pandas提供了多种功能,将Series,DAtaFrame和Panel对象通过索引和关系函数连接起来。
concat
concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)objs:Series,DataFrame或Panel构成的列表。
axis:需要合并链接的轴,0是行,1是列
join:连接方式,
ignore_index:布尔值,默认为False。如果为True,则不要使用连接轴上的索引值,生成的轴被标记为0,…,n-1。
keys:序列,默认无。在最外层构建分层索引。
相同字段表首尾相连:
In [1]: df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
...:
'B': ['B0', 'B1', 'B2', 'B3'],
...:
'C': ['C0', 'C1', 'C2', 'C3'],
...:
'D': ['D0', 'D1', 'D2', 'D3']},
...:
index=[0, 1, 2, 3])
...:
In [2]: df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
...:
'B': ['B4', 'B5', 'B6', 'B7'],
...:
'C': ['C4', 'C5', 'C6', 'C7'],
...:
'D': ['D4', 'D5', 'D6', 'D7']},
...:
index=[4, 5, 6, 7])
...:
In [3]: df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
...:
'B': ['B8', 'B9', 'B10', 'B11'],
...:
'C': ['C8', 'C9', 'C10', 'C11'],
...:
'D': ['D8', 'D9', 'D10', 'D11']},
...:
index=[8, 9, 10, 11])
...:
In [4]: frames = [df1, df2, df3]
In [5]: result = pd.concat(frames,key=['x','y','z'])结果为:
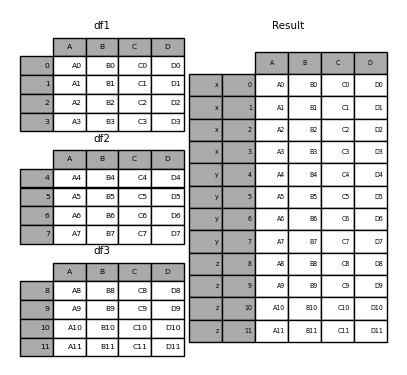
In [7]: result.loc['y']
Out[7]:
A
B
C
D
4
A4
B4
C4
D4
5
A5
B5
C5
D5
6
A6
B6
C6
D6
7
A7
B7
C7
D7横向连接
axis
设置参数axis=1代表横向连接
In [8]: df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
...:
'D': ['D2', 'D3', 'D6', 'D7'],
...:
'F': ['F2', 'F3', 'F6', 'F7']},
...:
index=[2, 3, 6, 7])
...:
In [9]: result = pd.concat([df1, df4], axis=1)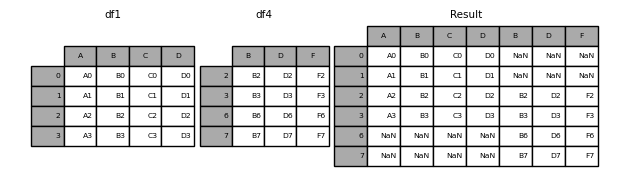
join
join=’inner’得到的是两表的交集,join=’outer’得到的是两表的并集。
In [10]: result = pd.concat([df1, df4], axis=1, join='inner')
In [11]: result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])
apend
result = df1.append(df2)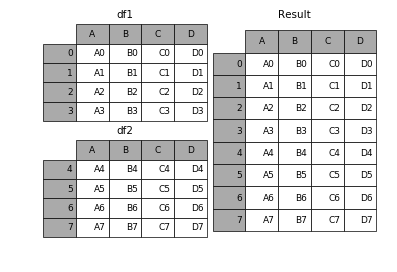
在DataFrame的情况下,索引必须是不相交的,但列不需要是:
result = df1.append(df4)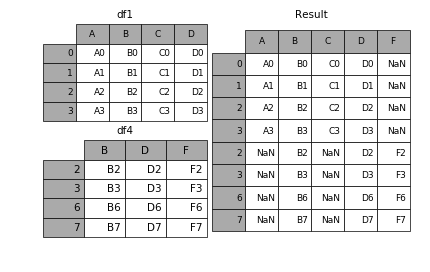
merge
merge和数据库链接操作类似。
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)left:DataFrame对象
right:另一个DataFrame对象
on:要加入的列(名称)。必须在左右DataFrame对象中找到。如果未传递,且left_index和right_index为False,则DataFrames中的列的交集将被推断为连接键
left_on:左侧DataFrame中用作键的列。可以是列名称或长度等于DataFrame长度的数组
right_on:来自右侧DataFrame的列,用作键。可以是列名称或长度等于DataFrame长度的数组
left_index:如果True,请使用左侧DataFrame中的索引(行标签)作为其连接键。在具有MultiIndex(分层)的DataFrame的情况下,级别数必须与来自右侧DataFrame的连接键数匹配
right_index:与left_index使用方式相同,适用于正确的DataFrame
how:’left’,’right’,’outer’,’inner’。默认为inner。有关每种方法的详细说明,请参阅下文
sort:按照字典顺序通过连接键对结果DataFrame进行排序。默认为True,设置为False会大幅提高性能
suffixes:应用于重叠列的字符串后缀的元组。默认为(’_ x’, ‘_ y’)。
copy:始终从传递的DataFrame对象复制数据(默认True),即使不需要重建索引。在许多情况下不能避免,但可以提高性能/内存使用。可以避免复制的情况有些病态,但仍然提供此选项。
indicator:向输出DataFrame中添加一个名为_merge的列,其中包含有关每行源的信息。
In [1]: left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
....:
'key2': ['K0', 'K1', 'K0', 'K1'],
....:
'A': ['A0', 'A1', 'A2', 'A3'],
....:
'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [2]: right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
....:
'key2': ['K0', 'K0', 'K0', 'K0'],
....:
'C': ['C0', 'C1', 'C2', 'C3'],
....:
'D': ['D0', 'D1', 'D2', 'D3']})| 连接方法 | SQL名称 | 描述 |
|---|---|---|
| left | LEFT OUTER JOIN | 仅使用左数据框的键 |
| right | RIGHT OUTER JOIN | 仅使用右数据框的键 |
| outer | FULL OUTER JOIN | 使用来自两个数据框的键的联合 |
| inner | INNER JOIN | 使用两个数据框的键的交集 |
inner
In [3]: result = pd.merge(left, right, how='inner', on=['key1', 'key2'])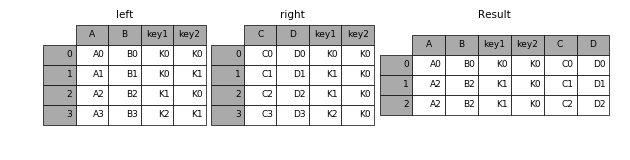
outer
In [4]: result = pd.merge(left, right, how='outer', on=['key1', 'key2'])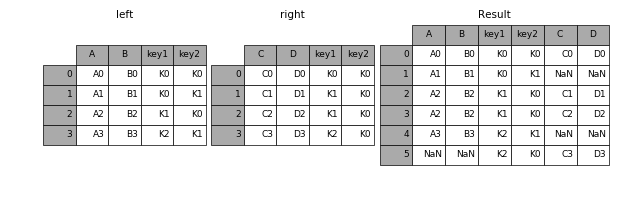
left
In [5]: result = pd.merge(left, right, how='left', on=['key1', 'key2'])
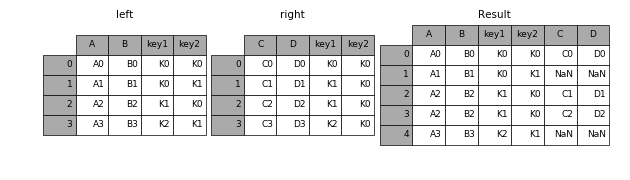
right
In [6]: result = pd.merge(left, right, how='right', on=['key1', 'key2'])
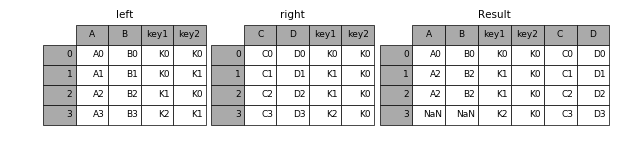
join
join是一种方便的方法,用于将合并两个具有不同索引的DataFrame
In [7]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
....:
'B': ['B0', 'B1', 'B2']},
....:
index=['K0', 'K1', 'K2'])
....:
In [8]: right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
....:
'D': ['D0', 'D2', 'D3']},
....:
index=['K0', 'K2', 'K3'])
....:
In [9]: result = left.join(right)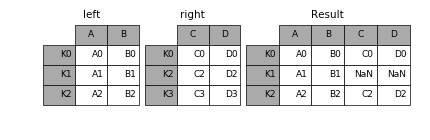
In [10]: result = left.join(right, how='outer')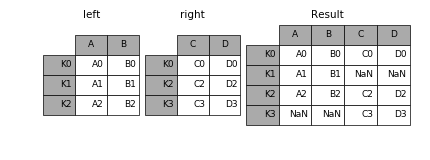
In [11]: result = left.join(right, how='inner')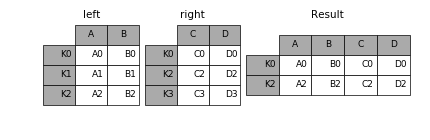
如果我们在merge里加上指示它使用的索引的参数,可以实现相同的操作。
In [12]: result = pd.merge(left, right, left_index=True, right_index=True, how='outer')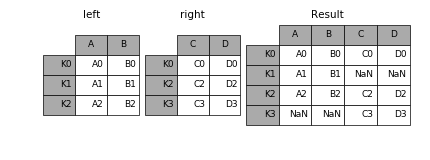
连接A的列和B的索引
join和merge都可以实现:
left.join(right, on=key_or_keys)
pd.merge(left, right, left_on=key_or_keys, right_index=True,
how='left', sort=False)In [13]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....:
'B': ['B0', 'B1', 'B2', 'B3'],
....:
'key': ['K0', 'K1', 'K0', 'K1']})
....:
In [14]: right = pd.DataFrame({'C': ['C0', 'C1'],
....:
'D': ['D0', 'D1']},
....:
index=['K0', 'K1'])
....:
In [15]: result = left.join(right, on='key')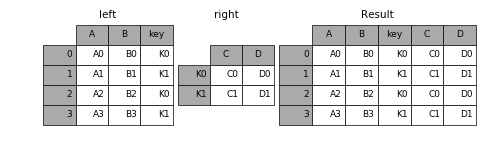
In [16]: result = pd.merge(left, right, left_on='key', right_index=True,
....:
how='left', sort=False);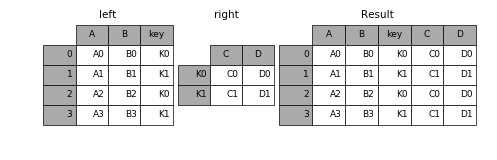
combine_first, update
修补值,combine_first值填充缺失值,update会覆盖原始值
In [17]: df1 = pd.DataFrame([[np.nan, 3., 5.], [-4.6, np.nan, np.nan],
....:
[np.nan, 7., np.nan]])
....:
In [18]: df2 = pd.DataFrame([[-42.6, np.nan, -8.2], [-5., 1.6, 4]],
....:
index=[1, 2])
....: In [18]: result = df1.combine_first(df2)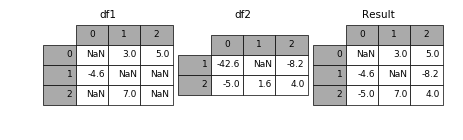
In [19]: df1.update(df2)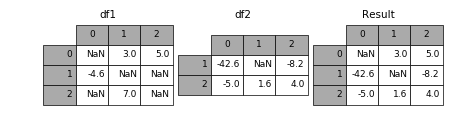
最后
以上就是妩媚黑米最近收集整理的关于pandas Merge,join,and concatenate的全部内容,更多相关pandas内容请搜索靠谱客的其他文章。








发表评论 取消回复