前言
众所周知,Pytorch是一个非常流行且深受好评的深度学习训练框架。这与它的两大特性“动态图”、“自动微分”有非常大的关系。“动态图”使得pytorch的调试非常简单,每一个步骤,每一个流程都可以被我们精确的控制、调试、输出。甚至是在每个迭代都能够重构整个网络。这在其他基于静态图的训练框架中是非常不方便处理的。在静态图的训练框架中,必须先构建好整个网络,然后开始训练。如果想在训练过程中输出中间节点的数据或者是想要改变一点网络的结构,就需要非常复杂的操作,甚至是不可实现的。而“自动微分”技术使得在编写深度学习网络的时候,只需要实现算子的前向传播即可,无需像caffe那样对同一个算子需要同时实现前向传播和反向传播。由于反向传播一般比前向传播要复杂,并且手动推导反向传播的时候很容易出错,所以“自动微分”能够极大的节约劳动力,提升效率。
动态图
用过caffe或者tensorflow的同学应该知道,在训练之前需要构建一个神经网络,caffe里面使用配置文件prototxt来进行描述,tensorflow中使用python代码来描述。训练之前,框架都会有一个解析和构建神经网络的过程。构建完了之后再进行数据读取和训练。在训练过程中网络一般是不会变的,所以叫做“静态图”。想要获取中间变量的输出,可以是可以,就是比较麻烦一些,caffe使用c++训练的话,需要获取layer的top,然后打印,tensorflow需要通过session来获取。但是如果想要控制网络的运行,比如让网络停在某一个OP之后,这是很难做到的。即无法精确的控制网络运行的每一步,只能等网络运行完了,然后通过相关的接口去获取相关的数据。而pytorch的“动态图”机制就可以对网络实现非常精确的控制。在pytorch运行之前,不会去创建所谓的神经网络,这完全由python代码定义的forward函数来描述。即我们手工编写的forward函数就是pytorch前向运行的动态图。当代码执行到哪一句的时候,网络就运行到哪一步。所以当你对forward函数进行调试,断点,修改的时候,神经网络也就被相应的调试、中断和修改了。也就是说pytorch的forwad代码就是神经网络的执行流,或者说就是pytorch的“动态图”。对forward的控制就是对神经网络的控制。如下图所示:

正因为这样的实现机制,使得对神经网络的调试可以像普通python代码那样进行调试,非常的方便和友好。并且可以在任何时候,修改网络的结构,这就是动态图的好处。
自动微分
上面的动态图详解了pytorch如何构建前向传播的动态神经网络的,实际上pytorch并没有显式的去构建一个所谓的动态图,本质就是按照forward的代码执行流程走了一遍而已。那么对于反向传播,因为我们没有构建反向传播的代码,pytorch也就无法像前向传播那样,通过我们手动编写的代码执行流进行反向传播。那么pytorch是如何实现精确的反向传播的呢?其实最大的奥秘就藏在tensor的grad_fn属性里面。有的同学可能在调试pytorch代码的时候已经不经意的遇到过这个grad_fn属性。如下图所示:
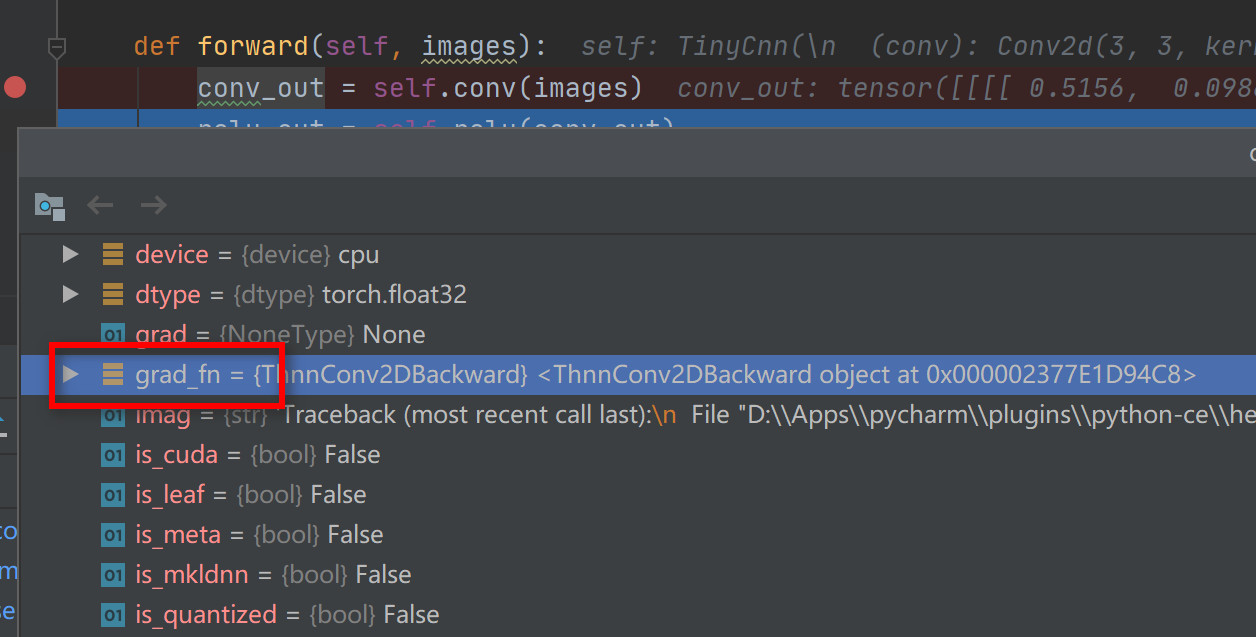
Pytorch中的tensor对象都有一个叫做grad_fn的属性,它实际上是一个链表,实现在pytorch源码的autograd下面。该属性记录了该tensor是如何由前一个tensor产生的。在深入探究grad_fn之前,先来了解一下pytroch中的leaf tensor和非leaf tensor。
Leaf/非leaf tensor:
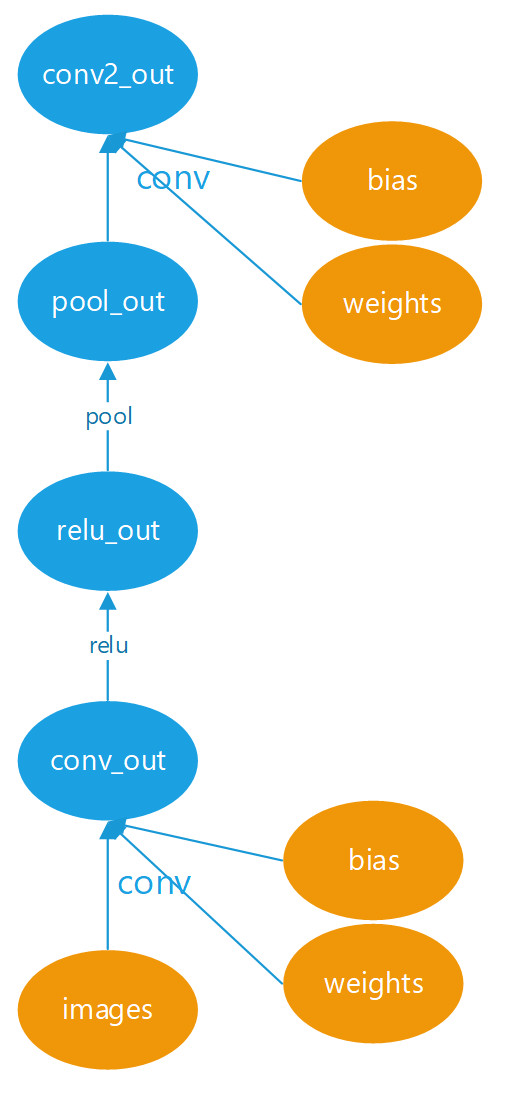
Pytorch中的tensor有两种产生方式,一种是凭空创建的,例如一些op里面的params,训练的images,这些tensor,他们不是由其他tensor计算得来的,而是通过torch.zeros(),torch.ones(),torch.from_numpy()等凭空创建出来的。另外一种产生方式是由某一个tensor经过一个op计算得到,例如tensor a通过conv计算得到tensor b。其实这两种op创建方式对应的就是leaf节点(叶子节点)和非leaf(非叶子节点)。如下图所示,为一个cnn网络中的leaf节点和非leaf节点。黄色的节点对应的tensor就是凭空生成的,是leaf节点;蓝色的tensor就是通过其他tensor计算得来的,是非leaf节点。那么显而易见,蓝色的非leaf节点的grad_fn是有值的,因为它的梯度需要继续向后传播给创建它的那个节点。而黄色的leaf节点的grad_fn为None,因为他们不是由其他节点创建而来,他们的梯度不需要继续反向传播。
深究grad_fn:
grad_fn是python层的封装,其实现对应的就是pytorch源码在autograd下面的node对象,为C++实现,如下图所示:
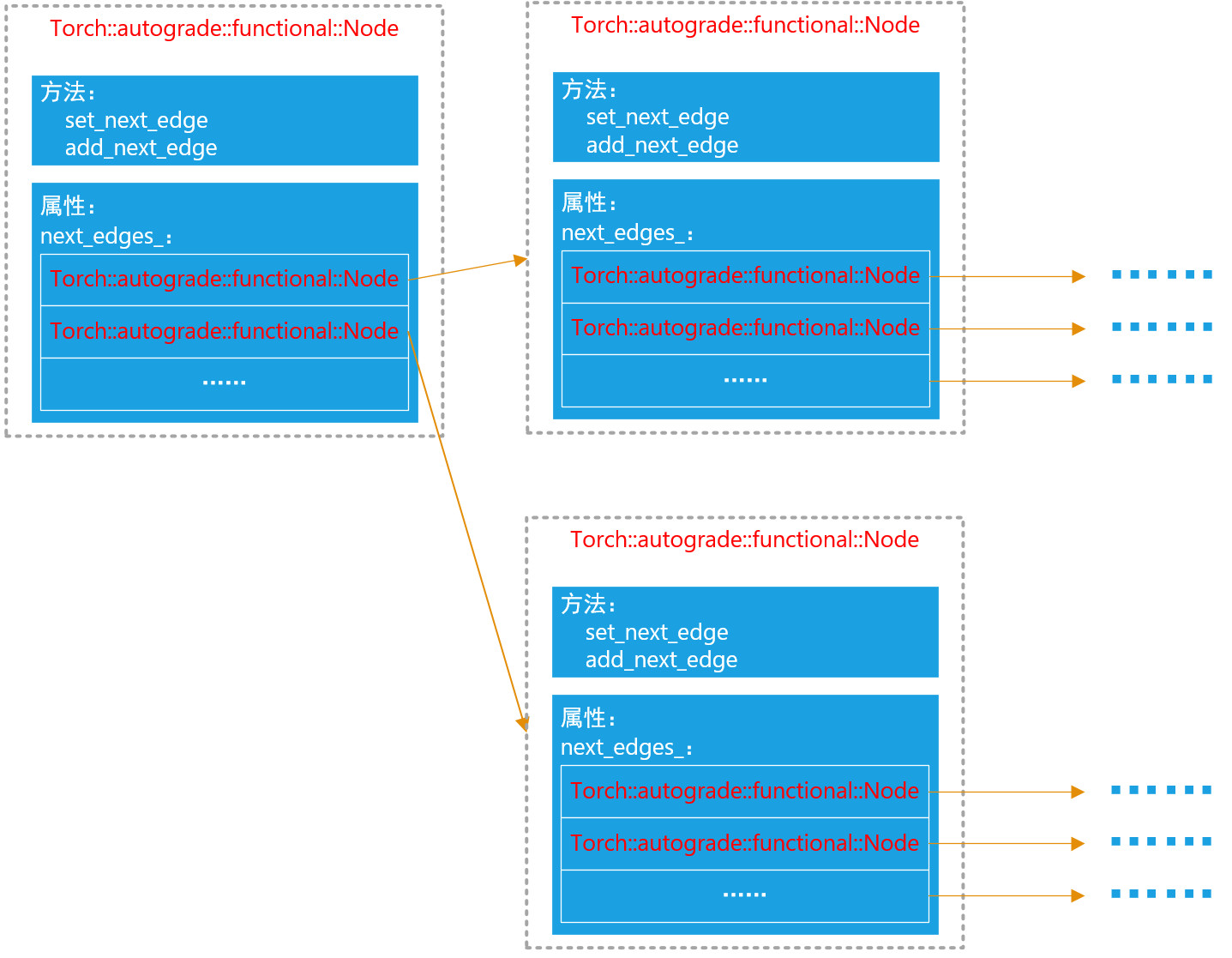
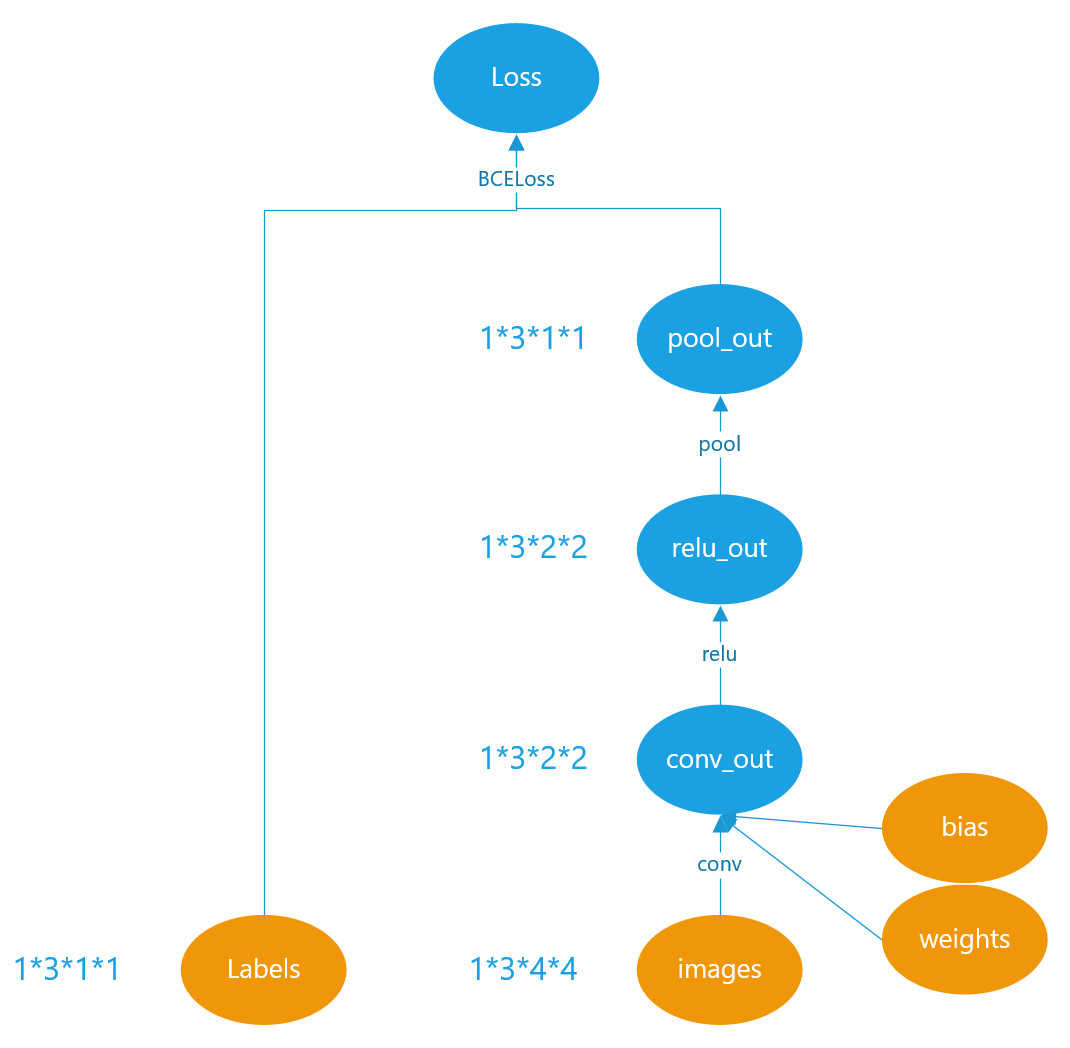
node其实是一个链表,有一个next_edges_属性,里面存储着指向下一级的所有node。注意它不是一个简单的单向链表,因为很多tensor可能是由多个tensor创建来的。例如tensor a = tensor b + tensor c. 那么tensor a的grad_fn属性里面的next_edges就会有两个指针,分别指向tensor b和tensor c的grad_fn属性。在python层,next_edges_属性被封装成了next_functions。因此正确的说法是:tensor a的grad_fn属性里面的next_ functions,指向了tensor b和tensor c的grad_fn属性。其实有了这个完整的链表,就已经完整的表达了反向传播的计算图。就可以完成完整的反向传播了。 下面我们通过一个小例子来进一步说明grad_fn是如何表达反向传播计算图的。首先我们定义一个非常简单的网络:仅有两个conv层,一个relu层,一个pool层,如下图所示(conv层带有参数weights和bias):
对应的代码片段如下所示:
class TinyCnn(torch.nn.Module):
def __init__(self, arg_dict={}):
super(TinyCnn, self).__init__()
self.conv = torch.nn.Conv2d(3, 3, kernel_size=2, stride=2)
self.relu = torch.nn.ReLU(inplace=True)
self.pool = torch.nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, images):
conv_out = self.conv(images)
relu_out = self.relu(conv_out)
pool_out = self.pool(relu_out)
return pool_out
cnn = TinyCnn()
loss_fun = torch.nn.BCELoss()
images = torch.rand((1,3,4,4))
labels = torch.rand((1,3,1,1))
preds = cnn(images)
loss = loss_fun(preds, labels)
loss.backward()那么当代码执行到loss = loss_fun(preds, labels),我们看看loss的grad_fn以及其对应的next_functions:
可以看到loss的grad_fn为:<BinaryCrossEntropyBackward object at 0x000001A07E079FC8>,而它的next_functions为:(<MaxPool2DWithIndicesBackward object at 0x000001A07E08BC88>, 0),继续跟踪MaxPool2DWithIndicesBackward的nex_functions为:(<ReluBackward1 object at 0x000001A07E079B88>, 0),如果继续跟踪下去,整个反向传播的计算图就非常的直观了,使用下图表示:
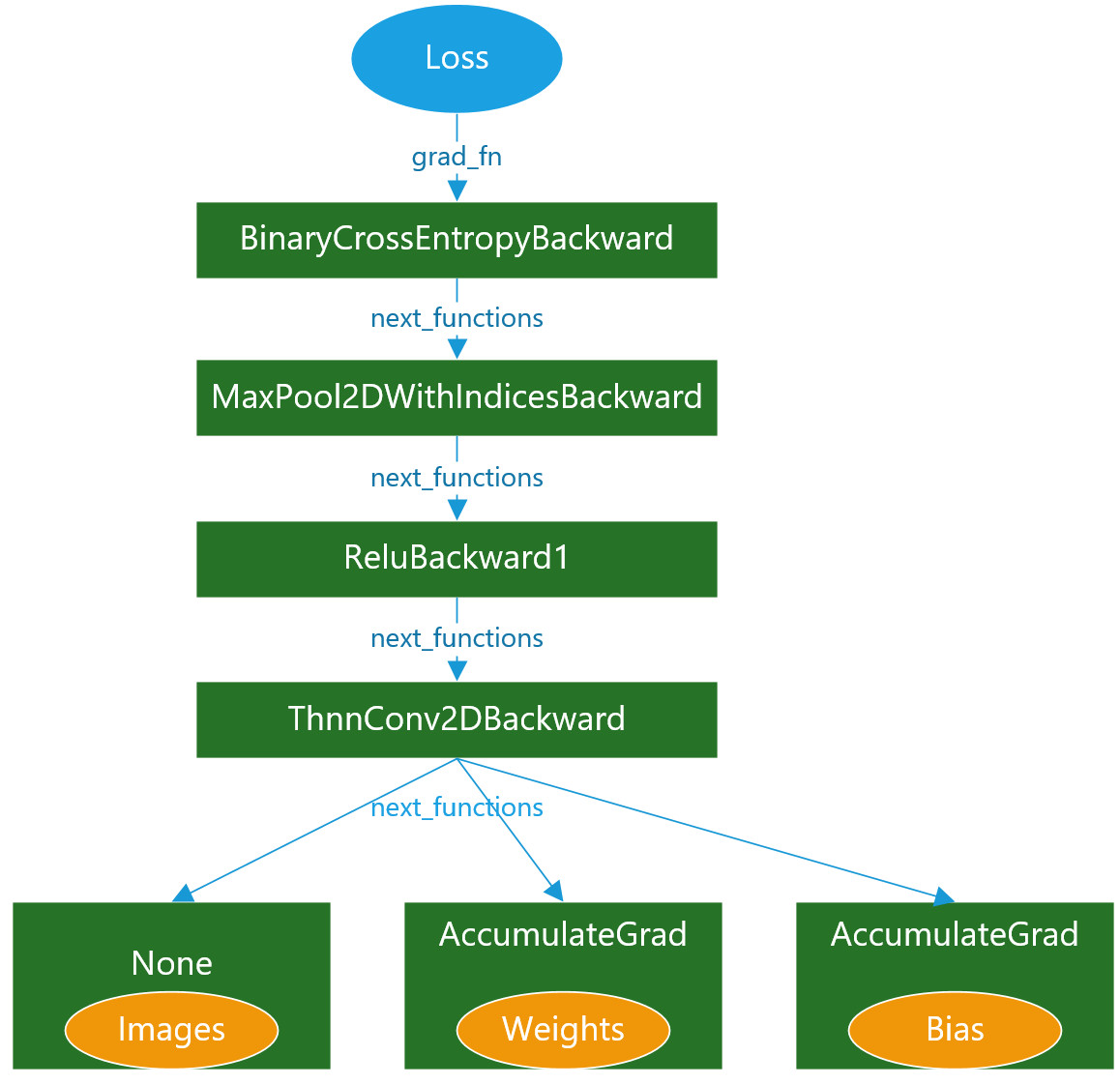
Images由于是叶子节点,且不需要求梯度,因此ThnnConv2DBackward的第一个next_functions对应的是None。而conv中的weights和bias虽然也是叶子节点,但是需要求梯度,因此增加了一个AccumulateGrad的方法,表示可累计梯度,实际上就是对weights和bias的梯度的保存。
grad_fn是如何生成的?
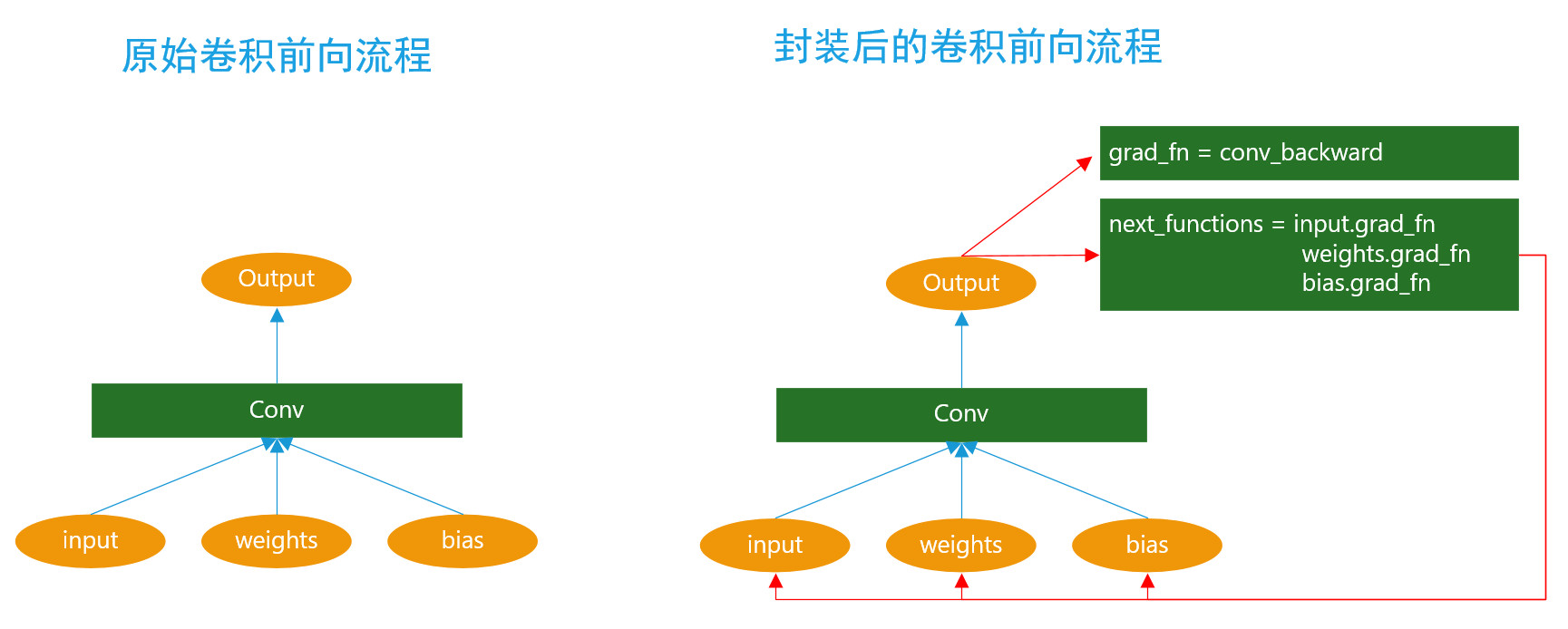
有了上面的介绍,其实大家应该已经大致了解了pytorch自动微分的大致流程。实际上是通过tensor的gran_fn来组织的,grad_fn本质上是一个链表,指向下一级别的tensor的grad_fn,因此通过这样一个链表构成了一个完整的反向计算的动态图。那么最后有一个问题就是tensor的grad_fn是如何构建的?无论是我们自己编写的上层代码,还是在pytorch底层的op实现里面,并没有显示的去创建grad_fn,那么它是在何时,又是如何组装的?实际上通过编译pytorch源码就能发现端倪。Pytorch会对所有底层算子进一个二次封装,在做完正常的op前向之后,增加了grad_fn的设置,next_functions的设置等流程。如下图所示为原始卷积的前向流程和经过pytroch自动封装的卷积前向计算流程对比。可以明显的看到多了一些对grad_fn设置的代码。
后记
以上流程就是pytorch的“动态图”与“自动微分”的核心逻辑。基于pytorch1.6.0源码分析,由于作者才疏学浅,且涉猎范围有限,难免有所错误,如果有不对的地方,还请见谅并指正。
最后
以上就是忐忑黑猫最近收集整理的关于一文详解pytorch的“动态图”与“自动微分”技术的全部内容,更多相关一文详解pytorch内容请搜索靠谱客的其他文章。








发表评论 取消回复