scrapy中的response的编码:response.encoding。
如果出现编码问题,可以使用以下语句:
def news_parse_3(self, response):
soup = BeautifulSoup(response.body.decode(encoding=response.encoding, errors='ignore'), 'html.parser')如果想在请求之间传递参数的话,可以使用meta属性
yield scrapy.Request(url, callback=self.func, meta={})使用;
rsponse.meta['xx']
使用命令运行爬虫时,可以使用-a选项来添加参数,然后在在相应的类中使用(变成了类属性,使用self.xxx访问),一个-a只能跟一个参数。传进去的都是字符串。
scrapy crawl myspider -a category=electronicsgetattr(self, 'tag', None)
或
self.tag # 这个可能会抛出异常
class scrapy.spiders.Rule(link_extractor,callback = None,cb_kwargs = None,follow = None,process_links = None,process_request = None )
cb_kwargs 是一个包含要传递给回调函数的关键字参数的dict。
图片管道:
ITEM_PIPELINES = {'scrapy.pipelines.images.ImagesPipeline': 1}
IMAGES_STORE = '/path/to/valid/dir'
文件管道:
ITEM_PIPELINES = {'scrapy.pipelines.files.FilesPipeline': 1}
FILES_STORE = '/path/to/valid/dir'在代码在获取settings中的变量:
pipelines.py
self.settings['xxx']
class SomethingPipeline(object):
def __init__(self):
# 可选实现,做参数初始化等
def process_item(self, item, spider):
return item
def open_spider(self, spider):
# 可选实现,当spider被开启时,这个方法被调用。
def close_spider(self, spider):
# 可选实现,当spider被关闭时,这个方法被调用
暂停scrapy爬虫执行
通过增加参数JOBDIR来进行,有2中加参数的方法。
1. 直接在启用爬虫时,即在命令行中加入参数:
scrapy crawl pachong -s JOBDIR=xxx/001上述命令会启动爬虫,当我们在按ctrl+c(只按一次)停止爬虫,停止后就会在目录xxx/001下生成相关文件,用来保存相关信息。
下次我们想接着上次爬,就可以用如下命令启动爬虫,代表我们使用xxx/001文件夹下的状态信息:
scrapy crawl onespider -s JOBDIR=xxx/001该命令运行后按下一次ctrl+c后scrapy接收到一次暂停的信号注意这里只能按一次ctrl+c如果按了两次就表示强制退出了。
注:生成的xxx/001目录在项目的根目录下(即与scrapy.cfg文件在同一目录)。
2. 直接在设置文件settings.py里加入下面的代码:
JOBDIR='xxx/001'
使用命令scrapy crawl onespider,就会自动生成一个xxx/001的目录,然后将工作列表放到这个文件夹里。
注:当第二次输入启动命令启动时爬虫可能会覆盖掉原来的数据,因为你打开文件不是使用的append模式。
--
docker pull scrapinghub/splash
docker run -p 8050:8050 -p 5023:5023 scrapinghub/splash
docker run -p 8050:8050 scrapinghub/splash
scrapy的css选择器
*
所有节点
#xxx
选择id为xxx的节点
.xxx
选择class为xxx的节点
li a
选择所有li下的所有a节点(即li下的所有子孙节点a)
li,a
选择所有li和a节点
ul + p
选择ul后的第一个p节点(ul的兄弟节点p)
div#xxx > ul
选择id为xxx的div的第一个ul子节点
ul ~ p
选取与ul相邻的所有的p元素
a[title]
选取所有包含有title属性的a元素
a[href="http://jobbole.com"]
选取所有href属性为jobbole.com的a元素
a[href*="jobbole"]
选取所有href属性包含jobbole的a元素
a[href^="http"]
选取所有href属性以http开头的a元素
a[href$=".jpg"]
选取所有href属性以.jpg结尾的a元素
div:not(#xxx)
选取所有id不为xxx的div元素
li:nth-child(3)
选取第三个li元素
p:nth-last-child(2)
反选第2个p标签
tr:nth-child(2n)
第偶数个tr
p:last-child
选择每个p元素是其父级的最后一个子级。
xxx::text
选取xxx标签的文本内容
xxx:attr[yyy]
选取xxx标签的yyy属性
scrapy的xpath选择器
@xxx
选取含有属性xxx的节点
//
选取所有节点
a/@href
选择a标签下的href属性
a/text()
选择a标签下的文本
/artical/div[1]
选取所有属于artical 子元素的第一个div元素
/artical/div[last()]
/artical/div[position()<3]
选取所有属于artical子元素的前2个div元素
//div[@class]
选取所有拥有属性class的div节点
//div[@class=”main”]
选取所有div下class属性为main的div节点
//div[starts-with(@id,”ma”)]
选取id值以ma开头的div节点
//div[contains(@id,”ma”)]
//div[contains(@id,”ma”) and contains(@id,”in”)]
//div[contains(text(),”ma”)]
选取节点文本包含ma的div节点
对css或xpath的选取起辅助作用:检查网页源代码,然后在相应的标签出右键单击。
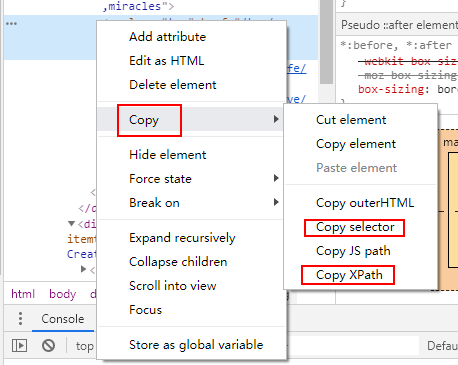
此外,还可以在console中使用表达式 $x('xpath表达式') 来获取相应节点:
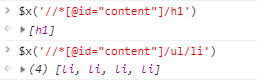
使用$获取css表达式(Copy selector),使用$x获取xpath表达式(Copy xpath)。
?处理爬取页面状态码不是200的情况
1. 记录错误页面信息,可以继承类 HttpErrorMiddleware, 实现其中的process_spider_input方法,将状态码为404的response的url写到某个文件中。
2. 为了减少IO操作,可以用一个变量记录下所有的404 url,然后将crawler绑定spider_closed信号,这样就能在爬虫关闭的时候将记录下的url一并写入。
最后
以上就是称心大地最近收集整理的关于爬虫 scrapy+beautifulsoup的一些小知识点暂停scrapy爬虫执行--?处理爬取页面状态码不是200的情况的全部内容,更多相关爬虫内容请搜索靠谱客的其他文章。








发表评论 取消回复