- backend str/Backend 是通信所用的后端,可以是"ncll" "gloo"或者是一个torch.distributed.Backend类(Backend.GLOO)
- init_method str 这个URL指定了如何初始化互相通信的进程
- world_size int 执行训练的所有的进程数
- rank int this进程的编号,也是其优先级
- timeout timedelta 每个进程执行的超时时间,默认是30分钟,这个参数只适用于gloo后端
- group_name str 进程所在group的name
def init_process_group(backend,
init_method=None,
timeout=default_pg_timeout,
world_size=-1,
rank=-1,
store=None,
group_name=''):
pytorch分布式训练通信的后端使用的是gloo或者NCCL,一般来说使用NCCL对于GPU分布式训练,使用gloo对CPU进行分布式训练,MPI需要从源码重新编译。
默认情况下通信方式采用的是Collective Communication也就是通知群体,当然也可以采用Point-to-Point Communication即一个一个通知。
在分布式多个机器中,需要某个主机是主要节点。首先主机地址应该是一个大家都能访问的公共地址,主机端口应该是一个没有被占用的空闲端口。
其次,需要定义world-size代表全局进程个数(一般一个GPU上一个进程),rank代表进程的优先级也是这个进程的编号,rank=0的主机就是主要节点。
同时,rank在gpu训练中,又表示了gpu的编号/进程的编号。
torch.nn.parallel.DistributedDataParallel()不同于torch.nn.DataParallel()``````torch.distributed也不同于 torch.multiprocessing后者是对单机多卡的情况进行处理的.即使是在单机的情况下,DistributedDataParallel的效果也要好于DataParallel,因为:
- 每个流程维护自己的优化器,并在每次迭代中执行完整的优化步骤。
虽然这可能看起来是多余的,因为梯度已经收集在一起并跨进程平均,
因此每个进程都是相同的,这意味着不需要参数广播步骤,从而减少节点之间传输张量的时间。 - 每个进程都包含一个独立的Python解释器,消除了额外的解释器开销和“GIL-thrashing”,
即从单个Python进程中驱动多个执行线程、模型副本或gpu。
这对于大量使用Python运行时的模型(包括具有循环层或许多小组件的模型)尤其重要。
分布式其它api:
torch.distributed.get_backend(group=group) # group是可选参数,返回字符串表示的后端 group表示的是ProcessGroup类
torch.distributed.get_rank(group=group) # group是可选参数,返回int,执行该脚本的进程的rank
torch.distributed.get_world_size(group=group) # group是可选参数,返回全局的整个的进程数
torch.distributed.is_initialized() # 判断该进程是否已经初始化
torch.distributed.is_mpi_avaiable() # 判断MPI是否可用
torch.distributed.is_nccl_avaiable() # 判断nccl是否可用
初始化方式:
- 使用TCP
import torch.distributed as dist
dist.init_process_group(backend, init_method='tcp://10.1.1.20:23456',
rank=args.rank, world_size=4)
- 共享文件系统
import torch.distributed as dist
dist.init_process_group(backend, init_method='file:///mnt/nfs/sharedfile',
world_size=4, rank=args.rank)
- 环境变量
默认情况下使用的都是环境变量来进行分布式通信,也就是指定init_method="env://",这个进程会自动从本机的环境变量中读取如下数据:
MASTER_PORT: rank0上机器的一个空闲端口
MASTER_ADDR: rank0机器的地址
WORLD_SIZE: 这里可以指定,在init函数中也可以指定
RANK: 本机的rank,也可以在init函数中指定
在pytorch的官方教程中提供了以下这些后端
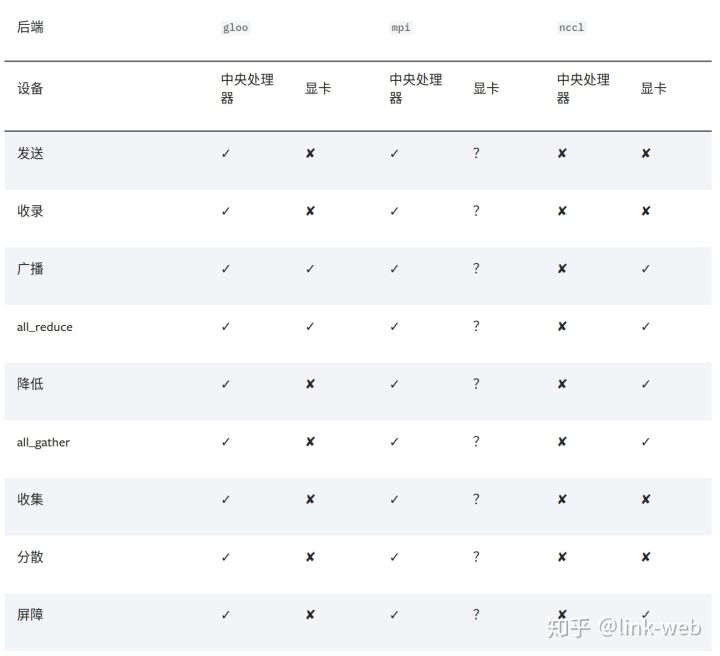
根据官网的介绍, 如果是使用cpu的分布式计算, 建议使用gloo, 因为表中可以看到 gloo对cpu的支持是最好的, 然后如果使用gpu进行分布式计算, 建议使用nccl, 实际测试中我也感觉到, 当使用gpu的时候, nccl的效率是高于gloo的. 根据博客和官网的态度, 好像都不怎么推荐在多gpu的时候使用mpi
对于后端选择好了之后, 我们需要设置一下网络接口, 因为多个主机之间肯定是使用网络进行交换, 那肯定就涉及到ip之类的, 对于nccl和gloo一般会自己寻找网络接口, 但是某些时候, 比如我测试用的服务器, 不知道是系统有点古老, 还是网卡比较多, 需要自己手动设置. 设置的方法也比较简单, 在Python的代码中, 使用下面的代码进行设置就行:
import os
# 以下二选一, 第一个是使用gloo后端需要设置的, 第二个是使用nccl需要设置的
os.environ['GLOO_SOCKET_IFNAME'] = 'eth0'
os.environ['NCCL_SOCKET_IFNAME'] = 'eth0'
我们怎么知道自己的网络接口呢, 打开命令行, 然后输入ifconfig, 然后找到那个带自己ip地址的就是了, 我见过的一般就是em0, eth0, esp2s0之类的, 当然具体的根据你自己的填写. 如果没装ifconfig, 输入命令会报错, 但是根据报错提示安装一个就行了.
dist.init_process_group(backend, init_method='file:///mnt/nfs/sharedfile',
rank=rank, world_size=world_size)
rank/world_size:
这里其实没有多难, 你需要确保, 不同机器的rank值不同, 但是主机的rank必须为0, 而且使用init_method的ip一定是rank为0的主机, 其次world_size是你的主机数量, 你不能随便设置这个数值, 你的参与训练的主机数量达不到world_size的设置值时, 代码是不会执行的.
应用举例:
import os
os.environ['SLURM_NTASKS'] # 可用作world size
os.environ['SLURM_NODEID'] # node id
os.environ['SLURM_PROCID'] # 可用作全局rank
os.environ['SLURM_LOCALID'] # local_rank
os.environ['SLURM_NODELIST'] # 从中取得一个ip作为通讯ip
import os
import re
import torch
import torch.nn as nn
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# 1. 获取环境信息
rank = int(os.environ['SLURM_PROCID'])
world_size = int(os.environ['SLURM_NTASKS'])
local_rank = int(os.environ['SLURM_LOCALID'])
node_list = str(os.environ['SLURM_NODELIST'])
# 对ip进行操作
node_parts = re.findall('[0-9]+', node_list)
host_ip = '{}.{}.{}.{}'.format(node_parts[1], node_parts[2], node_parts[3], node_parts[4])
# 注意端口一定要没有被使用
port = "23456"
# 使用TCP初始化方法
init_method = 'tcp://{}:{}'.format(host_ip, port)
# 多进程初始化,初始化通信环境
dist.init_process_group("nccl", init_method=init_method,
world_size=world_size, rank=rank)
# 指定每个节点上的device
torch.cuda.set_device(local_rank)
model = model.cuda()
# 当前模型所在local_rank
model = DDP(model, device_ids=[local_rank]) # 指定当前卡上的GPU号
input = input.cuda()
output = model(input)
# 此后训练流程与普通模型无异
参考文章:
- 初始化,https://blog.csdn.net/m0_38008956/article/details/86559432
- https://blog.csdn.net/weixin_38278334/article/details/105605994
最后
以上就是坚定黑夜最近收集整理的关于pytorch分布式训练(二init_process_group)的全部内容,更多相关pytorch分布式训练(二init_process_group)内容请搜索靠谱客的其他文章。








发表评论 取消回复