文章目录
- 一、神经网络的学习为何要设定损失函数
- 二、为什么用交叉熵做损失函数
- 1.信息熵
- 2.相对熵(KL散度)
- 3.交叉熵
- 4.为什么使用交叉熵
- 5.使用场景
纯转载文章,链接见文末
一、神经网络的学习为何要设定损失函数
▍基本概念:
神经网络中的“学习”是指从训练数据中自动获取最优权重参数的过程。学习的目的就是以该损失函数为基准,找出能使它的值达到最小的权重参数。
▍问题描述:
可能有人会问:
我们想获得的是能提高识别精度的参数,特意再导入一个损失函数不是有些重复劳动吗?既然我们的目标是获得使识别精度尽可能高的神经网络,那不是应该把识别精度作为指标吗?听起来「好像」很有道理!
▍分析解答:
对于这一疑问,我们可以根据导数在神经网络学习中的作用来回答。在神经网络的学习中,寻找最优参数(权重和偏置)时,要寻找使损失函数的值尽可能小的参数。为了找到使损失函数的值尽可能小的地方,需要计算参数的导数(确切地讲是梯度),然后以这个导数为指引, 逐步更新参数的值。
假设有一个神经网络,现在我们来关注这个神经网络中的某一个权重参数。此时,对该权重参数的损失函数求导,此处导数的含义可以理解为“如果稍微改变这个权重参数的值,损失函数的值会如何变化”。如果导数的值为负,通过使该权重参数向正方向改变,可以减小损失函数的值;反过来,如果导数的值为正,则通过使该权重参数向负方向改变,可以减小损失函数的值。不过,当导数为0时,无论权重参数向哪个方向变化,损失函数的值都不会改变,此时该权重参数的更新会停在此处。
在进行神经网络的学习时,不能将识别精度作为指标。因为如果以识别精度为指标,则参数的导数在绝大多数地方都会变为0,导致参数无法更新。那为什么用识别精度作为指标时,参数的导数在绝大多数地方都会变成0呢?
为了回答这个问题,我们来思考另一个具体例子。假设某个神经网络正确识别出了100个训练数据中的32笔,此时识别精度为32%。如果以识别精度为指标,即使稍微改变权重参数的值,识别精度也仍将保持在32%,不会出现变化。也就是说,仅仅微调参数,是无法改善识别精度的。即便识别精度有所改善,它的值也不会像32.0123 . . . % 这样连续变化,而是变为33%、34%这样的不连续的、离散的值。而如果把损失函数作为指标,则当前损失函数的值可以表示为0.92543 . . . 这样的值。并且,如果稍微改变一下参数 的值,对应的损失函数也会像0.93432 . . . 这样发生连续性的变化。
▍问题延伸
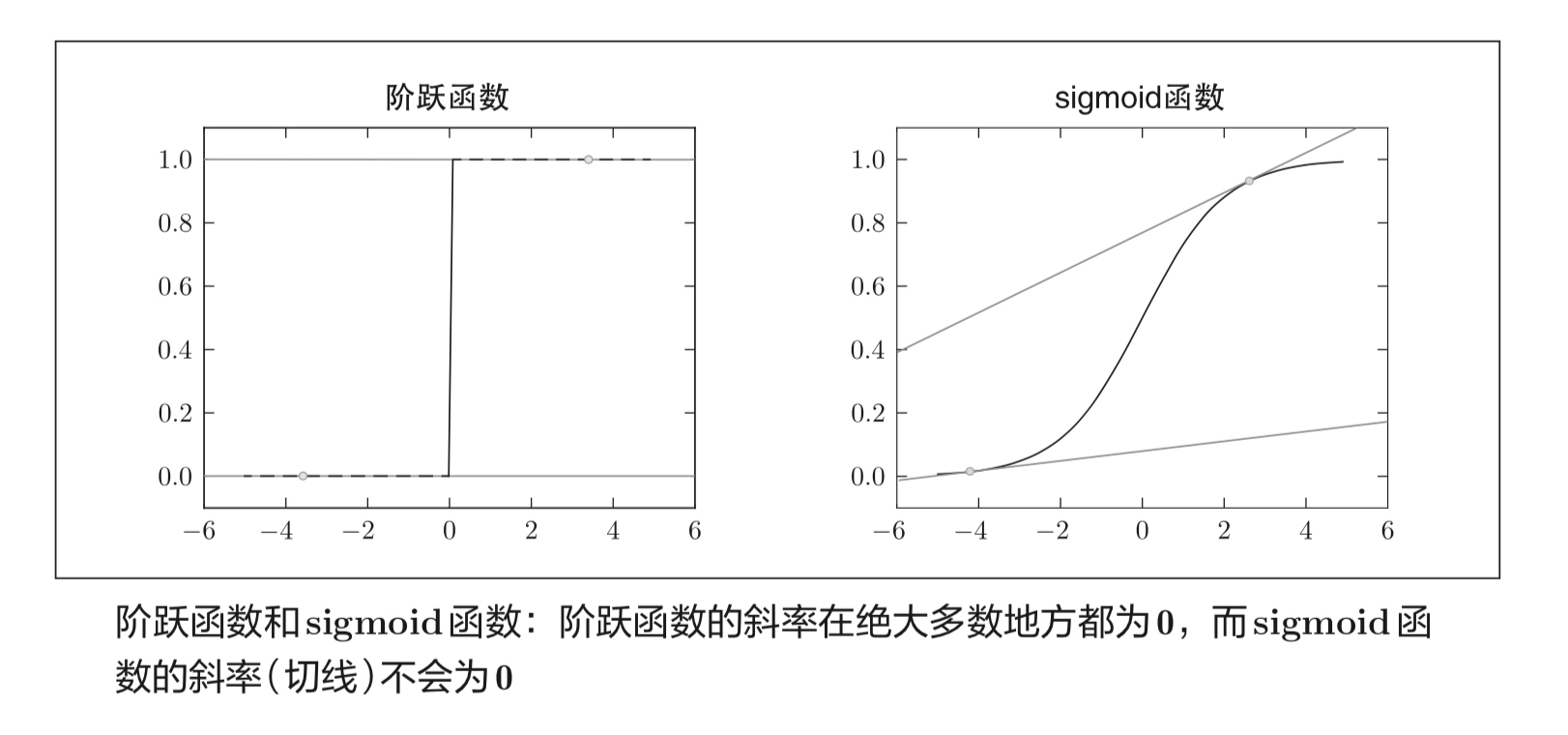
作为激活函数的阶跃函数也有同样的情况。出于相同的原因,如果使用阶跃函数作为激活函数,神经网络的学习将无法进行。原因是阶跃函数的导数在绝大多数地方(除了0以外的地方)均为0。也就是说,如果使用了阶跃函数,那么即便将损失函数作为指标,参数的微小变化也会被阶跃函数抹杀,导致损失函数的值不会产生任何变化。
而sigmoid函数,不仅函数的输出(竖轴的值)是连续变化的,曲线的斜率(导数) 也是连续变化的。也就是说,sigmoid函数的导数在任何地方都不为0。这对神经网络的学习非常重要。得益于这个斜率不会为0的性质,神经网络的学习得以正确进行。
二、为什么用交叉熵做损失函数
前言:
在处理分类问题的神经网络模型中,很多都使用交叉熵 (cross entropy) 做损失函数。
这篇文章详细地介绍了交叉熵的由来、为什么使用交叉熵,以及它解决了什么问题,最后介绍了交叉熵损失函数的应用场景。
要讲交叉熵就要从最基本的信息熵说起
1.信息熵
信息熵是消除不确定性所需信息量的度量。(多看几遍这句话)
信息熵就是信息的不确定程度,信息熵越小,信息越确定。
信 息 熵 = ∑ 1 n ( 信 息 x 发 生 的 概 率 ∗ 验 证 信 息 x 需 要 的 信 息 量 ) 信息熵=sum_{1}^{n}(信息x发生的概率*验证信息x需要的信息量) 信息熵=1∑n(信息x发生的概率∗验证信息x需要的信息量)
(因为事件都有个概率分布,这里我们只考虑离散分布)
举个栗子,比如说:今年中国取消高考了,这句话我们很不确定(甚至心里还觉得这TM是扯淡),那我们就要去查证了,这样就需要很多信息量(去查证);反之如果说今年正常高考,大家回想:这很正常啊,不怎么需要查证,这样需要的信息量就很小。从这里我们可以学到:根据信息的真实分布,我们能够找到一个最优策略,以最小的代价消除系统的不确定性,即最小信息熵。
简而言之,概率越低,需要越多的信息去验证,所以验证真假需要的信息量和概率成反比。我们需要用数学表达式把它描述出来,推导:
考虑一个离散的随机变量
x
x
x,已知信息的量度依赖于概率分布
p
(
x
)
p(x)
p(x),因此我们想要寻找一个函数
I
(
x
)
I(x)
I(x),它是概率
p
(
x
)
p(x)
p(x)的单调函数,表示信息量。
怎么寻找呢?如果我们有两个不相关的事件
x
x
x 和
y
y
y,那么观察两个事件同时发生时获得的信息量应该等于观察到事件各自发生时获得的信息之和,即:
I
(
x
,
y
)
=
I
(
x
)
+
I
(
y
)
I ( x , y ) = I ( x ) + I ( y )
I(x,y)=I(x)+I(y)
因为两个事件是独立不相关的,因此
p
(
x
,
y
)
=
p
(
x
)
p
(
y
)
p(x,y)=p(x)p(y)
p(x,y)=p(x)p(y)
根据这两个关系,很容易看出
I
(
x
)
I ( x )
I(x)一定与
P
(
x
)
P ( x )
P(x) 的对数有关。
由对数的运算法则可知:
l
o
g
a
(
p
(
x
)
p
(
y
)
)
=
l
o
g
a
p
(
x
)
+
l
o
g
a
p
(
y
)
log_a{(p(x)p(y))}=log_a{p(x)}+log_a{p(y)}
loga(p(x)p(y))=logap(x)+logap(y)
因此,我们有
I
(
x
)
=
−
l
o
g
(
p
(
x
)
)
I(x)=−log(p(x))
I(x)=−log(p(x))
其中负号是用来保证信息量是正数或者零。而
l
o
g
log
log函数基的选择是任意的(信息论中基常常选择为2,因此信息的单位为比特bits;而机器学习中基常常选择为自然常数,因此单位常常被称为奈特nats)。
I
(
x
)
I( x )
I(x)也被称为随机变量 x 的自信息 (self-information),描述的是随机变量的某个事件发生所带来的信息量。
以上推导借鉴了这篇博客。
信息熵即所有信息量的期望:
H
(
X
)
=
−
∑
x
p
(
x
)
l
o
g
(
p
(
x
)
)
=
−
∑
i
=
1
n
p
(
x
i
)
l
o
g
(
p
(
x
i
)
)
H(X)=− ∑_{x}p(x)log(p(x))=−∑_{i=1}^{n}p(x_i)log(p(x_i))
H(X)=−x∑p(x)log(p(x))=−i=1∑np(xi)log(p(xi))
其中n为事件的所有可能性。
2.相对熵(KL散度)
相对熵又称KL散度,如果对于同一个随机变量
x
x
x有两个单独的概率分布
p
(
x
)
p(x)
p(x)和
q
(
x
)
q(x)
q(x),可以使用相对熵来衡量这两个分布的差异。
D
K
L
(
p
∣
∣
q
)
=
∑
i
=
1
n
p
(
x
i
)
l
o
g
(
f
r
a
c
(
q
(
x
i
)
p
(
x
i
)
)
D_{KL}(p∣∣q)=∑_{i=1}^{n}p(x_i )log{left.(frac{(q(x_i )}{p(x_i)}right.)}
DKL(p∣∣q)=i=1∑np(xi)log(frac(q(xi)p(xi))
注:
D
K
L
D_{KL}
DKL 越小,表示
p
(
x
)
p(x)
p(x)和
q
(
x
)
q(x)
q(x)的分布越近。
3.交叉熵
交叉熵公式:
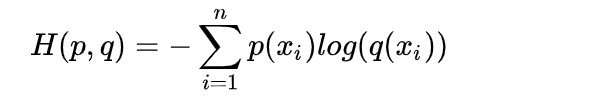
相对熵的推导:
D
K
L
(
p
∣
∣
q
)
=
∑
i
=
1
n
p
(
x
i
)
l
o
g
(
p
(
x
i
)
)
−
∑
i
=
1
n
p
(
x
i
)
l
o
g
(
q
(
x
i
)
)
=
−
H
(
X
)
+
[
∑
i
=
1
n
p
(
x
i
)
l
o
g
(
q
(
x
i
)
)
]
=
[
∑
i
=
1
n
p
(
x
i
)
l
o
g
(
q
(
x
i
)
)
]
−
H
(
X
)
D_{KL}(p||q)=sum_{i=1}^{n}p(x_i)log(p(x_i)) - sum_{i=1}^{n}p(x_i)log(q(x_i)) \ =-H(X)+[sum_{i=1}^{n}p(x_i)log(q(x_i))]\ =[sum_{i=1}^{n}p(x_i)log(q(x_i))]- H(X)
DKL(p∣∣q)=i=1∑np(xi)log(p(xi))−i=1∑np(xi)log(q(xi))=−H(X)+[i=1∑np(xi)log(q(xi))]=[i=1∑np(xi)log(q(xi))]−H(X)
在机器学习中,往往用 p ( x ) p(x) p(x)用来描述真实分布, q ( x ) q(x) q(x)用来描述模型预测的分布。
计算损失,理应使用相对熵来计算概率分布的差异,然而由相对熵推导出的结果看:
相
对
熵
=
交
叉
熵
−
信
息
熵
相对熵 = 交叉熵 - 信息熵
相对熵=交叉熵−信息熵
由于信息熵描述的是消除
p
p
p(即真实分布) 的不确定性所需信息量的度量,所以其值应该是最小的、固定的。那么:优化减小相对熵也就是优化交叉熵,所以在机器学习中使用交叉熵就可以了。
4.为什么使用交叉熵
在机器学习中,我们希望模型在训练数据上学到的预测数据分布与真实数据分布越相近越好,上面讲过了,用相对熵,但是为了简便计算使用交叉熵就可以了。
注意:此处真实数据分布指的就是训练数据的分布(标注)。
交叉熵损失函数:
L
=
−
[
y
l
o
g
y
^
+
(
1
−
y
)
l
o
g
(
1
−
y
^
)
]
L=−[yloghat{y}+(1−y)log (1− hat{y})]
L=−[ylogy^+(1−y)log(1−y^)]
交叉熵损失函数一般用来代替均方差损失函数与sigmoid激活函数组合。
sigmoid激活函数表达式:
σ
(
z
)
=
1
1
+
e
−
z
sigma(z)=frac{1}{1+e^{-z}}
σ(z)=1+e−z1
下面是sigmoid函数及其导数的图像:
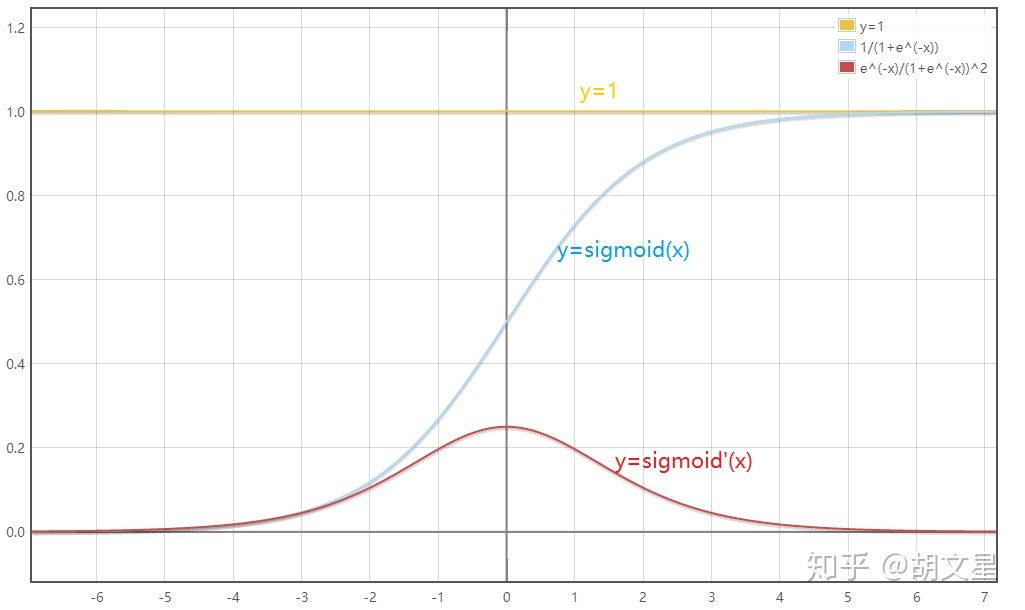
从图中可以看出,对于sigmoid函数,当
x
x
x 的取值越大或越小,函数曲线变得越平缓,意味着导数
σ
′
(
x
)
sigma ^{'}(x)
σ′(x) 越趋近于0。
以单个样本的一次梯度下降为例:
z
=
w
x
+
b
y
^
=
a
=
σ
(
z
)
L
1
(
y
,
a
)
=
1
2
(
y
−
a
)
2
L
2
(
y
,
a
)
=
−
(
y
l
o
g
(
a
)
+
(
1
−
y
)
l
o
g
(
1
−
a
)
)
z=wx+b\ hat{y}=a=sigma(z)\ L_{1}(y,a)=frac{1}{2}(y-a)^2\ L_{2}(y,a)=-(ylog(a)+(1-y)log(1-a))
z=wx+by^=a=σ(z)L1(y,a)=21(y−a)2L2(y,a)=−(ylog(a)+(1−y)log(1−a))
前两个公式公式分别是前向传播的线性和非线性部分,第三个公式公式是均方差损失函数,第四个公式是交叉熵损失函数。梯度下降的目的,直白地说:是减小真实值和预测值的距离,而损失函数用来度量真实值和预测值之间距离,所以梯度下降目的也就是减小损失函数的值。怎么减小损失函数的值呢?变量只有
w
w
w和
b
b
b,所以我们要做的就是不断修改
w
w
w和
b
b
b的值以使损失函数越来越小。(这里例子只有一步,只修改一次)
w
w
w和
b
b
b的更新:
参
数
=
参
数
−
学
习
率
×
损
失
函
数
对
参
数
的
偏
导
参
数
=
参
数
−
学
习
率
×
损
失
函
数
对
参
数
的
偏
导
:
参 数 = 参 数 − 学 习 率 × 损 失 函 数 对 参 数 的 偏 导 参数=参数-学习率×损失函数对参数的偏导:
参数=参数−学习率×损失函数对参数的偏导参数=参数−学习率×损失函数对参数的偏导:
w
=
w
−
α
∂
L
(
y
,
a
)
∂
w
b
=
b
−
α
∂
L
(
y
,
a
)
∂
b
w=w-alpha frac{partial L(y,a)}{partial w}\ b=b-alpha frac{partial L(y,a)}{partial b}
w=w−α∂w∂L(y,a)b=b−α∂b∂L(y,a)
其中
α
alpha
α 表示学习率,用来控制步长,即向下走一步的长度
学习率介绍
我们简单来看一下学习率。在训练神经网络时,如何设置学习率?看看大神们的tricks
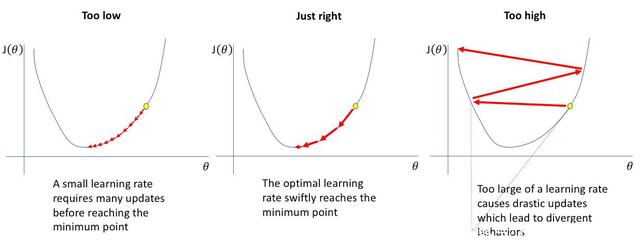
对于具有梯度下降的反向传播的神经网络,(learn_rate)学习率是训练神经网络的关键超参数之一,它的大小,会造成网络训练过程中的loss振幅,以及模型收敛速度.
对于一份陌生的数据,我们在分析完训练数据的各个纬度后,训练时,我们都会试探性地设置一下学习率(learn_rate),当learn_rate比较小时,loss曲线收敛会非常缓慢,但是loss摆动振幅比较小,因为模型权重更新幅度较小. 当learn_rate比较大时,loss曲线收敛快,但是同时,loss摆动振幅剧烈。
那么我们如何找到最佳的学习率呢?
首先我们需要知道,学习率(learn_rate)是来更新网络模型拓扑结构中参数的,那么最佳的学习率(learn_rate),肯定是和网路模型拓扑结构有关,不同的神经网络模型,对应着自己最佳的学习率。
Jeremy Howard(kaggle 冠军) 博主提供率一种思路:
我们初始化一个非常小的学习率(learn_rate)我们可以通过一个简单的实验来观察这一点,在每个小批量之后,我们逐渐提高学习率,记录每次增量的损失。这种逐步增长可以是线性地,也可以是指数级的。
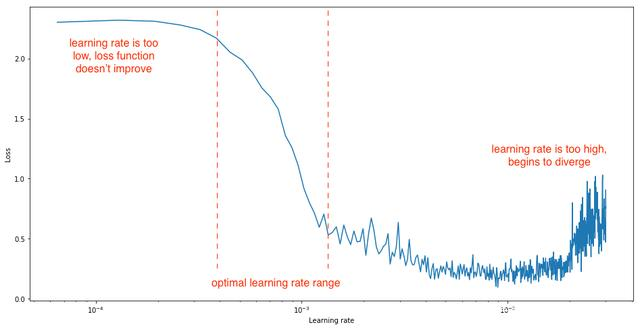
如上图所展现的,如果learn_rate 太小,loss会收敛,但幅度很小,并且未出现大的振幅。当learn_rate进入最佳学习率区域时,您将看到损失函数(loss)快速下降,并且未出现大的振幅。进一步提高学习率(learn_rate),loss会收敛,但是出现振幅,并随着学习率的进一步增大,振幅越来越大,因为参数更新会导致损失“反弹”,甚至偏离最小值。记住,最好的学习率与损失的最大下降有关,所以我们主要对分析图的斜率感兴趣。
除了上文提到的思路外,还有一种学习率退火,也是一种较为常见的方法,它的思路是,学习率初始化时,设置未一个相对较大的值,然后在训练迭代的过程中,逐步的降低学习率,这种方法的意图是:就是保持最大的步伐,最快速的到达loss的鞍部,然后通过逐步调小学习率,来阻止loss出现大的振幅,也就是“反弹”. 这篇笔记中有描述这种方法:Karparthy’s CS231n notes

言归正传,为什么要这样更新参数呢,讲完下面的关键点我们会解释一下。
关键点来了,为什么用交叉熵而不是均方误差呢?
均方误差对参数的偏导:
∂
L
1
(
y
,
a
)
∂
w
=
−
∣
y
−
σ
(
z
)
∣
σ
′
(
z
)
x
∂
L
1
(
y
,
a
)
∂
b
=
−
∣
y
−
σ
(
z
)
∣
σ
′
(
z
)
frac{partial L_{1}(y,a)}{partial w}=-|y-sigma (z)|sigma ^{'}(z)x\ frac{partial L_{1}(y,a)}{partial b}=-|y-sigma (z)|sigma ^{'}(z)\
∂w∂L1(y,a)=−∣y−σ(z)∣σ′(z)x∂b∂L1(y,a)=−∣y−σ(z)∣σ′(z)
交叉熵对参数的偏导:
∂
L
2
(
y
,
a
)
∂
w
=
x
[
σ
(
z
)
−
y
]
∂
L
2
(
y
,
a
)
∂
b
=
σ
(
z
)
−
y
frac{partial L_{2}(y,a)}{partial w}=x[sigma(z)-y]\ frac{partial L_{2}(y,a)}{partial b}=sigma(z)-y\
∂w∂L2(y,a)=x[σ(z)−y]∂b∂L2(y,a)=σ(z)−y
注:为了简洁,以上公式中用
z
z
z代替了
w
x
+
b
wx + b
wx+b
从以上公式可以看出:均方误差对参数的偏导的结果都乘了sigmoid的导数
σ
′
(
z
)
x
sigma ^{'}(z)x
σ′(z)x
而之前看图发现sigmoid导数在其变量值很大或很小时趋近于0,所以偏导数很有可能接近于0。
由参数更新公式:
参
数
=
参
数
−
学
习
率
×
损
失
函
数
对
参
数
的
偏
导
参 数 = 参 数 − 学 习 率 × 损 失 函 数 对 参 数 的 偏 导
参数=参数−学习率×损失函数对参数的偏导
可知,偏导很小时,参数更新速度会变得很慢,而当偏导接近于0时,参数几乎就不更新了。
反观交叉熵对参数的偏导就没有sigmoid导数,所以不存在这个问题。这就是选择交叉熵而不选择均方差的原因。
梯度下降的原理,为什么要这样更新参数
借用吴恩达深度学习课上的图:
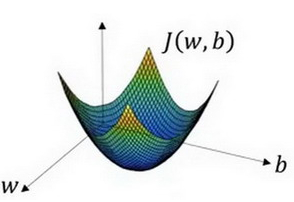
在这个图中,横轴表示参数
w
w
w和
b
b
b,在实践中,
w
w
w可以是更高的维度,但是为了更好地绘图,我们定义w和b都是单一实数,损失函数
J
(
w
,
b
)
J ( w , b )
J(w,b)是在水平轴和上的曲面,因此曲面的高度就是
J
(
w
,
b
)
J ( w , b )
J(w,b)在某一点的函数值。我们所做的就是找到使得损失函数
J
(
w
,
b
)
J ( w , b )
J(w,b)函数值为最小值时,对应的参数
w
w
w和
b
b
b。
两个参数不太好说明,我们把它简化成一个参数来讲,假设损失函数只有
w
w
w一个参数:
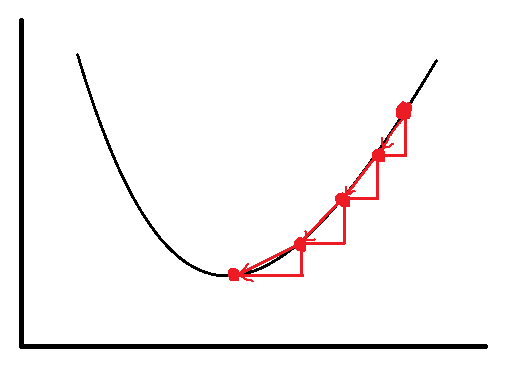
图画的丑,能说明意思就行,曲线是损失函数,参数
w
w
w为横坐标,红色的点记录参数
w
w
w的每次更新(这里例子只有一步,只更新一次)。
损失函数对
w
w
w的偏导
∂
L
1
(
y
,
a
)
∂
w
frac{partial L_{1}(y,a)}{partial w}
∂w∂L1(y,a)相当于曲线的斜率,
w
=
w
−
α
∂
L
1
(
y
,
a
)
∂
w
w=w- alphafrac{partial L_{1}(y,a)}{partial w}
w=w−α∂w∂L1(y,a)
,会使红点像曲线下端移动,这样就减小了损失函数。多个参数也是同样的道理。
5.使用场景
下面是知乎上看到的一张图,图中写得很清楚了。
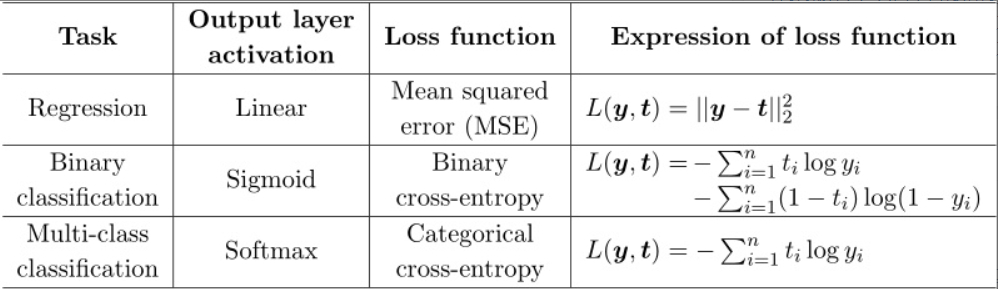
交叉熵损失函数经常用于分类问题中,特别是在神经网络做分类问题时,也经常使用交叉熵作为损失函数,此外,由于交叉熵涉及到计算每个类别的概率,所以交叉熵几乎每次都和sigmoid(或softmax)函数一起出现。
我们用神经网络最后一层输出的情况,来看一眼整个模型预测、获得损失和学习的流程:
1、神经网络最后一层得到每个类别的得分scores;
2、该得分经过sigmoid(或softmax)函数获得概率输出;
3、模型预测的类别概率输出与真实类别的one hot形式进行交叉熵损失函数的计算。
优缺点:
在用梯度下降法做参数更新的时候,模型学习的速度取决于两个值:一、学习率;二、偏导值。其中,学习率是我们需要设置的超参数,所以我们重点关注偏导值。从上面的式子中,我们发现,偏导值的大小取决于
x
i
x_i
xi 和
σ
(
z
)
−
y
sigma(z)-y
σ(z)−y ,我们重点关注后者,后者的大小值反映了我们模型的错误程度,该值越大,说明模型效果越差,但是该值越大同时也会使得偏导值越大,从而模型学习速度更快。所以,使用逻辑函数得到概率,并结合交叉熵当损失函数时,在模型效果差的时候学习速度比较快,在模型效果好的时候学习速度变慢。
文章前半部分:神经网络的学习为何要设定损失函数?
文章后半部分:为什么用交叉熵做损失函数
交叉熵还可以参考知乎上这篇文章,讲的通俗易懂。
最后
以上就是尊敬树叶最近收集整理的关于神经网络的学习为何要设定损失函数以及为什么要使用交叉熵损失函数的全部内容,更多相关神经网络内容请搜索靠谱客的其他文章。
![[深度学习笔记] 3.神经网络入门](https://www.shuijiaxian.com/files_image/reation/bcimg2.png)


![深度学习与计算机视觉[CS231N] 学习笔记(3.1):损失函数(Loss Function)](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)




发表评论 取消回复