1、一般流程
- 数据处理
有无标注好的数据,如果有标注数据,数据增广之后是否可以让模型很好的收敛;如果没有标注数据,找一找公开带标注的数据集里面有没有可以迁移学习的。 - 高效训练
因为之后模型压缩损失精度,就要提前在训练时尽可能把精度达到更高、缩短训练时间。比如大batch size和Linear scaling、warm up、Zero γ 、no bias decay等的方法。同时优先考虑mobilenet等backbone,看精度是否在要求内。听说,有条件的会搜索一下网络结构。 - 推理引擎
优化使用推理引擎来进行优化,TVM、Nccn、tensorRT、Tensorflow-lite、Tengine、Xilinx vitis 、Huawei ruyi。各家的流程主要有一些剪枝、量化、蒸馏等。量化中也会重新训练一部分矫正数据集,达到更好的效果。但量化训练(量化感知训练)之后的网络权重就和推理引擎耦合起来了,所以放在了推理引擎优化来讲。但其实训练后量化不管有没有经过矫正损失精度还是蛮多的。所以知识蒸馏看起来还是蛮不错的,看到paddle放出来过一个结果,8位定点数量化的学生模型不仅参数来下降了70%+,精度还提了1%。 - 加速硬件选取
可以看看roofline模型,软件优化的trick之后,硬件的加速也很重要。使用并行加速硬件(GPU、FPGA)或者异构计算(CPU+FPGA、CPU+加速器)可以有效提高推理速度,但成本也增加的比较多。比较实际的办法,是复用这些加速器,一拖多、但带宽的限制也比较大。看到一些文章在offloading或model partition,希望早日有好的工具release。 上线前测试评估 - Fuzz测试工具
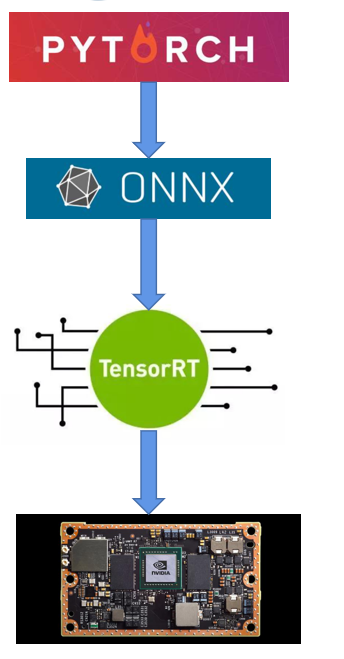
例如:pytorch训练模型导出到ONNX中间模型,然后TensorRT。写一个C++的程序加载,跑inference,显示结果。
2、深度学习模型部署方面,针对nvidia的gpu,看看cuda,tensorRT的document,自己尝试着把一个检测或者分割的模型部署到实验室的机器上。针对移动端的cpu,gpu,看看mnn,学习下mnn的code design。很多非常好的profiling,可视化工具。针对fpga设备,可以看看hls,opencl,verilog。毕竟直接拿现成的tool把model中的op翻译成hls,opencl代码还不是非常高效,很多东西还是直接写HDL所带来的speed up才更直接。这就和很多时候在arm架构的cpu上去优化算法,直接手写汇编所带来的提升更加直接。
常见的主流的工业部署方案:
A tensorRT官方文档:https://docs.nvidia.cn/deeplearning/tensorrt/install-guide/index.html#overview
B openvino:https://docs.openvinotoolkit.org/latest/index.html
方案路线
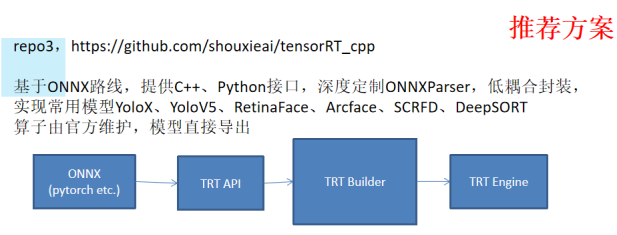
链接:https://www.bilibili.com/video/BV1Xw411f7FW
链接2:https://www.bilibili.com/video/BV1Ag411c7Jf
intel 神经棒

其他资源:1、Jetson Nano 是一款功能强大的小型计算机,专为支持入门级边缘 AI 应用程序和设备而设计。
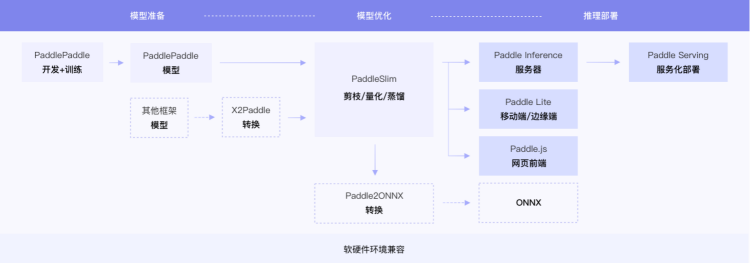
链接3:https://www.paddlepaddle.org.cn/wholechain
体验百度的BML平台:https://ai.baidu.com/bml/app/release/easyedge/list
推荐的简单技术方案

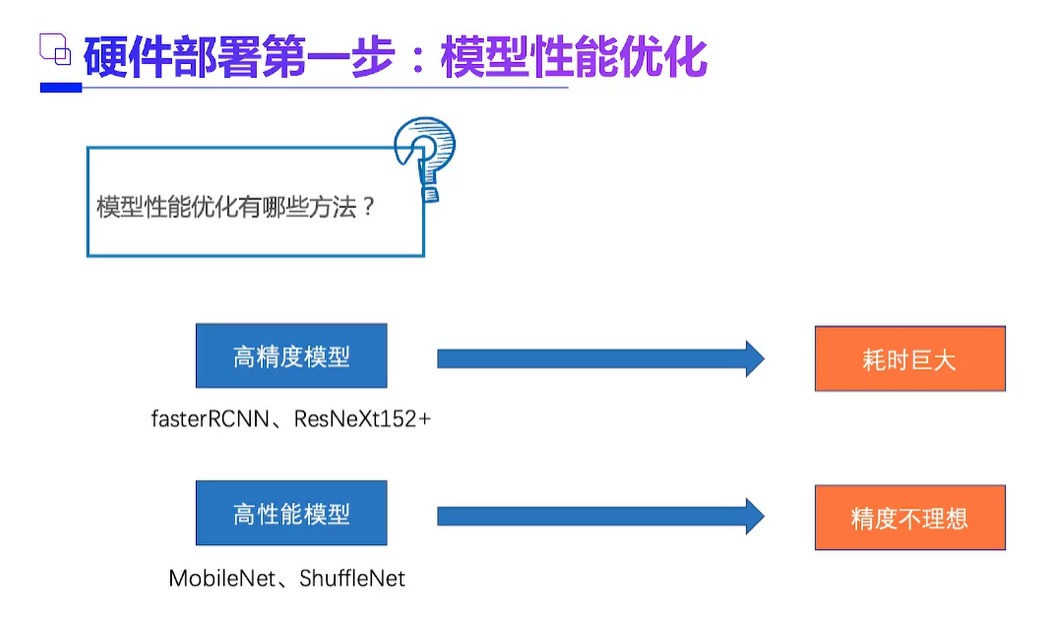
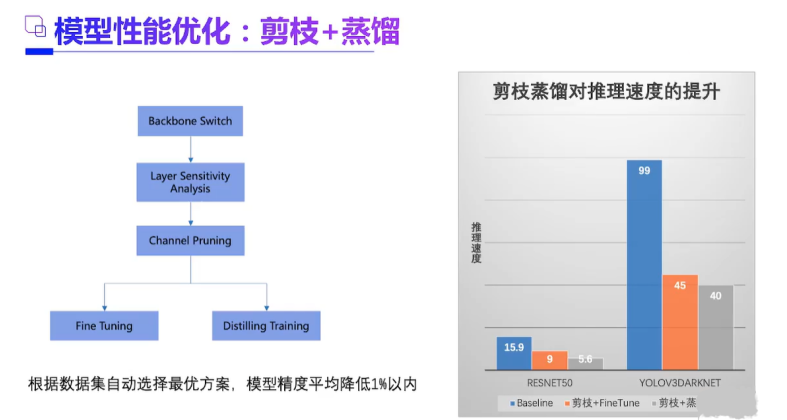
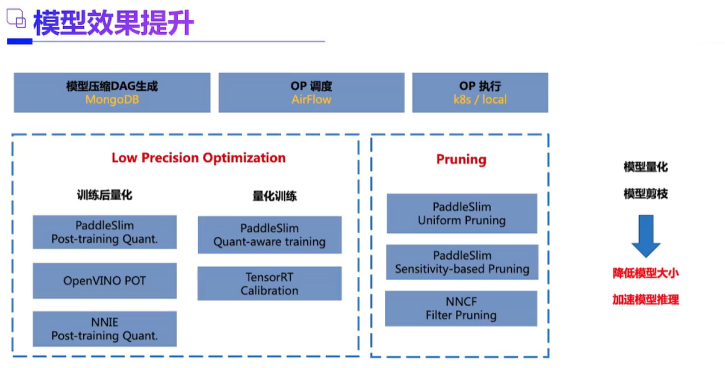

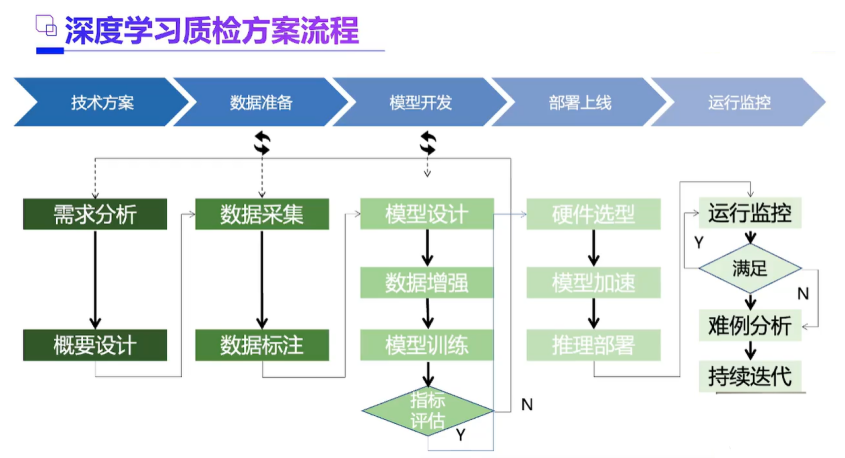

3、最大的困难一在工程优化,量化压缩如何做好,能不能剪枝,如何科学安排前处理,数据加载,推理,后处理的整个pipeline等等。现在很多工具都自动化了,但是需要人为干涉的地方还是很多。有时候还能整出玄学来。学好C++很重要,起码能看懂各种关于部署精巧设计的框架。

总结:学术圈的模型往往不能直接拿来用,那些模型往往为了一点精度而浪费了很多计算资源,这对工业圈来说,肯定是本末倒置了。有些学术圈的模型还是做的比较好的,比如yolo系列,尤其是yolov5。
最后
以上就是悦耳小甜瓜最近收集整理的关于深度学习工业部署整理笔记的全部内容,更多相关深度学习工业部署整理笔记内容请搜索靠谱客的其他文章。








发表评论 取消回复