为在上面的评测中,Neon 取得了卓越的性能表现。
而对 TensorFlow 进行评测,是因为自从 TensorFlow 被 Google 开源之后,取得了耀眼的关注度,在 Github 上的Star 数量已经到
27,362
了。而 caffe 也才
11,062
个 Star 。在这篇文章进行评测的时候,TensorFlow 还没有支持最新的 cuDNN v.3,还只支持 cuDNN v.2。但为了评测的完整性,还是将 TensorFlow 加进入了。
在对这些框架进行评估时,考虑以下三个方面:
- 可扩展型(Extensibility): 一是对于不同类型的网络层:全连接层(fully-connected layer)、卷积层(convolutional layer)、递归层(recurrent layer)的组合能力;二是对于不同训练过程支持的能力,如非监督逐层预训练(unsupervised layer-wise pre-training)、监督训练(supervised learning);三是对于不同卷积层的支持能力,如支持不支持FFT-based 算法 。
- 硬件利用率(Hardware Utilization): 这些框架对于硬件资源的结合、调用情况。如对于 多线程 CPU 的支持使用、对于 GPU 调用的设置情况。
- 速度(speed): 这些框架在训练方面、部署方面的速度表现性能。
这项研究可以便于深度学习个人与企业,了解深度学习框架的强项、弱项,以便于可以根据自身的需求来使用这些开源框架。
此外,本文还探究了深度学习框架当前的一些不足与限制,以便在未来能够得到解决。
Overview of the deep learning frameworks
这里有一个深度学习框架列表,总结了目前几乎所有的深度学习框架:http://deeplearning.net/software_links/。现在这些框架有些已经成熟了,在 CUDA 的帮助下,能够非常高效地训练具有数百万个参数的神经网络。
下面的 表1 展示了 Google groups 中使用者的数量,以及每个深度学习框架在 Github 仓库中贡献者的数量(截至2016.02.08):

可以看见,使用者与贡献者最多的是:caffe、Theano、Torch,这也是本文选择这三个框架做评测的原因之一。
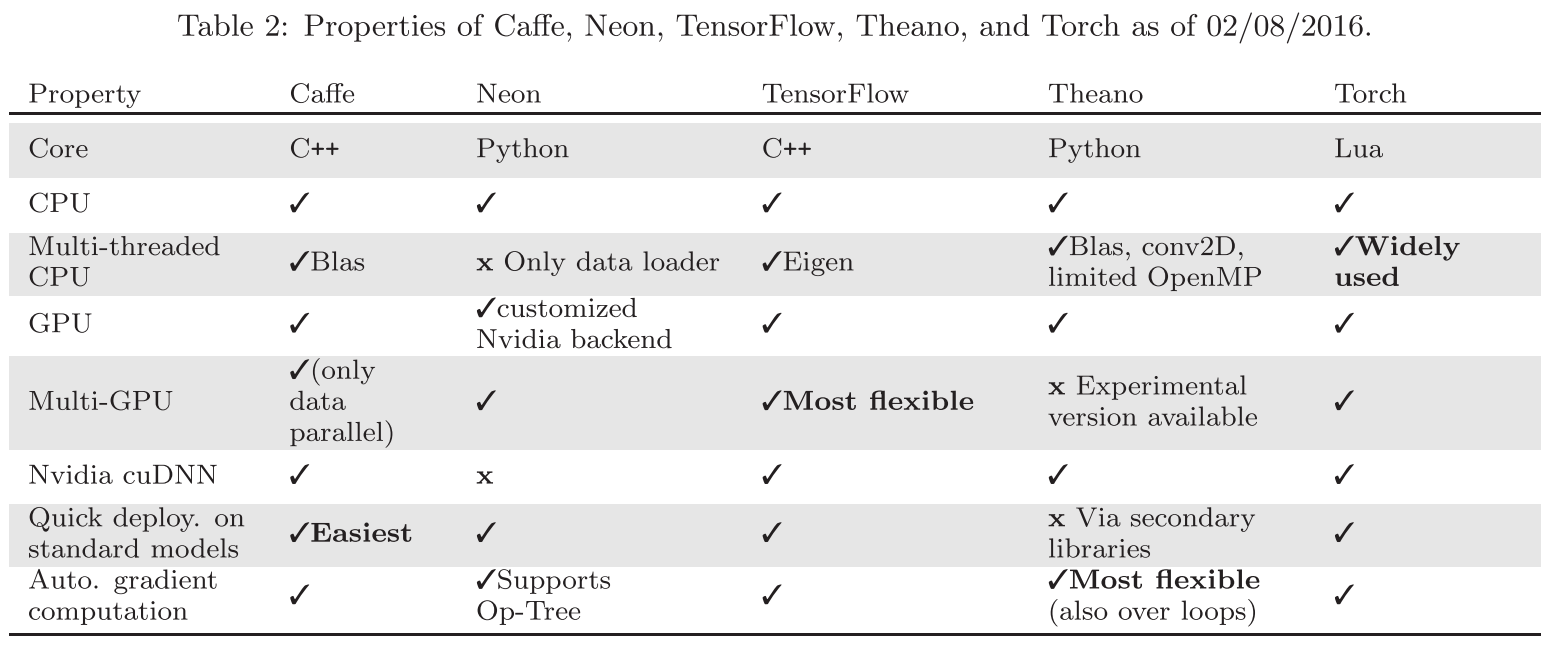
表2 展示了这几个深度学习框架的通用属性:
Benchmarking Setup
Evaluation Metrics
作者用下面的两个评估标准来评测五个开源深度学习框架的性能:
- 前向传播时间(Forward Time): 给定一个数据集、神经网络,将输入数据通过网络处理后,产生相应的输出数据,这个过程走过的时间,就是前向传播的时间。如果我们要将深度网络部署在实际生活中应用,前向传播时间就非常重要。
- 梯度计算时间(Gradient Computation Time): 对于给定的 input batch,每一个 parameter 得到一个对应的梯度的时间,这个时间消耗也被纳入评测标准。注意到,对于大多数的框架(如:Torch),梯度计算时间是指调用 forward 函数、 backward 函数,这两个函数计算所用时间之和。但是对于 Theano,梯度计算时间是指调用 Theano 编译生成的梯度计算函数,这个函数隐式地执行了 forward、backward 过程。另外,梯度计算时间不包含计算完梯度后,对梯度进行更新的时间。
因为对于 Theano ,一开始是需要花费时间去编译生成前向传播函数、梯度计算函数。
事实上,这个正是 Theano 被众多使用者“喷“的地方,因为速度实在是太…慢…了…我使用过 Theano 这个,但感觉还好,可能我的工程不是很大吧,但是这个确实是个问题。之后 Theano 执行的时候就一点也不慢了。因为这个过程是 Theano 将 Python 代码 编译为 C 代码,所以调用的时候,速度很快。
System setup
本实验都是在单机上完成的,操作系统为 Ubuntu 14.04,CPU 为 Intel Xeon CPU E5-1650 v2 @3.5GHz,GPU 为Nvidia GeForce GTX Titan X/PCIe/SSE2,32G 的 DDR3 内存,SSD 硬盘。
使用的框架版本、依赖库及其版本:
- OpenCV 3.0
- OpenBLAS 0.2.14
- caffe 使用的 commit ID:8c8e832
- Neon 版本:1.0.0.rc1 (2015-09-08),commit ID:a6766f
- TensorFlow 版本:0.6.0,使用
pip install安装的 - Theano 版本:0.7.0.dev,commit ID:662ea98
- Torch7,commit ID:8c8e832,fbcunn 的 commit ID:5bb9785
- caffe、Theano、Torch 的 CUDA 版本为 CUDA 7.5,cuDNN 版本为 cuDNN v3。TensorFlow 的 CUDA 版本为 CUDA 7.0,cuDNN 版本为 cuDNN v2
- Data arrays 是按照 float32 存储
Results and Discussion
评测实验一是在 MNIST 数据集、ImageNet 数据集上训练 栈式自编码(stacked auto-encoder network)网络,卷积网络,二是在 IMDB review 数据集上训练 LSTM 网络。
注意,使用原始的框架,以及将这个深度学习框架结合基于 CUDA 包,这两者的测试结果可能会差别很大。
如在 Torch 中,我们可以用 Nvidia cuDNN 库,或者用 cunn 库,或者使用 fbcunn 库(Facebook AI 研究组开发的 深度学习 CUDA 扩展库,包括 FFT-based 卷积)。
在 Theano 中,我们可以直接使用 cuDNN 或者 conv-fft 实施卷积操作,conv-fft 是 FFT-based 的 Theano 实现。
LeNet
第一个基准测试实验是在 MNIST 数据集,在 LeNet 网络上进行实验。与原始的 LeNet 不同,这里将原先的 Sigmoid 激活函数换成了ReLU 激活函数,将原先的RBF 网络 换成了 Softmax logistic loss layer。
LeNet 是第一个正式的卷积神经网络模型,在 LeCun 的 Paper 上:《Gradient-based learning applied to document recognition》,引用量
5368
次。
LeNet 包括两个 卷积 - 池化(conv-pooling) 层,两个 全连接层(fully connected layer),如下图所示:
下表展示了五个深度学习框架的梯度计算、前向传播过程在 CPU、GPU 上的平均处理时间。其中, batch size 设置为
64
。
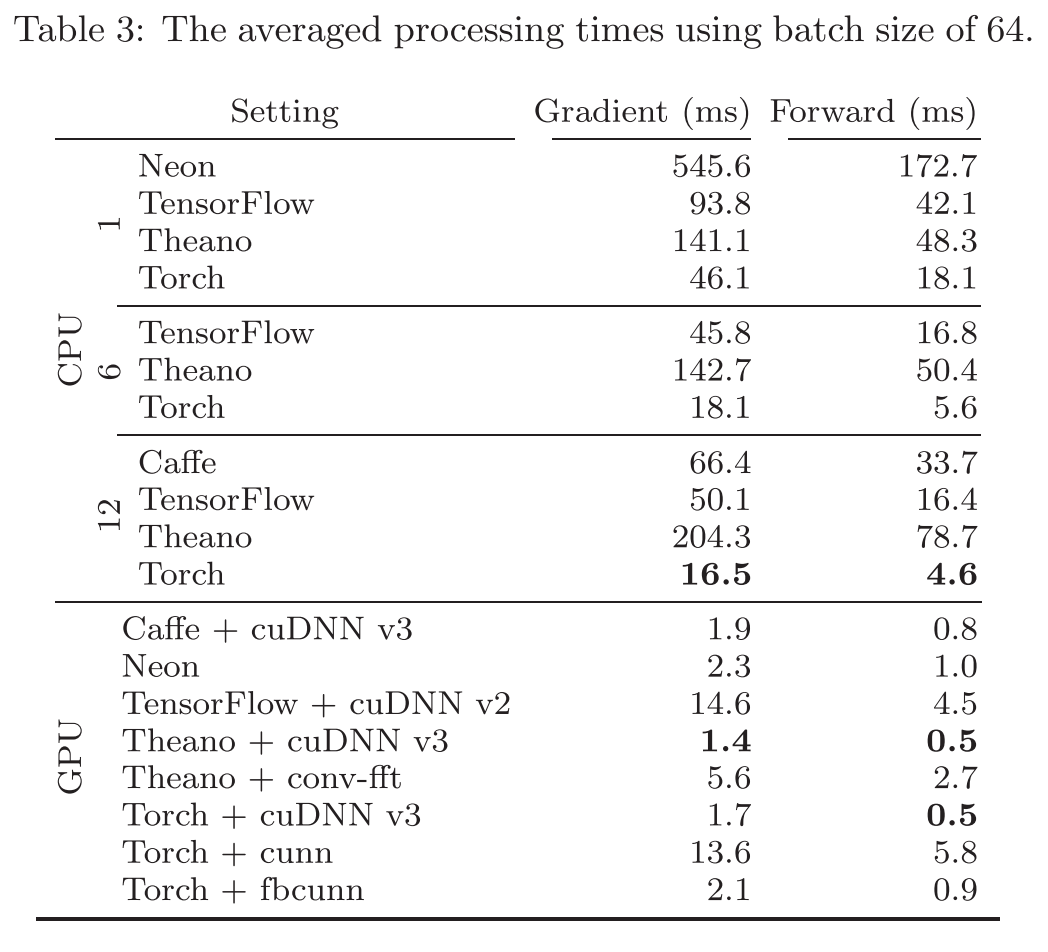
对于 CPU 的实验统计时间,CPU 线程使用的个数也被统计在表格中。其中的 Neon 不能使用多线程,因此 Neon 的 CPU 实验时间统计只有但线程的结果。对于 caffe,caffe 的多线程使用的个数,需要在安装的时候决定好。这里是
12
个线程,因此 caffe 的 CPU 实验只有
12
线程的时间统计结果。
TensorFlow、Theano、Torch 可以灵活地选择使用的 CPU 线程数,因此他们的 CPU 的实验时间有多个结果。
因为我们的机器有
6
个物理核,但用 Hpyer-Threading 的技术,可以使用
12
个线程。因此,我们统计
6
线程、
12
线程的实验结果。
当用 GPU 进行实验时,对于每个深度学习框架,使用基础的卷积加速库(如:cuDNN),并指明版本(版本越高,速度越快)。Neon 使用自己的 GPU/CPU backend。
从结果中可以看出,对于训练 LeNet,GPU的效率相比较于 CPU,是碾压性的。而且,对于更大的数据量,更大的网络模型,GPU 的这种优势将会更明显。
CPU 阶段的实验来看,Torch 的表现最好,而 Neon 的表现最差。对于 GPU 的实验看,cuDNN 的加速效果要明显好于 conv-fft 。LeCun 的一篇 Paper 《Fast Training of Convolutional Networks Through FFT》提到,一般来说,FFT-based 的性能表现,高度取决于input 的 size,以及kernel size 。
梯度计算的时间最好的是 Theano,只有 1.4s ,当然,Torch 的表现也很棒, 1.7s 。而对于前向传播的时间,Theano 以及 Torch 打了个平手。之前耀眼的 TensorFlow 在 GPU 实验中的表现是最差的。可能的原因是 TensorFlow 使用的是 cuDNN v.2 版本,而 caffe、Theano、Torch 使用的是 cuDNN v.3 版本。
还应该注意到 MNIST 是相对较小的一个数据集,可以很容易的“放进“ CPU 的内存,或者 GPU 的显存中。因此,Theano、Torch、Neon 是一次性的将数据全部读入显存中。这样避免了后来将数据从本地拷贝到 GPU 中所造成的延迟。
在 Theano 中,这个可以用 shared variables 来完成。
在 Torch 中,可以调用 cuda( ) 函数来完成
在 Neon 中,可以使用 DataIterator class
在 TensorFlow 中,这个可以在定义变量的时候,通过设置合适的参数来完成
在 caffe 中,将整个训练数据集拷贝到显存中,可以用 MemoryData layer
下图展示了五个深度学习框架在 GPU 上,用不同的 batch size,各自 batch size 的梯度计算时间,前向传播时间的统计:
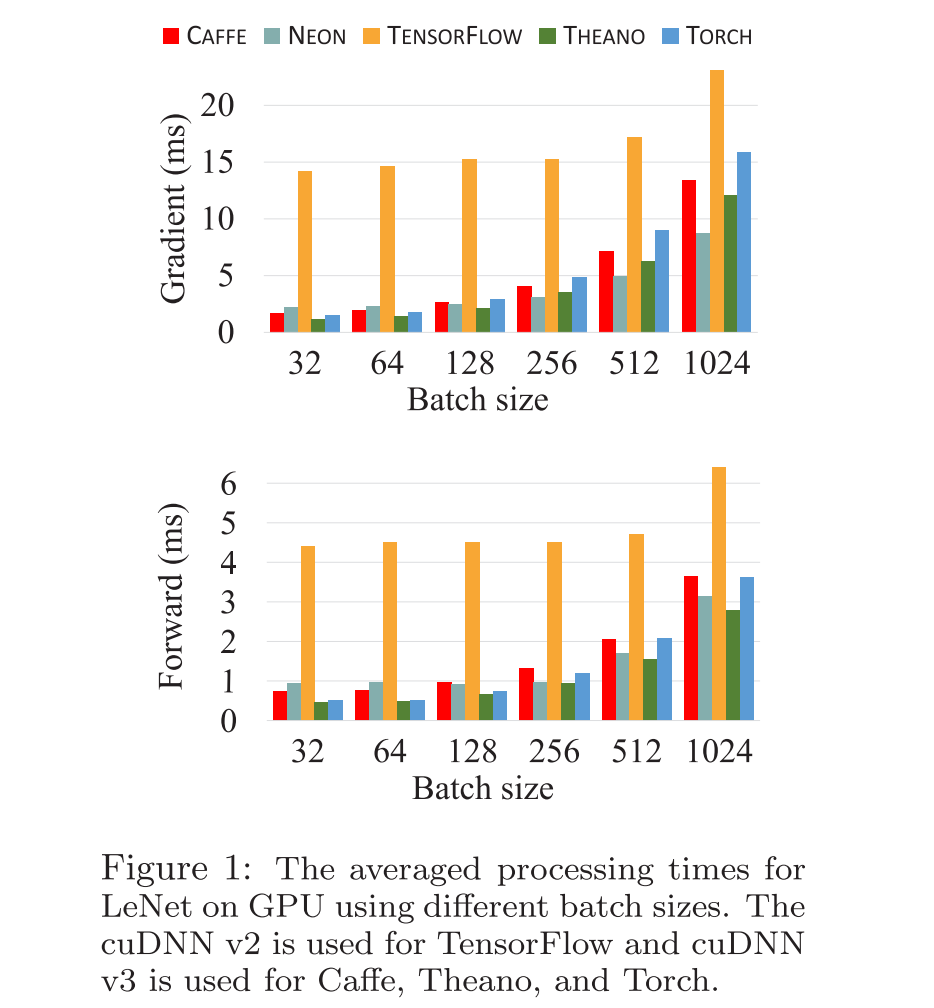
从图中可以看出,当 batch size 较小时,Theano 的梯度计算时间最短,而当 batch size 较大时,Neon 的梯度计算时间最短。
而在前向传播实验中,Theano 不管 batch size 的大小,其前向传播时间都最短,而且随着 batch size 的变大,其优势更明显。
caffe、Torch的表现,随着 batch size 的变大,其性能下降的很明显。TensorFlow 表现一直很“稳定“ — 性能都最差,尤其是当 batch size 越小的时候。
AlexNet
在这一部分的实验中,我们将用 ImageNet 去训练 AlexNet 。其实也有很多最新的、更大的网络模型,如 GoogleNet,Oxford Net 等等。但是因为 AlexNet 是第一个大幅提升 ImageNet 比赛结果的深度网络模型( 2012 年 ImageNet 比赛),而且 AlexNet 非常流行,很具代表性。
AlexNet 前 5 层是卷积层,后 3 层是全连接层,最后一个全连接层的 output 是一个具有 1000 输出的
图像被 crop 为 224×224 。并没有做数据增广处理(data augmentation,如:random cropping,transformation)。
这个 AlexNet 网络模型,caffe 的版本、Neon 的版本在它们的 Github 仓库中就有,但是 Neon 不支持 Grouping 层、LRN 层。
TensorFlow 的版本改编自:https://github.com/soumith/convnet-benchmarks,同样的,TensorFlow 目前还不支持Grouping 层。
Theano 的版本改编自 《Theano-based Large-scale Visual Recognition with Multiple GPUs》这篇文章里的,不过没有用 GPU 并行。
更具体的,实现每个框架的 AlexNet 的时候, 我们没有使用
dimshuffle
操作 。
Theano 在 GPU 上的卷积操作,本文既调用了 来自 cuDNN 库里的
dnn.dnn_conv
函数,又使用了 pylearn2 中的 cuda-convnet 接口里面的对应的卷积操作函数 。对于后者,本文标记为:cuconv 。
对于 Torch,跟上面的 LeNet 一样,我们既使用了 cuDNN 卷积卷积加速库,又使用了 cunn 库、fbcunn 库,并分别做了时间消耗统计。
由于 fbcunn 库,当 stride lengths 大于 1 的时候,不支持。所以实现这个版本的 AlexNet 的时候,一开始的卷积操作,我们使用了 cuDNN 的库函数,剩下的卷积操作,我们使用 fbcunn 库来完成。此外,fbcunn 库、cunn 库不支持 grouping 层。
下面的表,展示了当 batch size 等于
256
的时候,五个深度学习框架的 AlexNet 训练的效率统计:
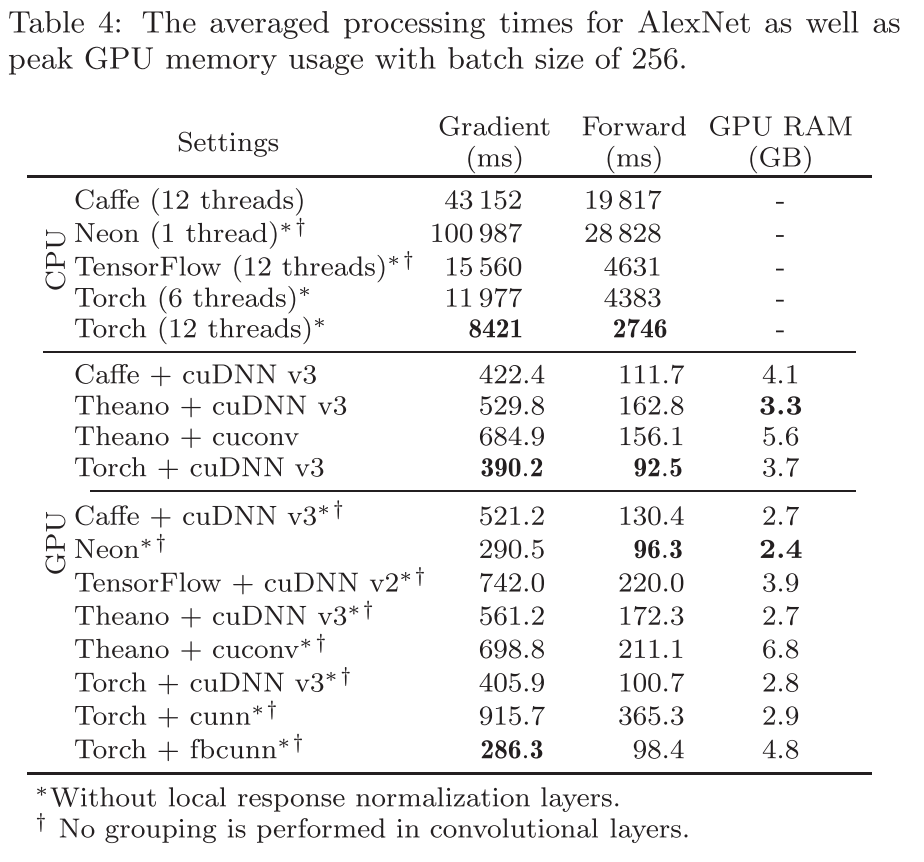
为了更好的比较,每个框架的数据加载时间、数据预处理时间(mean normalization)被我们去除掉了。
我们还汇报了 GPU 显存使用的峰值,来展示每个框架的的效率。
在 CPU 实验中,Torch 的性能最好,与上面 LeNet 的测试结果相似。使用 GPU 时的加速效果比 LeNet 中更明显(提高了至少
25×
)。同时,Torch 在 GPU 上的 梯度计算 性能最好(上面 LeNet 实验时 Theano,不过那时候 Torch 与 Theano 相差无几)。但是在前向传播 中,Neon 的性能最好,但是 Torch 也紧随其后,与之相差无几(Neon 中的没有 LRN 层,同时 grouping 设置为
1
)。
与 LeNet 相似,TensorFlow 效果最差…
下面的图,展示了在 GPU 实验上(无 LRN 层,grouping 设置为
1
),当batch size 的大小设置不同的值时,五个深度学习框架的性能表现:
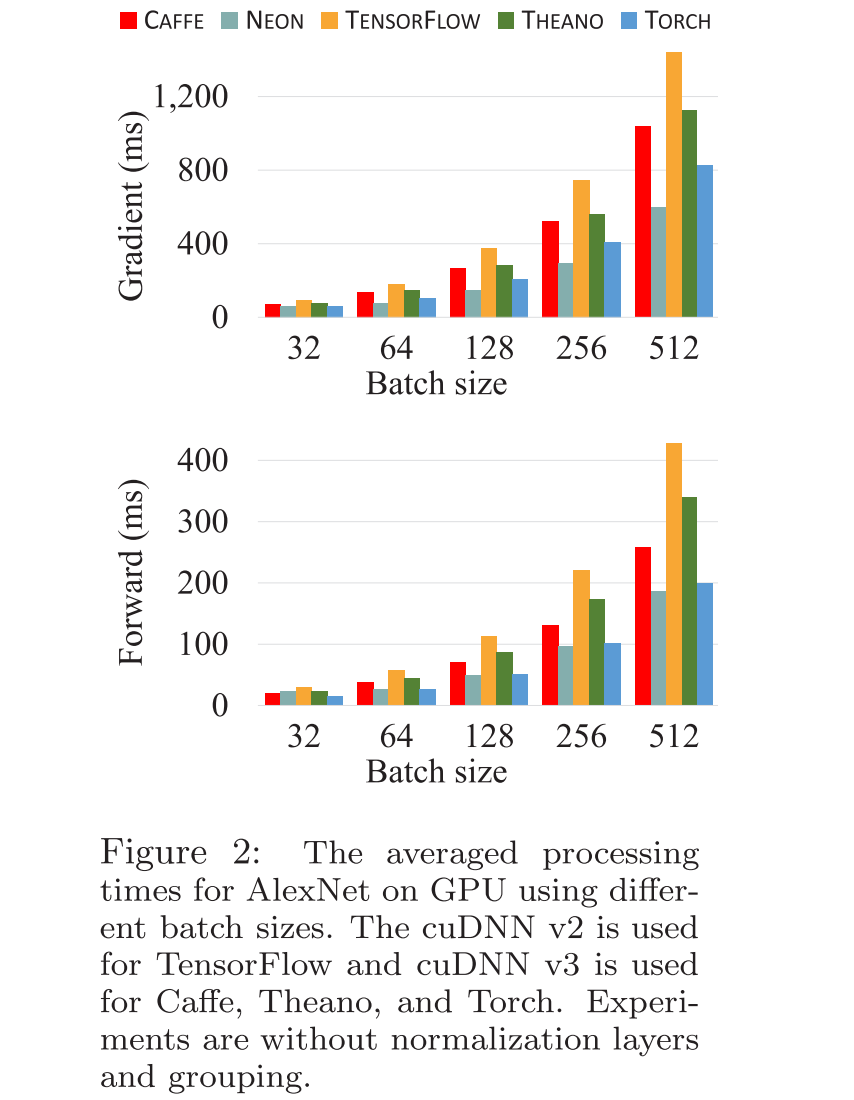
在 前向传播 性能测试上,Neon、Torch 的性能表现一直很优异,时间都最短。但是在 梯度计算 测试中,Neon 最好。
GPU 的使用效率上,caffe、Theano、Torch 的GPU使用效率都差不多(当使用 cuDNN 的时候),但是 Neon 的使用效率最高。TensorFlow 的消耗最大。
在本实验中,还注意到,caffe 中使用的 LMDB 数据库的性能相比较于 Neon 的,Theano 的,Torch 的数据读取,更高效,因为它支持 并发读取(concurrent read) 。caffe 还使用了 pre-fetching 来消除 IO 延迟。所以,Neon、Theano、Torch 在以后的改进中,可以加入对 LMDB 数据读取、pre-fetching 的支持。
论文中接下去在 栈式自编码网络(stacked autoencoders)、长短期记忆网络(LSTM)中的实验,由于我对这两种网络研究不深,所以先搁下,以后有机会再写。
Conclusions
通过上面的实验,以 梯度计算时间(gradient computation time)、前向传播时间(forward time) 为基准,比较了五个较为有影响力的深度学习框架:caffe、Theano、Neon、Torch 以及 TensorFlow 的性能。总结如下:
- Theano、Torch 是两个最具有扩展性的深度学习框架,无论在支持的各种网络层种类数量上,或者是在支持的各种库上。symbolic differentiation 是 Theano 中对于 非标准深度网络架构(non-standard deep architecture) 提供的最有用的特性。Torch 正在补上这个空缺,可以参考这个博客:https://blog.twitter.com/2015/autograd-for-torch
- 在 CPU 上 training 以及 deploy,对于任何的网络模型,Torch 的性能都最优,其次是 Theano,Neon 的在 CPU 上的性能最差
- 在 GPU 上 deploy 已经训练好的卷积和全连接网络(也就是 前向传播过程),Torch 也是最适合的,其次是 Theano
- 在 GPU 上 training 卷积和全连接网络,Theano 在小网络模型(LeNet)的表现最好,在大网络模型(AlexNet)上,Torch 性能最佳。Neon 在大网络模型上也非常有优势
- Torch 受益于它众多的扩展库及文档(这个确实,Torch 的文档阅读性很强,Theano 也不错),还有 Torch 的错误调试工具也很有优势
- TensorFlow 是非常具有扩展性的一个深度学习框架,尤其是在不同情况的各种设备上,进行深度学习框架部署时,更方便稳定。但是在单机上,它的表现就不具有那么强的竞争力了
Postscript
看完这篇文章后,我发现其实本文还少了一个很重要的框架:MXnet 。MXnet 是由DMLC 团队 开发的,主要贡献者有 发明XGBoost 的陈天奇 等等大神。在一些测试中,它的性能已经优于上面的几个框架,而且它也支持分布式,能够运行 Torch 的所有代码(我看 MXnet 的一个作者的微博上说的…没试过…)。
MXnet 与 caffe、TensorFlow 之间的对比,我推荐一篇博客吧,像上文中那样具体的实验分析在这里就先不写了。博客地址:http://chenrudan.github.io/blog/2015/11/18/comparethreeopenlib.html,个人感觉现在 MXnet 就是 model 太少了,不像 caffe,都有 Caffe Model Zoo ……
另外,再推荐一篇 Github 上的文章:https://github.com/zer0n/deepframeworks,也是对 Caffe、CNTK、TensorFlow、Theano、Torch 做了比对。从Modeling Capability 、Interfaces、Model Deployment、Performance、Architecture 这几个方面做了比较。
最后
以上就是包容曲奇最近收集整理的关于深度学习领域开源框架对比的全部内容,更多相关深度学习领域开源框架对比内容请搜索靠谱客的其他文章。








发表评论 取消回复