
Sentinel 是什么?
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
什么是流量控制
流量控制在网络传输中是一个常用的概念,它用于调整网络包的发送数据。然而,从系统稳定性角度考虑,在处理请求的速度上,也有非常多的讲究。任意时间到来的请求往往是随机不可控的,而系统的处理能力是有限的。需要根据系统的处理能力对流量进行控制。Sentinel 作为一个调配器,可以根据需要把随机的请求调整成合适的形状,如下图所示:
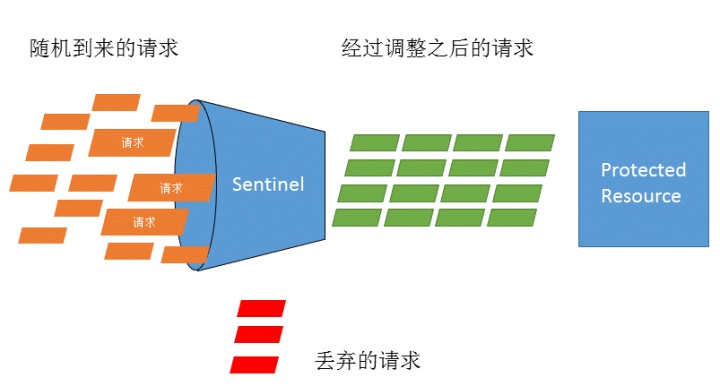
流量控制设计理念
流量控制有以下几个角度: 资源的调用关系,例如资源的调用链路,资源和资源之间的关系; 运行指标,例如 QPS、线程池、系统负载等; 控制的效果,例如直接限流、冷启动、排队等。 Sentinel 的设计理念是让您自由选择控制的角度,并进行灵活组合,从而达到想要的效果。
什么是熔断降级
除了流量控制以外,降低调用链路中的不稳定资源也是 Sentinel 的使命之一。由于调用关系的复杂性,如果调用链路中的某个资源出现了不稳定,最终会导致请求发生堆积。这个问题和 Hystrix 里面描述的问题是一样的。 Sentinel 和 Hystrix 的原则是一致的: 当调用链路中某个资源出现不稳定,例如,表现为 timeout,异常比例升高的时候,则对这个资源的调用进行限制,并让请求快速失败,避免影响到其它的资源,最终产生雪崩的效果。
熔断降级设计理念
在限制的手段上,Sentinel 和 Hystrix 采取了完全不一样的方法。 Hystrix 通过线程池的方式,来对依赖(对应资源)进行了隔离。这样做的好处是资源和资源之间做到了最彻底的隔离。缺点是除了增加了线程切换的成本,还需要预先给各个资源做线程池大小的分配。 Sentinel 对这个问题采取了两种手段: 通过并发线程数进行限制 和资源池隔离的方法不同,Sentinel 通过限制资源并发线程的数量,来减少不稳定资源对其它资源的影响。这样不但没有线程切换的损耗,也不需要您预先分配线程池的大小。当某个资源出现不稳定的情况下,例如响应时间变长,对资源的直接影响就是会造成线程数的逐步堆积。当线程数在特定资源上堆积到一定的数量之后,对该资源的新请求就会被拒绝。堆积的线程完成任务后才开始继续接收请求。 通过响应时间对资源进行降级 除了对并发线程数进行控制以外,Sentinel 还可以通过响应时间来快速降级不稳定的资源。当依赖的资源出现响应时间过长后,所有对该资源的访问都会被直接拒绝,直到过了指定的时间窗口之后才重新恢复。 系统负载保护 Sentinel 同时对系统的维度提供保护。防止雪崩,是系统防护中重要的一环。当系统负载较高的时候,如果还持续让请求进入,可能会导致系统崩溃,无法响应。在集群环境下,网络负载均衡会把本应这台机器承载的流量转发到其它的机器上去。如果这个时候其它的机器也处在一个边缘状态的时候,这个增加的流量就会导致这台机器也崩溃,最后导致整个集群不可用。 针对这个情况,Sentinel 提供了对应的保护机制,让系统的入口流量和系统的负载达到一个平衡,保证系统在能力范围之内处理最多的请求。
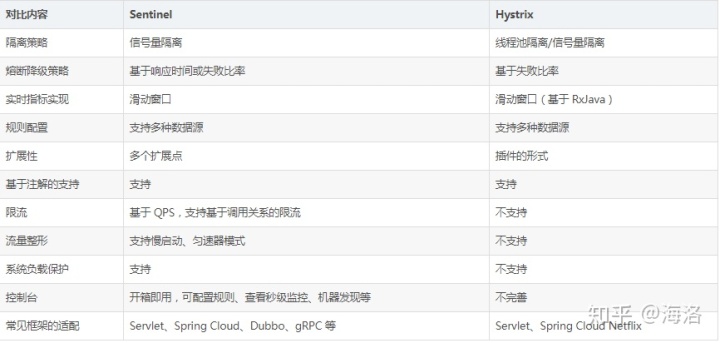
Sentinel 的主要特性:
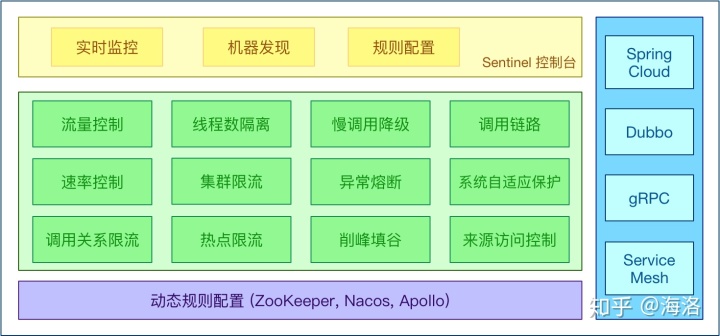
快速使用:
以SpringCloudAlibaba为例, -。-~~~
pom导入:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>bootstrap文件配置:
# 开启sentinel对feign的支持
feign:
sentinel:
enabled: true注解熔断方案(跟多方案可看底部官网):
@SentinelResource
@Override
@SentinelResource(value = "test", blockHandler = "handleException", blockHandlerClass = {ExceptionUtil.class})
public void test() {
System.out.println("Test");
}
public final class ExceptionUtil {
public static void handleException(BlockException ex) {
// Handler method that handles BlockException when blocked.
// The method parameter list should match original method, with the last additional
// parameter with type BlockException. The return type should be same as the original method.
// The block handler method should be located in the same class with original method by default.
// If you want to use method in other classes, you can set the blockHandlerClass
// with corresponding Class (Note the method in other classes must be static).
System.out.println("Oops: " + ex.getClass().getCanonicalName());
}
}Sentinel 控制台:
可以参考Sentinel 控制台文档启动控制台,可以实时监控各个资源的运行情况,并且可以实时地修改限流规则。
Sentinel 原理分析:
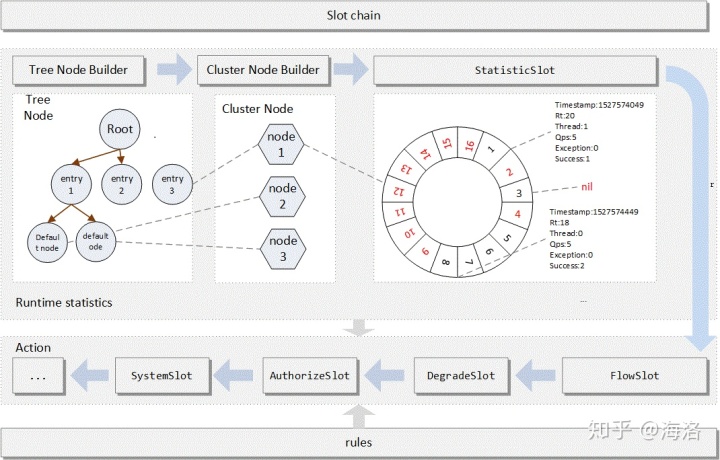
在 Sentinel 里面,所有的资源都对应一个资源名称(resourceName),每次资源调用都会创建一个 Entry 对象。Entry 可以通过对主流框架的适配自动创建,也可以通过注解的方式或调用 SphU API 显式创建。Entry 创建的时候,同时也会创建一系列功能插槽(slot chain),这些插槽有不同的职责,例如:
NodeSelectorSlot负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级;ClusterBuilderSlot则用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS, thread count 等等,这些信息将用作为多维度限流,降级的依据;StatisticSlot则用于记录、统计不同纬度的 runtime 指标监控信息;FlowSlot则用于根据预设的限流规则以及前面 slot 统计的状态,来进行流量控制;AuthoritySlot则根据配置的黑白名单和调用来源信息,来做黑白名单控制;DegradeSlot则通过统计信息以及预设的规则,来做熔断降级;SystemSlot则通过系统的状态,例如 load1 等,来控制总的入口流量;
NodeSelectorSlot
这个 slot 主要负责收集资源的路径,并将这些资源的调用路径以树状结构存储起来,用于根据调用路径进行流量控制。
ContextUtil.enter("entrance1", "appA");
Entry nodeA = SphU.entry("nodeA");
if (nodeA != null) {
nodeA.exit();
}
ContextUtil.exit();上述代码通过 ContextUtil.enter() 创建了一个名为 entrance1 的上下文,同时指定调用发起者为 appA;接着通过 SphU.entry()请求一个 token,如果该方法顺利执行没有抛 BlockException,表明 token 请求成功。
以上代码将在内存中生成以下结构:
machine-root
/
/
EntranceNode1
/
/
DefaultNode(nodeA)注意:每个 DefaultNode 由资源 ID 和输入名称来标识。换句话说,一个资源 ID 可以有多个不同入口的 DefaultNode。
ContextUtil.enter("entrance1", "appA");
Entry nodeA = SphU.entry("nodeA");
if (nodeA != null) {
nodeA.exit();
}
ContextUtil.exit();
ContextUtil.enter("entrance2", "appA");
nodeA = SphU.entry("nodeA");
if (nodeA != null) {
nodeA.exit();
}
ContextUtil.exit();以上代码将在内存中生成以下结构:
machine-root
/
/
EntranceNode1 EntranceNode2
/
/
DefaultNode(nodeA) DefaultNode(nodeA)上面的结构可以通过调用 curl http://localhost:8719/tree?type=root 来显示:
EntranceNode: machine-root(t:0 pq:1 bq:0 tq:1 rt:0 prq:1 1mp:0 1mb:0 1mt:0)
-EntranceNode1: Entrance1(t:0 pq:1 bq:0 tq:1 rt:0 prq:1 1mp:0 1mb:0 1mt:0)
--nodeA(t:0 pq:1 bq:0 tq:1 rt:0 prq:1 1mp:0 1mb:0 1mt:0)
-EntranceNode2: Entrance1(t:0 pq:1 bq:0 tq:1 rt:0 prq:1 1mp:0 1mb:0 1mt:0)
--nodeA(t:0 pq:1 bq:0 tq:1 rt:0 prq:1 1mp:0 1mb:0 1mt:0)
t:threadNum pq:passQps bq:blockedQps tq:totalQps rt:averageRt prq: passRequestQps 1mp:1m-passed 1mb:1m-blocked 1mt:1m-totalClusterBuilderSlot
此插槽用于构建资源的 ClusterNode 以及调用来源节点。ClusterNode 保持某个资源运行统计信息(响应时间、QPS、block 数目、线程数、异常数等)以及调用来源统计信息列表。调用来源的名称由 ContextUtil.enter(contextName,origin) 中的 origin 标记。可通过如下命令查看某个资源不同调用者的访问情况:curl http://localhost:8719/origin?id=caller:
id: nodeA
idx origin threadNum passedQps blockedQps totalQps aRt 1m-passed 1m-blocked 1m-total
1 caller1 0 0 0 0 0 0 0 0
2 caller2 0 0 0 0 0 0 0 0StatisticSlot
StatisticSlot 是 Sentinel 的核心功能插槽之一,用于统计实时的调用数据。
clusterNode:资源唯一标识的 ClusterNode 的实时统计origin:根据来自不同调用者的统计信息defaultnode: 根据入口上下文区分的资源 ID 的 runtime 统计- 入口流量的统计
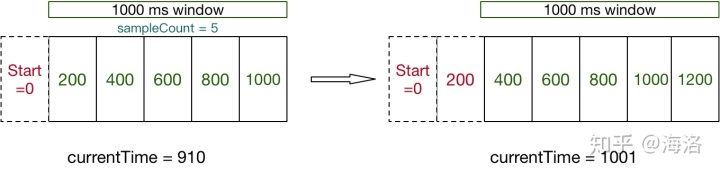
Sentinel 底层采用高性能的滑动窗口数据结构 LeapArray 来统计实时的秒级指标数据,可以很好地支撑写多于读的高并发场景。
FlowSlot
这个 slot 主要根据预设的资源的统计信息,按照固定的次序,依次生效。如果一个资源对应两条或者多条流控规则,则会根据如下次序依次检验,直到全部通过或者有一个规则生效为止:
- 指定应用生效的规则,即针对调用方限流的;
- 调用方为 other 的规则;
- 调用方为 default 的规则。
DegradeSlot
这个 slot 主要针对资源的平均响应时间(RT)以及异常比率,来决定资源是否在接下来的时间被自动熔断掉。
SystemSlot
这个 slot 会根据对于当前系统的整体情况,对入口资源的调用进行动态调配。其原理是让入口的流量和当前系统的预计容量达到一个动态平衡。
注意系统规则只对入口流量起作用(调用类型为 EntryType.IN),对出口流量无效。可通过 SphU.entry(res, entryType) 指定调用类型,如果不指定,默认是EntryType.OUT。
源码分析:
从SphU.entry()入手 。这个方法会去申请一个entry,如果能够申请成功,则说明没有被限流,否则会抛出BlockException,表面已经被限流了。从 SphU.entry() 方法往下执行会进入到 Sph.entry() ,Sph的默认实现类是 CtSph ,在CtSph中最终会执行到 entry(ResourceWrapper resourceWrapper, int count, Object... args) throws BlockException 这个方法。
public Entry entry(ResourceWrapper resourceWrapper, int count, Object... args) throws BlockException {
Context context = ContextUtil.getContext();
if (context instanceof NullContext) {
// Init the entry only. No rule checking will occur.
return new CtEntry(resourceWrapper, null, context);
}
if (context == null) {
context = MyContextUtil.myEnter(Constants.CONTEXT_DEFAULT_NAME, "", resourceWrapper.getType());
}
// Global switch is close, no rule checking will do.
if (!Constants.ON) {
return new CtEntry(resourceWrapper, null, context);
}
// 获取该资源对应的SlotChain
ProcessorSlot<Object> chain = lookProcessChain(resourceWrapper);
/*
* Means processor cache size exceeds {@link Constants.MAX_SLOT_CHAIN_SIZE}, so no
* rule checking will be done.
*/
if (chain == null) {
return new CtEntry(resourceWrapper, null, context);
}
Entry e = new CtEntry(resourceWrapper, chain, context);
try {
// 执行Slot的entry方法
chain.entry(context, resourceWrapper, null, count, args);
} catch (BlockException e1) {
e.exit(count, args);
// 抛出BlockExecption
throw e1;
} catch (Throwable e1) {
RecordLog.info("Sentinel unexpected exception", e1);
}
return e;
}这个方法可以分为以下几个部分:
- 对参数和全局配置项做检测,如果不符合要求就直接返回了一个CtEntry对象,不会再进行后面的限流检测,否则进入下面的检测流程。
- 根据包装过的资源对象获取对应的SlotChain
- 执行SlotChain的entry方法
如果SlotChain的entry方法抛出了BlockException,则将该异常继续向上抛出如果SlotChain的entry方法正常执行了,则最后会将该entry对象返回
如果上层方法捕获了BlockException,则说明请求被限流了,否则请求能正常执行
lookProcessChain的方法实现:
private ProcessorSlot<Object> lookProcessChain(ResourceWrapper resourceWrapper) {
ProcessorSlotChain chain = chainMap.get(resourceWrapper);
if (chain == null) {
synchronized (LOCK) {
chain = chainMap.get(resourceWrapper);
if (chain == null) {
// Entry size limit.
if (chainMap.size() >= Constants.MAX_SLOT_CHAIN_SIZE) {
return null;
}
// 具体构造chain的方法
chain = Env.slotsChainbuilder.build();
Map<ResourceWrapper, ProcessorSlotChain> newMap = new HashMap<ResourceWrapper, ProcessorSlotChain>(chainMap.size() + 1);
newMap.putAll(chainMap);
newMap.put(resourceWrapper, chain);
chainMap = newMap;
}
}
}
return chain;
使用了一个HashMap做了缓存,key是资源对象。这里加了锁,并且做了double check。具体构造chain的方法是通过:Env.slotsChainbuilder.build()这句代码创建的。
public ProcessorSlotChain build() {
ProcessorSlotChain chain = new DefaultProcessorSlotChain();
chain.addLast(new NodeSelectorSlot());
chain.addLast(new ClusterBuilderSlot());
chain.addLast(new LogSlot());
chain.addLast(new StatisticSlot());
chain.addLast(new SystemSlot());
chain.addLast(new AuthoritySlot());
chain.addLast(new FlowSlot());
chain.addLast(new DegradeSlot());
return chain;
}Chain是链条的意思,从build的方法可看出,ProcessorSlotChain是一个链表,里面添加了很多个Slot。具体的实现去DefaultProcessorSlotChain看。
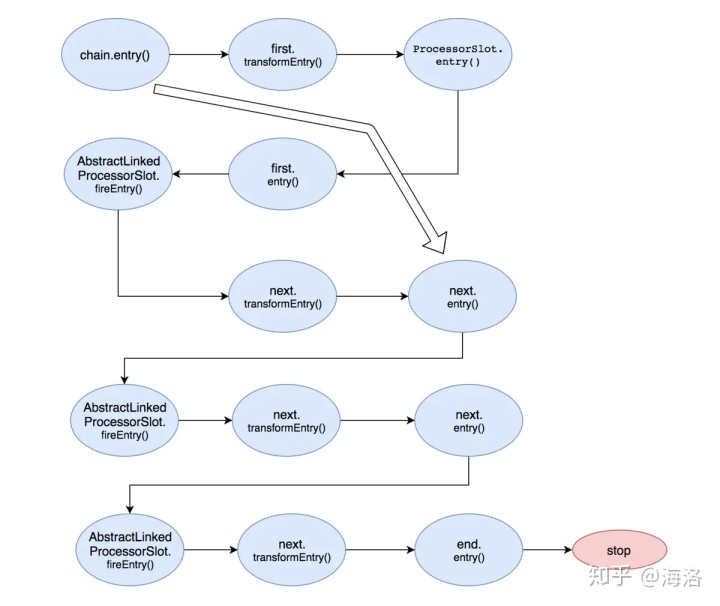
public class DefaultProcessorSlotChain extends ProcessorSlotChain {
AbstractLinkedProcessorSlot<?> first = new AbstractLinkedProcessorSlot<Object>() {
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, Object t, int count, Object... args)
throws Throwable {
super.fireEntry(context, resourceWrapper, t, count, args);
}
@Override
public void exit(Context context, ResourceWrapper resourceWrapper, int count, Object... args) {
super.fireExit(context, resourceWrapper, count, args);
}
};
AbstractLinkedProcessorSlot<?> end = first;
@Override
public void addFirst(AbstractLinkedProcessorSlot<?> protocolProcessor) {
protocolProcessor.setNext(first.getNext());
first.setNext(protocolProcessor);
if (end == first) {
end = protocolProcessor;
}
}
@Override
public void addLast(AbstractLinkedProcessorSlot<?> protocolProcessor) {
end.setNext(protocolProcessor);
end = protocolProcessor;
}
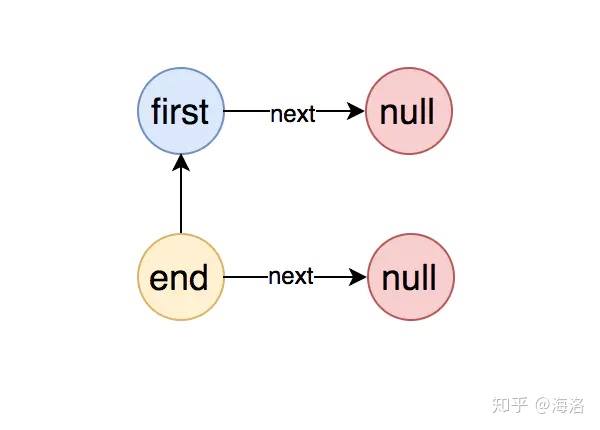
}DefaultProcessorSlotChain中有两个AbstractLinkedProcessorSlot类型的变量:first和end,这就是链表的头结点和尾节点。
创建DefaultProcessorSlotChain对象时,首先创建了首节点,然后把首节点赋值给了尾节点,可以用下图表示:
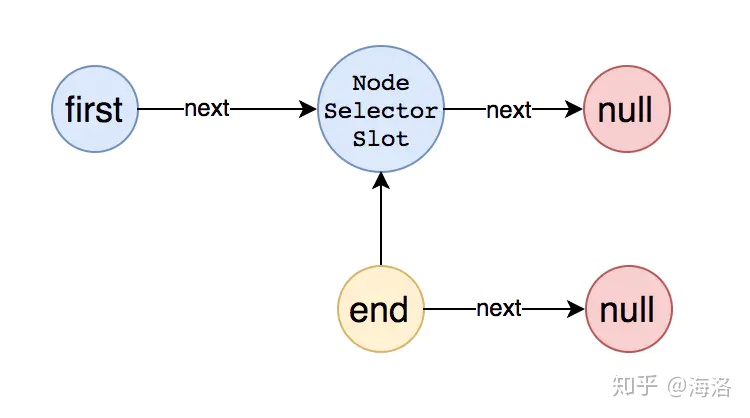
将第一个节点添加到链表中后,整个链表的结构变成了如下图这样:
将所有的节点都加入到链表中后,整个链表的结构变成了如下图所示:
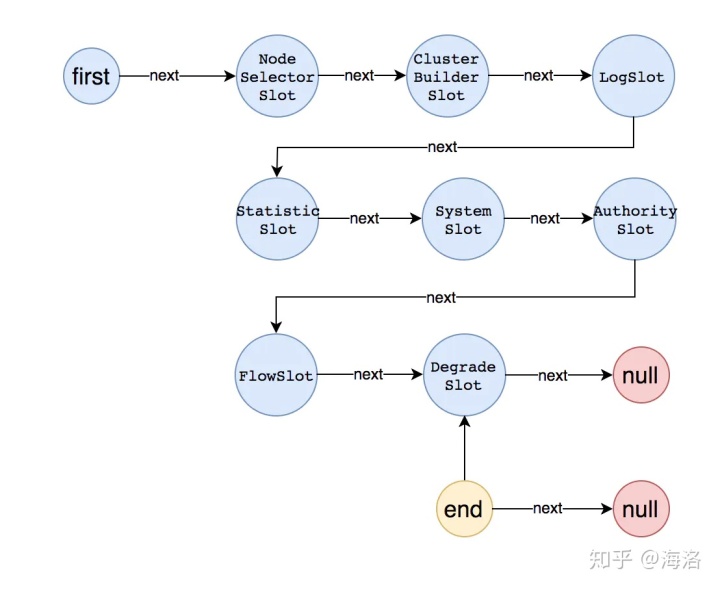
sentinel的责任链传递方式:
每个Slot节点执行完自己的业务后,当统计的结果达到设置的阈值时,就会触发限流、降级等事件,具体是抛出BlockException异常,通过则会调用fireEntry来触发下一个节点的entry方法。如下图:
了解完链路新建执行流程,接下来看一下sentinel底层的滑动窗口算法如何做数据统计的,通过架构图可以看到StatisticSlot中的LeapArray采用了一个环性数组的数据结构:

直接定位到LeapArray 源码
StatisticSlot作为统计的入口,在其entry()方法中可以看到StatisticSlot会使用StatisticNode,然后StatisticNode回去引用ArrayMetric,最终使用LeapArray。
public LeapArray(int sampleCount, int intervalInMs) {
AssertUtil.isTrue(sampleCount > 0, "bucket count is invalid: " + sampleCount);
AssertUtil.isTrue(intervalInMs > 0, "total time interval of the sliding window should be positive");
AssertUtil.isTrue(intervalInMs % sampleCount == 0, "time span needs to be evenly divided");
this.windowLengthInMs = intervalInMs / sampleCount;
this.intervalInMs = intervalInMs;
this.intervalInSecond = intervalInMs / 1000.0;
this.sampleCount = sampleCount;
this.array = new AtomicReferenceArray<>(sampleCount);
}- windowLengthInMs:每个小窗口的时间跨度,rollingCounterInSecond时间跨度是500毫秒,rollingCounterInMinute时间跨度是1000毫秒
- ntervalInMs:窗口的长度,
rollingCounterInSecond变量传入的是1000,即该该时间窗口总的跨度为1秒;rollingCounterInMinute传入的是60000,即该该时间窗口总的跨度为60秒 - sampleCount:样本数量,即当前窗口有多少个小窗口组成,
rollingCounterInSecond传入的是2,则表示当前一秒钟的时间窗口由两个500毫秒的小窗口组成;rollingCounterInMinute传入的是60,即表示当前一分钟的时间窗口由60个1000毫秒的小窗口组成 - array:存放统计数据的数组,个数与sampleCount相同
下标计算:
private int calculateTimeIdx(/*@Valid*/ long timeMillis) {
long timeId = timeMillis / windowLengthInMs;
// 除法取整,保证了一秒内的所有时间戳得到的timeId是相等的
// Calculate current index so we can map the timestamp to the leap array.
//求余运算,保证一秒内获取到的桶的下标位是一致的
return (int)(timeId % array.length());
}当前时间窗口的开始时间:
protected long calculateWindowStart(/*@Valid*/ long timeMillis) {
//保证在窗口时间段内开始时间一致
return timeMillis - timeMillis % windowLengthInMs;
}currentWindow方法(根据当前时间获取滑动窗口):
public WindowWrap<T> currentWindow(long timeMillis) {
if (timeMillis < 0) {
return null;
}
int idx = calculateTimeIdx(timeMillis);
// Calculate current bucket start time.
long windowStart = calculateWindowStart(timeMillis);
/*
* Get bucket item at given time from the array.
*
* (1) Bucket is absent, then just create a new bucket and CAS update to circular array.
* (2) Bucket is up-to-date, then just return the bucket.
* (3) Bucket is deprecated, then reset current bucket and clean all deprecated buckets.
*/
while (true) {
WindowWrap<T> old = array.get(idx);
if (old == null) {
/*
* B0 B1 B2 NULL B4
* ||_______|_______|_______|_______|_______||___
* 200 400 600 800 1000 1200 timestamp
* ^
* time=888
* bucket is empty, so create new and update
*
* If the old bucket is absent, then we create a new bucket at {@code windowStart},
* then try to update circular array via a CAS operation. Only one thread can
* succeed to update, while other threads yield its time slice.
*/
WindowWrap<T> window = new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
if (array.compareAndSet(idx, null, window)) {
// Successfully updated, return the created bucket.
return window;
} else {
// Contention failed, the thread will yield its time slice to wait for bucket available.
Thread.yield();
}
} else if (windowStart == old.windowStart()) {
/*
* B0 B1 B2 B3 B4
* ||_______|_______|_______|_______|_______||___
* 200 400 600 800 1000 1200 timestamp
* ^
* time=888
* startTime of Bucket 3: 800, so it's up-to-date
*
* If current {@code windowStart} is equal to the start timestamp of old bucket,
* that means the time is within the bucket, so directly return the bucket.
*/
return old;
} else if (windowStart > old.windowStart()) {
/*
* (old)
* B0 B1 B2 NULL B4
* |_______||_______|_______|_______|_______|_______||___
* ... 1200 1400 1600 1800 2000 2200 timestamp
* ^
* time=1676
* startTime of Bucket 2: 400, deprecated, should be reset
*
* If the start timestamp of old bucket is behind provided time, that means
* the bucket is deprecated. We have to reset the bucket to current {@code windowStart}.
* Note that the reset and clean-up operations are hard to be atomic,
* so we need a update lock to guarantee the correctness of bucket update.
*
* The update lock is conditional (tiny scope) and will take effect only when
* bucket is deprecated, so in most cases it won't lead to performance loss.
*/
if (updateLock.tryLock()) {
try {
// Successfully get the update lock, now we reset the bucket.
return resetWindowTo(old, windowStart);
} finally {
updateLock.unlock();
}
} else {
// Contention failed, the thread will yield its time slice to wait for bucket available.
Thread.yield();
}
} else if (windowStart < old.windowStart()) {
// Should not go through here, as the provided time is already behind.
return new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
}
}
}- 如果桶不存在则创建新的桶,并通过CAS将新桶赋值到数组下标位。
- 如果获取到的桶不为空,并且桶的开始时间等于刚刚算出来的时间,那么返回当前获取到的桶。
- 如果获取到的桶不为空,并且桶的开始时间小于刚刚算出来的开始时间,那么说明这个桶是上一圈用过的桶,使用Lock重置当前桶,并返回。
- 果获取到的桶不为空,并且桶的开始时间大于刚刚算出来的开始时间,理论上不会出现这种情况:不应该经过这里,因为规定的时间已经过去了。
这里比较值得学习的地方:
- 对并发的控制:当一个新桶的创建直接是使用的CAS的原子操作来保证并发;但是重置一个桶的时候因为很难保证其原子操作(1. 需要重置多个值;2. 重置方法是一个抽象方法,需要子类去做实现),所以直接使用一个
ReentrantLock锁来做并发控制。 - 对
Thread.yield();方法的使用,这个方法主要的作用是交出CPU的执行权,并重新竞争CPU执行权。这个方法在业务代码中其实很少用到。
sentinel官网:
alibaba/Sentinelgithub.com
最后
以上就是成就鸵鸟最近收集整理的关于sentinel 时间窗口_Sentinel: 分布式系统的流量防卫兵的全部内容,更多相关sentinel内容请搜索靠谱客的其他文章。








发表评论 取消回复