本博客是学习《Web安全之机器学习入门》的笔记。
支持向量机算法可以在这里看:https://blog.csdn.net/qq_37865996/article/details/84555680
这个算法在这里的应用,自然是想找到一个超平面,划分普通用户和黑客,距离超平面最近的用户样本成为支持向量。在支持向量机中,很多时候都是不可线形区分的情况,虽然增加维数可以解决这一问题,但是由此造成的“维数灾难”是很多人极其不想遇到的。而使用核函数可以有效避免这一问题,有关核函数可以查看:https://blog.csdn.net/kateyabc/article/details/79980880
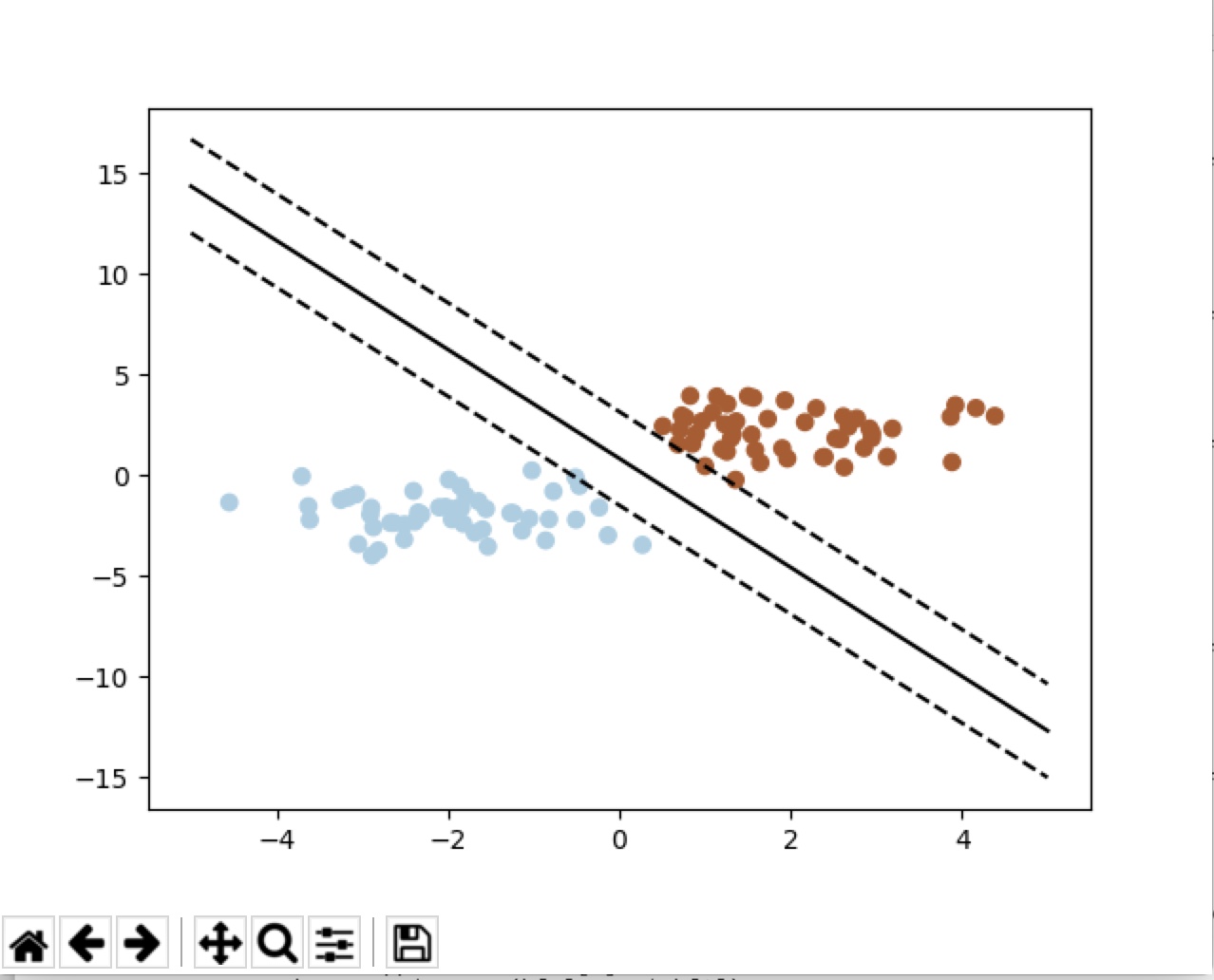
比如通过下列代码
print(__doc__)
import numpy as np
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from sklearn import svm
# 创建40个随机点,np.r_是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等,类似于pandas中的concat()。
np.random.seed(0)
X = np.r_[np.random.randn(20, 2) - [2, 2], np.random.randn(20, 2) + [2, 2]]
Y = [0] * 20 + [1] * 20
# fit the model
clf = svm.SVC(kernel='linear')
clf.fit(X, Y)
# 构造超平面
w = clf.coef_[0]
a = -w[0] / w[1]
xx = np.linspace(-5, 5)#均分指令
yy = a * xx - (clf.intercept_[0]) / w[1]
# plot the parallels to the separating hyperplane that pass through the
# support vectors
b = clf.support_vectors_[0]
yy_down = a * xx + (b[1] - a * b[0])
b = clf.support_vectors_[-1]
yy_up = a * xx + (b[1] - a * b[0])
# 调用matplotlib进行画图
plt.plot(xx, yy, 'k-')
plt.plot(xx, yy_down, 'k--')
plt.plot(xx, yy_up, 'k--')
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1],
s=80, facecolors='none')
plt.scatter(X[:, 0], X[:, 1], c=Y, cmap=plt.cm.Paired)
plt.axis('tight')
plt.show()结果:
1.识别XSS
关于识别XSS,我们可以从网络日志入手。
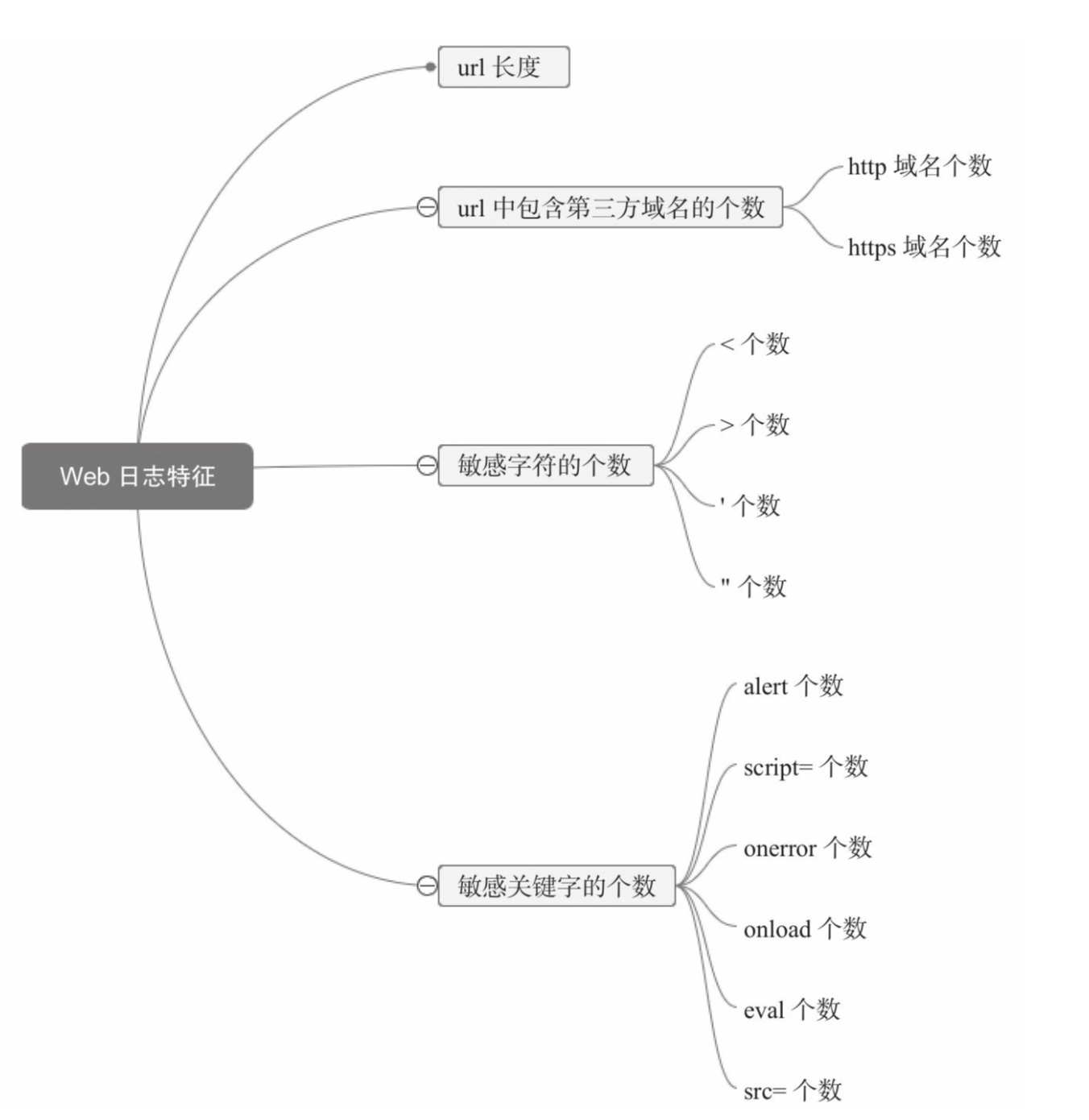
在特征化步骤中,经过宝书作者的处理,网络日志特征最后落到了url长度、url中包含第三方域名的个数、敏感字符的个数和敏感关键字的个数。
import re
import numpy as np
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn import svm
from sklearn.externals import joblib
from sklearn.metrics import classification_report
from sklearn import metrics
x = []
y = []
#提取url中第三方域名的个数、敏感字符的个数、敏感关键字的个数
def get_len(url):
return len(url)
def get_url_count(url):
if re.search('(http://)|(https://)', url, re.IGNORECASE) :
return 1
else:
return 0
def get_evil_char(url):
return len(re.findall("[<>,'"/]", url, re.IGNORECASE))
def get_evil_word(url):
return len(re.findall("(alert)|(script=)(%3c)|(%3e)|(%20)|(onerror)|(onload)|(eval)|(src=)|(prompt)",url,re.IGNORECASE))
def get_last_char(url):
if re.search('/$', url, re.IGNORECASE) :
return 1
else:
return 0
def get_feature(url):
return [get_len(url),get_url_count(url),get_evil_char(url),get_evil_word(url),get_last_char(url)]
def do_metrics(y_test,y_pred):
print "metrics.accuracy_score:"
print metrics.accuracy_score(y_test, y_pred)
print "metrics.confusion_matrix:"
print metrics.confusion_matrix(y_test, y_pred)
print "metrics.precision_score:"
print metrics.precision_score(y_test, y_pred)
print "metrics.recall_score:"
print metrics.recall_score(y_test, y_pred)
print "metrics.f1_score:"
print metrics.f1_score(y_test,y_pred)
def etl(filename,data,isxss):
with open(filename) as f:
for line in f:
f1=get_len(line)
f2=get_url_count(line)
f3=get_evil_char(line)
f4=get_evil_word(line)
data.append([f1,f2,f3,f4])
if isxss:
y.append(1)
else:
y.append(0)
return data
etl('/Users/zhanglipeng/Data/xss-200000.txt',x,1)
etl('/Users/zhanglipeng/Data/good-xss-200000.txt',x,0)
#数据拆分,40%作为测试样本,剩余的作为训练样本,可自己设置
x_train, x_test, y_train, y_test = train_test_split(x,y, test_size=0.4, random_state=0)
#数据训练,此处使用核函数为linear
clf = svm.SVC(kernel='linear', C=1).fit(x_train, y_train)
y_pred = clf.predict(x_test)
do_metrics(y_test, y_pred)输出结果:
metrics.accuracy_score:
0.9979394698668074
metrics.confusion_matrix:
[[54092 73]
[ 52 6447]]
metrics.precision_score:
0.9888036809815951
metrics.recall_score:
0.991998769041391
metrics.f1_score:
0.9903986481296566
可以看到无论是精确率还是召回率,支持向量机算法在这里的应用都显得很出色。
2.使用支持向量机算法区分僵尸网络DGA家族
根据书中作者在这里搜集的url,包含有cryptolocker、post-tovar-goz和alexa三个家族的域名。这里作者提出了四种方法来进行各自的统计和对比,见下图:
# -*- coding:utf-8 -*-
import sys
import urllib
import urlparse
import re
from hmmlearn import hmm
import numpy as np
from sklearn.externals import joblib
import HTMLParser
import nltk
import csv
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import os
#处理域名的最小长度
MIN_LEN=10
#状态个数
N=8
#最大似然概率阈值
T=-50
#模型文件名
FILE_MODEL="9-2.m"
def load_alexa(filename):
domain_list=[]
csv_reader = csv.reader(open(filename))
for row in csv_reader:
domain=row[1]
if len(domain) >= MIN_LEN:
domain_list.append(domain)
return domain_list
def domain2ver(domain):
ver=[]
for i in range(0,len(domain)):
ver.append([ord(domain[i])])
return ver
def train_hmm(domain_list):
X = [[0]]
X_lens = [1]
for domain in domain_list:
ver=domain2ver(domain)
np_ver = np.array(ver)
X=np.concatenate([X,np_ver])
X_lens.append(len(np_ver))
remodel = hmm.GaussianHMM(n_components=N, covariance_type="full", n_iter=100)
remodel.fit(X,X_lens)
joblib.dump(remodel, FILE_MODEL)
return remodel
#从DGA文件中提取域名数据
def load_dga(filename):
domain_list=[]
#xsxqeadsbgvpdke.co.uk,Domain used by Cryptolocker - Flashback DGA for 13 Apr 2017,2017-04-13,
# http://osint.bambenekconsulting.com/manual/cl.txt
with open(filename) as f:
for line in f:
domain=line.split(",")[0]
if len(domain) >= MIN_LEN:
domain_list.append(domain)
return domain_list
def test_dga(remodel,filename):
x=[]
y=[]
dga_cryptolocke_list = load_dga(filename)
for domain in dga_cryptolocke_list:
domain_ver=domain2ver(domain)
np_ver = np.array(domain_ver)
pro = remodel.score(np_ver)
#print "SCORE:(%d) DOMAIN:(%s) " % (pro, domain)
x.append(len(domain))
y.append(pro)
return x,y
def test_alexa(remodel,filename):
x=[]
y=[]
alexa_list = load_alexa(filename)
for domain in alexa_list:
domain_ver=domain2ver(domain)
np_ver = np.array(domain_ver)
pro = remodel.score(np_ver)
#print "SCORE:(%d) DOMAIN:(%s) " % (pro, domain)
x.append(len(domain))
y.append(pro)
return x, y
def show_hmm():
domain_list = load_alexa("/Users/zhanglipeng/Data/top-1000.csv")
if not os.path.exists(FILE_MODEL):
remodel=train_hmm(domain_list)
remodel=joblib.load(FILE_MODEL)
x_3,y_3=test_dga(remodel, "/Users/zhanglipeng/Data/dga-post-tovar-goz-1000.txt")
x_2,y_2=test_dga(remodel,"/Users/zhanglipeng/Data/dga-cryptolocke-1000.txt")
x_1,y_1=test_alexa(remodel, "/Users/zhanglipeng/Data/test-top-1000.csv")
fig,ax=plt.subplots()
ax.set_xlabel('Domain Length')
ax.set_ylabel('HMM Score')
ax.scatter(x_3,y_3,color='b',label="dga_post-tovar-goz",marker='o')
ax.scatter(x_2, y_2, color='g', label="dga_cryptolock",marker='v')
ax.scatter(x_1, y_1, color='r', label="alexa",marker='*')
ax.legend(loc='best')
plt.show()
#针对正常域名元音字母比例较高,可以计算元音字母的比例,以进行区分
def get_aeiou(domain_list):
x=[]
y=[]
for domain in domain_list:
x.append(len(domain))
count=len(re.findall(r'[aeiou]',domain.lower()))
count=(0.0+count)/len(domain)
y.append(count)
return x,y
#三个家族的字母比例自然不会相同,这里进行获取和计算
def show_aeiou():
x1_domain_list = load_alexa("/Users/zhanglipeng/Data/top-1000.csv")
x_1,y_1=get_aeiou(x1_domain_list)
x2_domain_list = load_dga("/Users/zhanglipeng/Data/dga-cryptolocke-1000.txt")
x_2,y_2=get_aeiou(x2_domain_list)
x3_domain_list = load_dga("/Users/zhanglipeng/Data/dga-post-tovar-goz-1000.txt")
x_3,y_3=get_aeiou(x3_domain_list)
#以域名长度为横轴,元音字母比例作为纵轴
fig,ax=plt.subplots()
ax.set_xlabel('Domain Length')
ax.set_ylabel('AEIOU Score')
ax.scatter(x_3,y_3,color='b',label="dga_post-tovar-goz",marker='o')
ax.scatter(x_2, y_2, color='g', label="dga_cryptolock",marker='v')
ax.scatter(x_1, y_1, color='r', label="alexa",marker='*')
ax.legend(loc='best')
plt.show()
#计算去重后的字母数字个数与域名长度的比例,可以使用set数据结构。set数据结构不包含重复的值
def get_uniq_char_num(domain_list):
x=[]
y=[]
for domain in domain_list:
x.append(len(domain))
count=len(set(domain))
count=(0.0+count)/len(domain)
y.append(count)
return x,y
#分别获取僵尸网络和alexa域名数据,计算去重后的字母个数与域名长度的比例
def show_uniq_char_num():
x1_domain_list = load_alexa("/Users/zhanglipeng/Data/top-1000.csv")
x_1,y_1=get_uniq_char_num(x1_domain_list)
x2_domain_list = load_dga("/Users/zhanglipeng/Data/dga-cryptolocke-1000.txt")
x_2,y_2=get_uniq_char_num(x2_domain_list)
x3_domain_list = load_dga("/Users/zhanglipeng/Data/dga-post-tovar-goz-1000.txt")
x_3,y_3=get_uniq_char_num(x3_domain_list)
fig,ax=plt.subplots()
ax.set_xlabel('Domain Length')
ax.set_ylabel('UNIQ CHAR NUMBER')
ax.scatter(x_3,y_3,color='b',label="dga_post-tovar-goz",marker='o')
ax.scatter(x_2, y_2, color='g', label="dga_cryptolock",marker='v')
ax.scatter(x_1, y_1, color='r', label="alexa",marker='*')
ax.legend(loc='best')
plt.show()
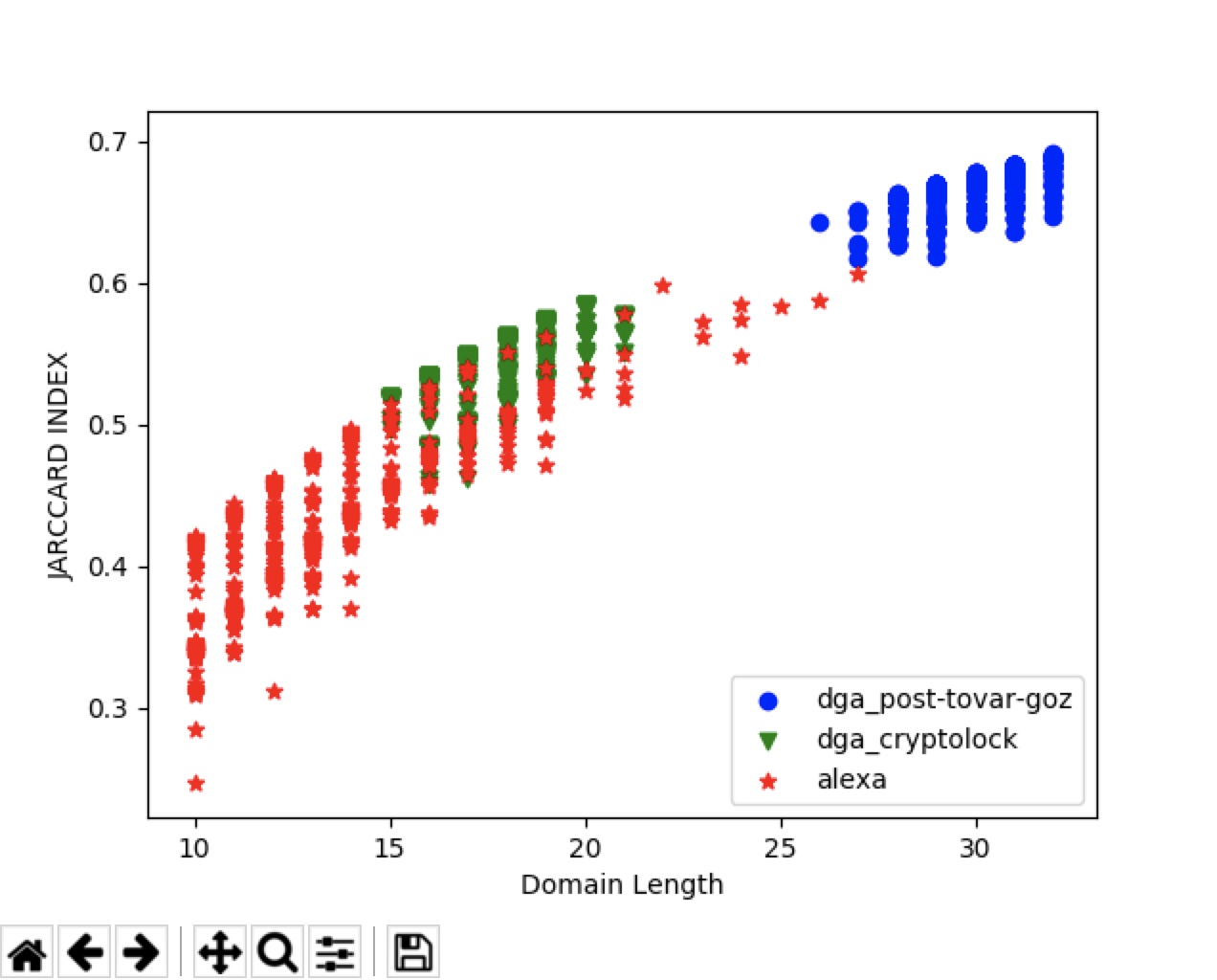
#jarccard系数定义为两个集合交集与并集元素个数的比值。
def count2string_jarccard_index(a,b):
x=set(' '+a[0])
y=set(' '+b[0])
for i in range(0,len(a)-1):
x.add(a[i]+a[i+1])
x.add(a[len(a)-1]+' ')
for i in range(0,len(b)-1):
y.add(b[i]+b[i+1])
y.add(b[len(b)-1]+' ')
return (0.0+len(x-y))/len(x|y)
#计算两个域名集合的平均jarccard
def get_jarccard_index(a_list,b_list):
x=[]
y=[]
for a in a_list:
j=0.0
for b in b_list:
j+=count2string_jarccard_index(a,b)
x.append(len(a))
y.append(j/len(b_list))
return x,y
#分别计算三个
def show_jarccard_index():
x1_domain_list = load_alexa("/Users/zhanglipeng/Data/top-1000.csv")
x_1,y_1=get_jarccard_index(x1_domain_list,x1_domain_list)
x2_domain_list = load_dga("/Users/zhanglipeng/Data/dga-cryptolocke-1000.txt")
x_2,y_2=get_jarccard_index(x2_domain_list,x1_domain_list)
x3_domain_list = load_dga("/Users/zhanglipeng/Data/dga-post-tovar-goz-1000.txt")
x_3,y_3=get_jarccard_index(x3_domain_list,x1_domain_list)
fig,ax=plt.subplots()
ax.set_xlabel('Domain Length')
ax.set_ylabel('JARCCARD INDEX')
ax.scatter(x_3,y_3,color='b',label="dga_post-tovar-goz",marker='o')
ax.scatter(x_2, y_2, color='g', label="dga_cryptolock",marker='v')
ax.scatter(x_1, y_1, color='r', label="alexa",marker='*')
ax.legend(loc='lower right')
plt.show()
if __name__ == '__main__':
#show_hmm()
#show_aeiou()
#show_uniq_char_num()
show_jarccard_index()其中一个:
学至此处,愈发觉得此书的价值无比。
最后
以上就是自觉电灯胆最近收集整理的关于使用支持向量机算法区分黑白的全部内容,更多相关使用支持向量机算法区分黑白内容请搜索靠谱客的其他文章。








发表评论 取消回复