一、 KNN最邻近算法
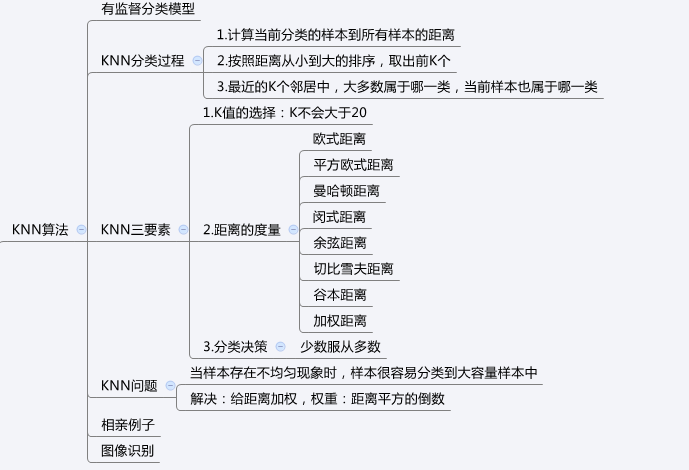
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一,有监督算法。该方法的思路是:如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法由你的邻居来推断出你的类别,KNN算法就是用距离来衡量样本之间的相似度。
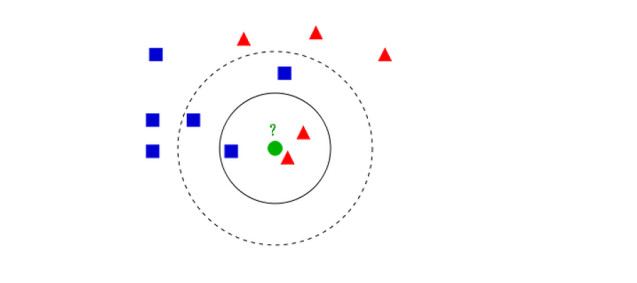
- 如果K = 3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
- 如果K = 5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
K 值的选择,距离度量和分类决策规则是该算法的三个基本要素。K值的选择一般低于样本数据的平方根,一般是不大于20的整数。距离度量常用的有欧式距离,曼哈顿距离,余弦距离等,一般使用欧氏距离,对于文本分类,常用余弦距离。分类决策就是“少数服从多数”的策略。
1.1、KNN算法步骤:
- 对于未知类别的数据(对象,点),计算已知类别数据集中的点到该点的距离。
- 按照距离由小到大排序
- 选取与当前点距离最小的K个点
- 确定前K个点所在类别出现的概率
- 返回当前K个点出现频率最高的类别作为当前点预测分类
KNN算法复杂度:
KNN 分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为 n,那么 KNN 的分类时间复杂度为O(n)
KNN问题:
该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的 K 个邻居中大容量类的样本占多数。解决:可以采用权值的方法,根据和该样本距离的远近,对近邻进行加权,距离越小的邻居权值大,权重一般为距离平方的倒数。
KNN数据归一化:
为了防止某一维度的数据的数值大小对距离计算产生影响,保证多个维度的特征是等权重的,最终结果不能被数值的大小影响,应该将各个维度进行数据的归一化,把数据归一化到[0,1]区间上。
归一化公式: 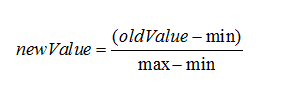
二、 KNN最邻近算法案例(1)
# coding:utf-8
import numpy as np
# normData 测试数据集的某行, dataSet 训练数据集 ,labels 训练数据集的类别,k k的值
def classify(normData, dataSet, labels, k):
# 计算行数
dataSetSize = dataSet.shape[0]
# print ('dataSetSize 长度 =%d'%dataSetSize)
# 当前点到所有点的坐标差值 ,np.tile(x,(y,1)) 复制x 共y行 1列
diffMat = np.tile(normData, (dataSetSize, 1)) - dataSet
# 对每个坐标差值平方
sqDiffMat = diffMat ** 2
# 对于二维数组 sqDiffMat.sum(axis=0)指 对向量每列求和,sqDiffMat.sum(axis=1)是对向量每行求和,返回一个长度为行数的数组
# 例如:narr = array([[ 1., 4., 6.],
# [ 2., 5., 3.]])
# narr.sum(axis=1) = array([ 11., 10.])
# narr.sum(axis=0) = array([ 3., 9., 9.])
sqDistances = sqDiffMat.sum(axis=1)
# 欧式距离 最后开方
distance = sqDistances ** 0.5
# x.argsort() 将x中的元素从小到大排序,提取其对应的index 索引,返回数组
# 例: tsum = array([ 11., 10.]) ---- tsum.argsort() = array([1, 0])
sortedDistIndicies = distance.argsort()
# classCount保存的K是魅力类型 V:在K个近邻中某一个类型的次数
classCount = {}
for i in range(k):
# 获取对应的下标的类别
voteLabel = labels[sortedDistIndicies[i]]
# 给相同的类别次数计数
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
# sorted 排序 返回新的list
# sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
sortedClassCount = sorted(classCount.items(), key=lambda x: x[1], reverse=True)
return sortedClassCount[0][0]
def file2matrix(filename):
fr = open(filename, "rb")
# readlines:是一次性将这个文本的内容全部加载到内存中(列表)
arrayOflines = fr.readlines()
numOfLines = len(arrayOflines)
# print "numOfLines = " , numOfLines
# numpy.zeros 创建给定类型的数组 numOfLines 行 ,3列
returnMat = np.zeros((numOfLines, 3))
# 存结果的列表
classLabelVector = []
index = 0
for line in arrayOflines:
# 去掉一行的头尾空格
line = line.decode("utf-8").strip()
listFromline = line.split('t')
returnMat[index, :] = listFromline[0:3]
classLabelVector.append(int(listFromline[-1]))
index += 1
return returnMat, classLabelVector
# 将数据归一化
def autoNorm(dataSet):
# dataSet.min(0) 代表的是统计这个矩阵中每一列的最小值 返回值是一个矩阵1*3矩阵
# 例如: numpyarray = array([[1,4,6],
# [2,5,3]])
# numpyarray.min(0) = array([1,4,3]) numpyarray.min(1) = array([1,2])
# numpyarray.max(0) = array([2,5,6]) numpyarray.max(1) = array([6,5])
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
# dataSet.shape[0] 计算行数, shape[1] 计算列数
m = dataSet.shape[0]
# print '行数 = %d' %(m)
# print maxVals
# normDataSet存储归一化后的数据
# normDataSet = np.zeros(np.shape(dataSet))
# np.tile(minVals,(m,1)) 在行的方向上重复 minVals m次 即复制m行,在列的方向上重复munVals 1次,即复制1列
normDataSet = dataSet - np.tile(minVals, (m, 1))
normDataSet = normDataSet / np.tile(ranges, (m, 1))
return normDataSet, ranges, minVals
def datingClassTest():
rate = 0.1
datingDataMat, datingLabels = file2matrix('./datingTestSet.txt')
# 将数据归一化
normMat, ranges, minVals = autoNorm(datingDataMat)
# m 是 : normMat行数 = 1000
m = normMat.shape[0]
# print 'm =%d 行'%m
# 取出100行数据测试
numTestVecs = int(m * rate)
errorCount = 0.0
for i in range(numTestVecs):
# normMat[i,:] 取出数据的第i行,normMat[numTestVecs:m,:]取出数据中的100行到1000行 作为训练集,
# datingLabels[numTestVecs:m] 取出数据中100行到1000行的类别,4是K
classifierResult = classify(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 4)
print('模型预测值: %d ,真实值 : %d' % (classifierResult, datingLabels[i]))
if (classifierResult != datingLabels[i]):
errorCount += 1.0
errorRate = errorCount / float(numTestVecs)
print('正确率 : %f' % (1 - errorRate))
return 1 - errorRate
def classifyperson():
resultList = ['没感觉', '看起来还行', '极具魅力']
input_man = [18983, 10.448091,0.267652]
datingDataMat, datingLabels = file2matrix('datingTestSet.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
result = classify((input_man - minVals) / ranges, normMat, datingLabels, 3)
print('你即将约会的人是:%s' % resultList[result - 1])
if __name__ == '__main__':
acc = datingClassTest()
if (acc > 0.9):
classifyperson()
测试结果:
C:ProgramDataAnaconda3python.exe F:/Python/001code/machinelearning/www/lxk/com/KNNDateOnHand.py
模型预测值: 3 ,真实值 : 3
模型预测值: 2 ,真实值 : 2
模型预测值: 1 ,真实值 : 1
模型预测值: 1 ,真实值 : 1
模型预测值: 1 ,真实值 : 1
...
模型预测值: 1 ,真实值 : 1
模型预测值: 2 ,真实值 : 2
模型预测值: 1 ,真实值 : 1
模型预测值: 3 ,真实值 : 3
模型预测值: 3 ,真实值 : 3
模型预测值: 2 ,真实值 : 2
模型预测值: 2 ,真实值 : 1
模型预测值: 1 ,真实值 : 1
正确率 : 0.960000
你即将约会的人是:极具魅力
Process finished with exit code 0三、 KNN最邻近算法案例(2)
# coding:utf-8
import operator
from sklearn.neighbors import NearestNeighbors
from com.bjsxt.knn.KNNDateOnHand import file2matrix, autoNorm
if __name__ == '__main__':
datingDataMat, datingLabels = file2matrix('datingTestSet.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
# n_neighbors=3 表示查找的近邻数,默认是5
# fit:用normMat作为训练集拟合模型 n_neighbors:几个最近邻
# NearestNeighbors 默认使用的就是欧式距离测度
nbrs = NearestNeighbors(n_neighbors=3).fit(normMat)
# input_man = [20000, 8, 2]
input_man = [61364, 7.516754, 1.269164]
# 数据归一化
S = (input_man - minVals) / ranges
# 找到当前点的K个临近点,也就是找到临近的3个点
# indices 返回的距离数据集中最近点的坐标的下标。 distance 返回的是距离数据集中最近点的距离
distances, indices = nbrs.kneighbors([S])
print("distances is %s" % distances)
print("indices is %s" % indices)
# classCount K:类别名 V:这个类别中的样本出现的次数
classCount = {}
for i in range(3):
# 找出对应的索引的类别号
voteLabel = datingLabels[indices[0][i]]
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
resultList = ['没感觉', '看起来还行', '极具魅力']
print(resultList[sortedClassCount[0][0] - 1])测试结果:
C:ProgramDataAnaconda3python.exe I:/11_python/Pythonscikit-learn/com/bjsxt/knn/KNNDateByScikit-learn.py
distances is [[0. 0.02772355 0.08121282]]
indices is [[ 16 412 420]]
没感觉
Process finished with exit code 0
最后
以上就是洁净书包最近收集整理的关于机器学习之KNN最邻近分类算法的全部内容,更多相关机器学习之KNN最邻近分类算法内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复