-
-
- 一、KNN分类模型 演示
-
- 1.1 kd树
- 1.2 三分类 KNN
-
- 二、KNN 回归模型 演示
- 三、KNN—数据归一化与参数优化_code
-
- 导入自带数据鸢尾花 —— 直接使用 KNN 方法训练
- GridSearchCV 参数优化 ——使用最佳参数训练
- 对数据标准化(归一化) 并预测
-
- 一、KNN分类模型 演示
-
一、KNN分类模型 演示
1.1 kd树
import sys
import importlib
importlib.reload(sys)
# kd-tree每个结点中主要包含的数据结构如下
class KdNode(object):
def __init__(self, dom_elt, split, left, right):
self.dom_elt = dom_elt # k维向量节点(k维空间中的一个样本点)
self.split = split # 整数(进行分割维度的序号)
self.left = left # 该结点分割超平面左子空间构成的kd-tree
self.right = right # 该结点分割超平面右子空间构成的kd-tree
class KdTree(object):
def __init__(self, data):
k = len(data[0]) # 数据维度
def CreateNode(split, data_set): # 按第split维划分数据集exset创建KdNode
if not data_set:
return None
# key参数的值为一个函数,此函数只有一个参数且返回一个值用来进行比较
# operator模块提供的itemgetter函数用于获取对象的哪些维的数据,参数为需要获取的数据在对象中的序号
# data_set.sort(key=itemgetter(split)) # 按要进行分割的那一维数据排序
data_set.sort(key=lambda x: x[split])
split_pos = len(data_set) // 2 # //为Python中的整数除法
median = data_set[split_pos] # 中位数分割点
split_next = (split + 1) % k # cycle coordinates
# 递归的创建kd树
return KdNode(median, split,
CreateNode(split_next, data_set[:split_pos]), # 创建左子树
CreateNode(split_next, data_set[split_pos + 1:])) # 创建右子树
self.root = CreateNode(0, data) # 从第0维分量开始构建kd树,返回根节点
# KDTree的前序遍历
def preorder(root):
print (root.dom_elt)
if root.left: # 节点不为空
preorder(root.left)
if root.right:
preorder(root.right)
if __name__ == "__main__":
data = [[2,3],[5,4],[9,6],[4,7],[8,1],[7,2]]
kd = KdTree(data)
preorder(kd.root)输出:
[7, 2]
[5, 4]
[2, 3]
[4, 7]
[9, 6]
[8, 1]1.2 三分类 KNN
"""
================================
Nearest Neighbors Classification
================================
Sample usage of Nearest Neighbors classification.
It will plot the decision boundaries for each class.
"""
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import neighbors, datasets
n_neighbors = 15 #设置K值:15个邻居
iris = datasets.load_iris()
# we only take the first two features. We could avoid this ugly
# slicing by using a two-dim dataset
X = iris.data[:, :2]
y = iris.target
h = .02 # step size in the mesh
# Create color maps 设置地图颜色
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
for weights in ['uniform', 'distance']:
# we create an instance of Neighbours Classifier and fit the data.
clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)
clf.fit(X, y)
# Plot the decision boundary. For that, we will assign a color to each
# point in the mesh [x_min, x_max]x[y_min, y_max].
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# Put the result into a color plot
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
# 绘制训练点
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold,
edgecolor='k', s=20)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("3-Class classification (k = %i, weights = '%s')"
% (n_neighbors, weights))
plt.show()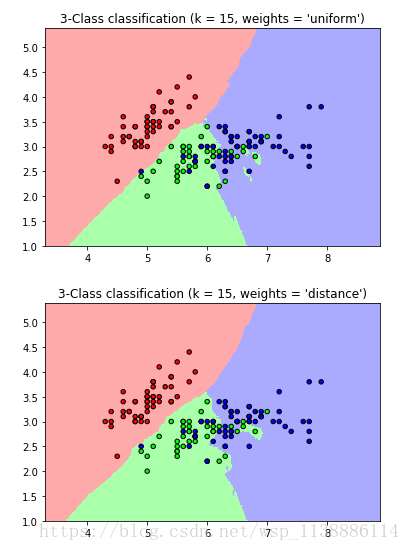
二、KNN 回归模型 演示
import numpy as np
import matplotlib.pyplot as plt
from sklearn import neighbors
np.random.seed(0)
X = np.sort(5 * np.random.rand(40, 1), axis=0)
T = np.linspace(0, 5, 500)[:, np.newaxis]
y = np.sin(X).ravel()
y[::5] += 1 * (0.5 - np.random.rand(8)) # 添加噪音
#回归模型 Fit regression model
n_neighbors = 5 # 设置5个邻居
plt.figure(figsize=((8,6)))
for i, weights in enumerate(['uniform','distance']):
knn = neighbors.KNeighborsRegressor(n_neighbors, weights=weights)
y_ = knn.fit(X, y).predict(T)
plt.subplot(2, 1, i+1)
plt.scatter(X, y, c='k', label='data')
plt.plot(T, y_, c='g', label='prediction')
plt.axis('tight')
plt.legend()
plt.title("KNeighborsRegressor(k=%i,weights='%s')"%(n_neighbors,weights))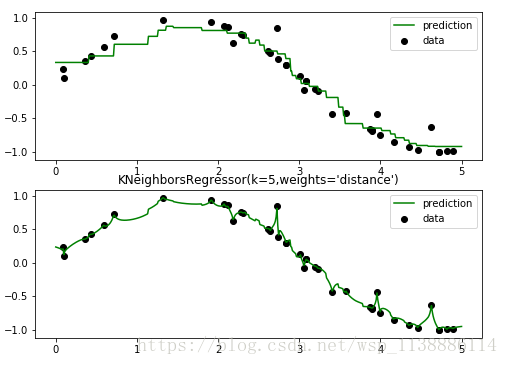
三、KNN—数据归一化与参数优化_code
jupyter notebook
from sklearn import preprocessing #数据标准化函数
from sklearn import model_selection #拆分数据集
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
from sklearn.metrics import confusion_matrix
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report #分类模型评估报告导入自带数据鸢尾花 —— 直接使用 KNN 方法训练
iris=load_iris() #导入自带数据鸢尾花
x=iris.data
y=iris.target
x[:10] #查看数据
y[:10]
#数据集拆分
X_train,X_test,y_train,y_test = model_selection
.train_test_split(x,y,test_size=0.3,random_state=123456) #直接使用 KNN 分类方法 (稍微调整参数)
knn=KNeighborsClassifier(n_neighbors=10,
metric='minkowski',
p=1,weights='distance')
knn.fit(X_train,y_train)
pred=knn.predict(X_test) #预测概率
print (classification_report(y_test,pred)) GridSearchCV 参数优化 ——使用最佳参数训练
# 使用 GridSearchCV 进行参数优化
parameters={
'n_neighbors':[5,10,15,20,30],
'weights':['uniform','distance'],
'p':[1,2]
}
knn=KNeighborsClassifier()
grid_search=GridSearchCV(knn,parameters,scoring='accuracy',cv=5)
grid_search.fit(x,y)
grid_search.best_estimator_ #查看函数(最优评估)
grid_search.best_score_ #正确率
grid_search.best_params_ #最佳组合(参数)
# 使用最优参数训练
knn=KNeighborsClassifier(n_neighbors=10,
metric='minkowski',
p=2,weights='distance')
knn.fit(X_train,y_train)
pred=knn.predict(X_test)
print (classification_report(y_test,pred))对数据标准化(归一化) 并预测
iris=load_iris()
x=iris.data
y=iris.target
#标准化——(0-1标准化)
scaler1=preprocessing.StandardScaler()
scaler1.fit(x)
scaler1_x=scaler1.transform(x)
scaler1_x[:10]
#标准化——(区间缩放法)
scaler2=preprocessing.MinMaxScaler()
scaler2.fit(x)
scaler2_x=scaler2.transform(x)
scaler2_x[:10]
x[:10] #查看原始值 与标准化后的数据对比
knn=KNeighborsClassifier(n_neighbors=10,metric='minkowski',
p=2,weights='distance')
knn.fit(scaler1_x,y) #使用0-1标准化的数据
pred=knn.predict(scaler1_x)
print (classification_report(y,pred))
knn.fit(scaler2_x,y) #使用区间缩放法的数据
pred=knn.predict(scaler2_x)
print (classification_report(y,pred))最后
以上就是时尚棒球最近收集整理的关于KNN_neighbors 分类回归Kd树—代码演示的全部内容,更多相关KNN_neighbors内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。

![[数据挖掘之scikit-learn] sklean.svm 分类器实例详解](https://www.shuijiaxian.com/files_image/reation/bcimg1.png)






发表评论 取消回复