数据库构架设计中主要有Shared Everthting、Shared Nothing、和Shared Disk:
-
Shared Everthting:一般是针对单个主机,完全透明共享CPU/MEMORY/IO,并行处理能力是最差的,典型的代表SQLServer
-
Shared Disk:各个处理单元使用自己的私有 CPU和Memory,共享磁盘系统。典型的代表Oracle Rac, 它是数据共享,可通过增加节点来提高并行处理的能力,扩展能力较好。其类似于SMP(对称多处理)模式,但是当存储器接口达到饱和的时候,增加节点并不能获得更高的性能 。
-
Shared Nothing:各个处理单元都有自己私有的CPU/内存/硬盘等,不存在共享资源,类似于MPP(大规模并行处理)模式,各处理单元之间通过协议通信,并行处理和扩展能力更好。典型代表DB2 DPF和hadoop ,各节点相互独立,各自处理自己的数据,处理后的结果可能向上层汇总或在节点间流转。
我们常说的 Sharding 其实就是Share Nothing架构,它是把某个表从物理存储上被水平分割,并分配给多台服务器(或多个实例),每台服务器可以独立工作,具备共同的schema,比如MySQL Proxy和Google的各种架构,只需增加服务器数就可以增加处理能力和容量。
MPP概念
MPP即大规模并行处理(Massively Parallel Processor )。 在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据 库服务。非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。
大规模并行处理(MPP)架构
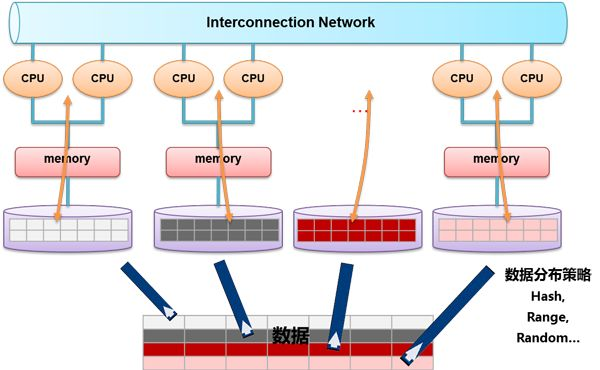
例子
Greenplum是一种基于PostgreSQL的分布式数据库。其采用shared nothing架构(MPP),主机,操作系统,内存,存储都是自我控制的,不存在共享。也就是每个节点都是一个单独的数据库。节点之间的信息交互是通过节点互联网络实现。通过将数据分布到多个节点上来实现规模数据的存储,通过并行查询处理来提高查询性能。
这个就像是把小数据库组织起来,联合成一个大型数据库。将数据分片,存储在每个节点上。每个节点仅查询自己的数据。所得到的结果再经过主节点处理得到最终结果。通过增加节点数目达到系统线性扩展。
elasticsearch也是一种MPP架构的数据库,Presto、Impala等都是MPP engine,各节点不共享资源,每个executor可以独自完成数据的读取和计算,缺点在于怕stragglers,遇到后整个engine的性能下降到该straggler的能力,所谓木桶的短板,这也是为什么MPP架构不适合异构的机器,要求各节点配置一样。
Spark SQL应该还是算做Batching Processing, 中间计算结果需要落地到磁盘,所以查询效率没有MPP架构的引擎(如Impala)高。
最后
以上就是淡定小甜瓜最近收集整理的关于MPP架构的全部内容,更多相关MPP架构内容请搜索靠谱客的其他文章。

![[面试] MPP数据库 MPP数据库定义为什么选择MPP](https://www.shuijiaxian.com/files_image/reation/bcimg2.png)






发表评论 取消回复