在深度学习中会遇到各种各样的任务,我们期望通过优化最终的loss使网络模型达到期望的效果,因此loss的选择是十分重要的。
cross entropy loss
cross entropy loss和log loss,logistic loss是同一种loss。常用于分类问题,一般是配合softmax使用的,通过softmax操作得到每个类别的概率值,然后计算loss。
softmax函数为:
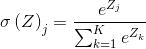 ,
,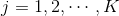 ,
,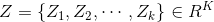
除了e,还可以使用另一个底数b,b>0,选择一个较大的b值,将创建一个概率分布,该分布更集中于输入值最大的位置。 或
或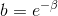 ,因此,softmax函数又可以写作
,因此,softmax函数又可以写作
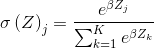 或
或 ,
,
softmax函数的输出是一个概率分布,概率和为1。
cross entropy loss为:

cross entropy loss用来度量模型预测分布和真实分布之间的距离,是平方误差(MSE)的一种广泛应用的替代方法。一般用于当输出特征为概率分布时,输出特征的每个值代表估计为对应类别的概率。
hingle loss
hingle loss是机器学习模型中用于训练分类器的loss,用于“最大间隔”分类。对于二分类,ground truth t= 1,预测结果为y,则hingle loss为
1,预测结果为y,则hingle loss为
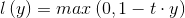
注意y是分类器决策函数的原始输出,而不是经过处理德奥的预测类别。
Mean Squre Error (MSE/L2 loss)
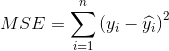 ,
,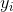 表示ground truth,
表示ground truth, 表示预测结果。
表示预测结果。
Mean Absolute Error (MAE/ L1 loss)
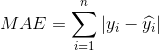 ,表示ground truth,表示预测结果。
,表示ground truth,表示预测结果。
L1 loss和L2 loss的区别:
L2 loss对异常值比较敏感,L1 loss比起L2 loss不易受异常值的影响,更加鲁棒,但在0处不可导。L2 loss有稳定的唯一的解决方案,而L1 loss的解决方案则不一定唯一。
L2 loss优化能力较L1 loss更强一些。在训练神经网络时,L1 loss更新的梯度始终相同,也就是说,即使对于很小的损失值,梯度也很大。这样不利于模型的学习。为了解决这个缺陷,我们可以使用变化的学习率,在损失接近最小值时降低学习率。而L2 loss在这种情况下的表现就很好,即便使用固定的学习率也可以有效收敛。L2 loss的梯度随损失增大而增大,而损失趋于0时则会减小。这使得在训练结束时,使用L2 loss的模型的结果会更精确。
如果异常值代表在商业中很重要的异常情况,并且需要被检测出来,则应选用L2 loss。相反,如果只把异常值当作受损数据,则应选用L1 loss。
Huber loss (smooth L1 loss)
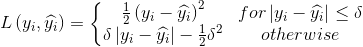 ,
,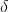 是一个可调参数。
是一个可调参数。
Huber loss相对于L2 loss,对异常值不敏感,而且在0处可导。Huber loss可以看作是L1 loss和L2 loss的结合体,在误差较大时,Huber loss等效于L1 loss,在误差较小时,Huber loss等效于L2 loss。
Log-cos loss
log-cos是另一种应用于回归问题中的,且比L2更平滑的损失函数。它的计算方式是预测误差的双曲余弦的对数。
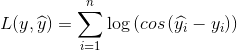
优点:对于较小的x,log(cos(x))近似等于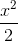 ,对于较大的x,近似等于abs(x)-log2。这意味着log-cos基本类似于均方误差,但不易受到异常点的影响。它具有Huber loss的所有优点,但不同于Huber loss的是,log-cos二阶处处可微。
,对于较大的x,近似等于abs(x)-log2。这意味着log-cos基本类似于均方误差,但不易受到异常点的影响。它具有Huber loss的所有优点,但不同于Huber loss的是,log-cos二阶处处可微。
为什么需要二阶导数?许多机器学习模型如XGBoost,即使采用牛顿法来寻找最优点。而牛顿法就需要求解二阶导数(Hessian)。因此对于诸如XGBoost这类机器学习框架,损失函数的二阶可微是很有必要的。
转载于:https://www.cnblogs.com/Peyton-Li/p/10142810.html
最后
以上就是坚定大树最近收集整理的关于deep learning loss总结的全部内容,更多相关deep内容请搜索靠谱客的其他文章。








发表评论 取消回复