本文主要记录一些深度学习中的一些trick的使用及其原因 不定期更新
为什么激活函数更喜欢ReLU而不是tanh或者sigmoid
当我们网络比较深的时候,ReLU往往表现更好,因为ReLU只有一个拐点,而tanh/sigmoid有两个拐点(这里叫拐点不太准确),之后曲线就都趋近于平缓,这可能会导致梯度消失的问题,当输入到激活函数的值很大或很小时,会导致在反向传播的时候会导致这部分的导数很小,使得该部分前面的网络无法训练。
对输入进行normalize
一般来说应该在训练前,对于训练集做归一化,使训练数据的每个维度的均值为0。
举例来说,对于一个神经网络的输入,如果某层节点的输入始终为正数,那么在更新与该结点连接的权重的时候,假设该结点的输出为
a
i
a_i
ai,那么梯度为
∂
L
∂
a
i
x
i
frac{partial{L}}{partial{a_i}}x_i
∂ai∂Lxi,因为
x
i
x_i
xi始终为正,那么更新方向就完全取决于
∂
L
∂
a
i
frac{partial{L}}{partial{a_i}}
∂ai∂L的方向,而这可能会导致zigzag的更新方式,更新效率低下。
使得训练数据的各个维度的方差相同/相似,一般可调整为1。
如果不同的维度的数据尺度大小相差很多,那么各权重还要学着去适应不同维度的大小尺度,除非有一些维度已知的没那么重要,那么可以相对的使其scale小一些,降低它在学习过程中的重要性。
降低神经网络各结点输入值的相关性
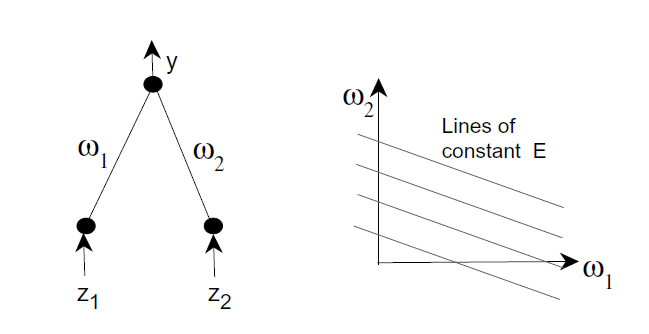
如下图左所示,如果输入
z
1
z1
z1和
z
2
z2
z2线性相关,假设
z
2
z2
z2的输入始终为
z
1
z1
z1输入的两倍,即
y
=
w
1
z
1
+
w
2
z
2
=
w
1
z
1
+
2
w
2
z
1
y = w_1z_1 + w_2z_2 = w_1z_1 + 2w_2z_1
y=w1z1+w2z2=w1z1+2w2z1等价于
w
1
+
2
w
2
=
y
z
1
w_1+2w_2 = frac{y}{z_1}
w1+2w2=z1y,根据输入
z
1
z_1
z1的变化,
w
1
w_1
w1与
w
2
w_2
w2的关系始终满足下图右中的某一条直线,所以当
w
1
w_1
w1与
w
2
w_2
w2满足某条直线的时候,而沿着该直线的更新就没有用处了,所以在一个2-D范围内,很容易造成很多无效的更新,增长训练时间。
在参数训练时对参数加上L1/L2正则化,在训练一段时间之和再开始做正则化
L
=
c
(
w
)
+
α
R
(
w
)
L= c(w) + alpha R(w)
L=c(w)+αR(w)
w
i
=
w
i
−
η
∂
L
∂
w
i
=
w
i
−
η
(
∂
c
∂
w
i
+
α
∂
R
∂
w
i
)
w_i = w_i - etafrac{partial{L}}{partial w_i} = w_i - eta(frac{partial{c}}{partial{w_i}}+alphafrac{partial{R}}{partial{w_i}})
wi=wi−η∂wi∂L=wi−η(∂wi∂c+α∂wi∂R)
对于
L
2
L2
L2正则化,
R
(
w
)
=
∣
∣
w
∣
∣
2
R(w) = ||w||^2
R(w)=∣∣w∣∣2
所以
w
i
=
w
i
−
η
(
∂
c
∂
w
i
+
α
∗
2
w
i
)
=
(
1
−
2
α
η
)
w
i
−
η
∂
c
∂
w
i
w_i = w_i - eta(frac{partial{c}}{partial{w_i}}+alpha*2w_i) = (1-2alphaeta)w_i - etafrac{partial{c}}{partial{w_i}}
wi=wi−η(∂wi∂c+α∗2wi)=(1−2αη)wi−η∂wi∂c
相当于在每一个更新权重的时候,为
w
i
w_i
wi乘上一个小于1的权重
对于
L
1
L1
L1正则化,
R
(
w
)
=
Σ
i
∣
w
i
∣
R(w) = Sigma_i|w_i|
R(w)=Σi∣wi∣
所以
w
i
=
w
i
−
η
(
∂
c
∂
w
i
+
α
s
i
g
n
(
w
i
)
)
w_i = w_i - eta(frac{partial{c}}{partial{w_i}}+alpha sign(w_i))
wi=wi−η(∂wi∂c+αsign(wi))
为什么在开始训练一段时间之后再做正则化
因为weight space的原点类似于loss function的一个saddle point,如果一开始就做正则化的话,可能会导致weights都变成0,然后网络就不会work了,所以这也说明了权重正确初始化的重要性。
CNN网络擅长处理什么
CNN网络擅长处理的图片最好有以下三个性质
Locality
一般对于一张图片来说,相邻的像素往往可能有着相似的颜色,随着像素间距离的增大,这种相似的可能性也随之下降,这种小范围内的相似性有利于CNN去挖掘pattern
Stationarity
相同的pattern可以在图片的任何地方出现
Compositionality
图像是由各pattern层级组成的,和网络中的多层神经元相对应,后面的神经元能够从前面神经元的输出从更大的感受野中提取信息
Activation Functions
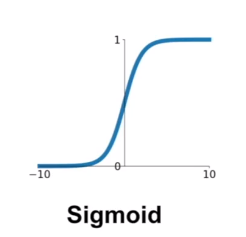
Sigmoid的问题:
(1)梯度消失,对于较正或者较负的输入,在反向传播的时候,梯度接近是0
(2)输出不是zero-centered,原因和为什么一般要对输入进行normalize是一样的
(3)exp()运算的计算代价
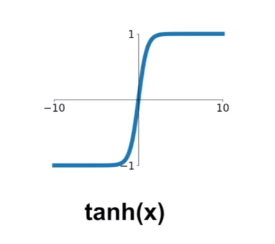
tanh的问题:
(1)同sigmoid一样的梯度消失的问题
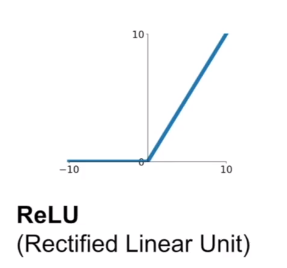
ReLU
(1)在正向不会有梯度消失
(2)计算代价低,收敛快
(3)输出不是zero-centered
(4)负向仍然存在梯度消失的问题(不好的weights初始化;学习率过高,梯度对weights的更新太大)
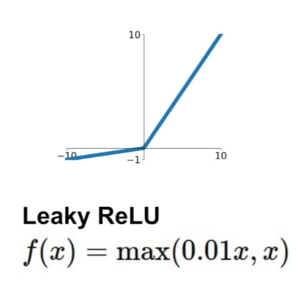
Leaky ReLU
(1)没有梯度消失的问题
(2)一定程度上解决输出不是zero-centered的问题
(2)PReLU:
f
(
x
)
=
m
a
x
(
α
x
,
x
)
f(x)=max(alpha x, x)
f(x)=max(αx,x),相当于把Leaky ReLU的0.01参数化了
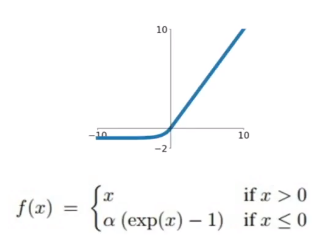
ELU:
(1)对离群点有一定的鲁棒性,因为在负向随着
x
x
x变小梯度会逐渐消失
(2)一定程度上解决输出不是zero-centered的问题
参考资料:
Neural Networks Tricks of the Trade
NYU《deep learning》course 2020
CS231n
最后
以上就是称心大树最近收集整理的关于深度学习科学炼丹的全部内容,更多相关深度学习科学炼丹内容请搜索靠谱客的其他文章。








发表评论 取消回复