我是靠谱客的博主 感动饼干,这篇文章主要介绍介绍一下K近邻(KNN)算法,KNeighbors和RadiusNeighbors的差异是什么?各有什么优势?介绍一下K近邻(KNN)算法,KNeighbors和RadiusNeighbors的差异是什么?各有什么优势?,现在分享给大家,希望可以做个参考。
介绍一下K近邻(KNN)算法,KNeighbors和RadiusNeighbors的差异是什么?各有什么优势?
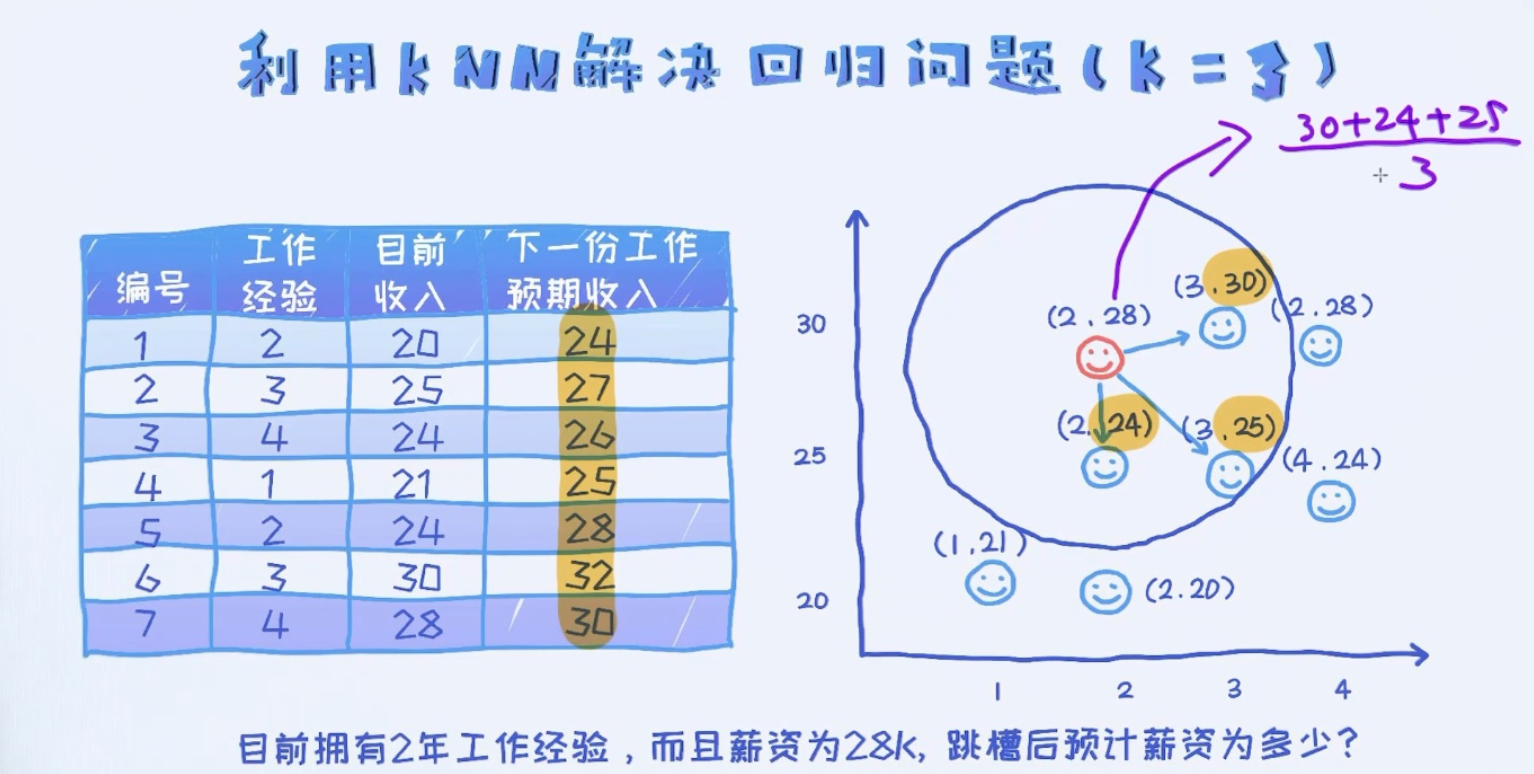
K近邻(KNN)算法
近邻(Nearest Neighbor)算法既可以用于监督学习(分类),也可以用于非监督学习(聚类),它通过按照一定方法查找距离预测样本最近的n个样本,并根据这些样本的特征对预测样本做出预测。
KNN算法又被称为K近邻算法(k-nearest neighbor classification)算法,可以用于分类和回归任务(也适用于多输出的分类和回归预测和回归)。
KNN算法被称为基于实例的算法模型;
该模型的预测过程对于新的数据则直接和训练数据匹配,如果存在相同属性的训练数据,则直接用它的分类来作为新数据的分类。这种方式有一个明显的缺点,那就是很可能无法找到完全匹配的训练样本,或者实际找到的样本根本距离很远但是相对最近了还是这K个。
KNN算法是从训练集中找到和新数据最接近的K条记录,然后根据他们的主要分类来决定新数据的类别。
KNN算法涉及3个主要因素:训练集、距离或相似的衡量、K的大小。
KNN模型属
最后
以上就是感动饼干最近收集整理的关于介绍一下K近邻(KNN)算法,KNeighbors和RadiusNeighbors的差异是什么?各有什么优势?介绍一下K近邻(KNN)算法,KNeighbors和RadiusNeighbors的差异是什么?各有什么优势?的全部内容,更多相关介绍一下K近邻(KNN)算法,KNeighbors和RadiusNeighbors内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复