
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:冈坂日川
今天发的是python爬虫爬取中国大学排名,并且保存到excel中,当然这个代码很简单,我用了半小时就写完了,我的整体框架非常清晰,可以直接拿去用,也希望有小白可以学习到关于爬虫的一些知识,当然我也只是在学习中,有不好的地方还麻烦大佬们指正!谢谢!

爬取中国大学排名
request 获取 html
beautiful soup 解析网页
re 正则表达式匹配内容
新建并保存 excelfrom bs4 import BeautifulSoup # 网页解析 获取数据
import re # 正则表达式 进行文字匹配
import urllib.request, urllib.error # 制定url 获取网页数据
import xlwt
def main():
baseurl = "http://m.gaosan.com/gaokao/265440.html"
# 1爬取网页
datalist = getData(baseurl)
savepath = "中国大学排名.xls"
saveData(datalist,savepath)
# 正则表达式
paiming = re.compile(r'<td>(.*)</td><td>.*</td><td>.*</td><td>.*</td><td>.*</td>') # 创建超链接正则表达式对象,表示字符串模式,规则
xuexiao = re.compile(r'<td>.*</td><td>(.*)</td><td>.*</td><td>.*</td><td>.*</td>')
defen = re.compile(r'<td>.*</td><td>.*</td><td>(.*)</td><td>.*</td><td>.*</td>')
xingji = re.compile(r'<td>.*</td><td>.*</td><td>.*</td><td>(.*)</td><td>.*</td>')
cengci = re.compile(r'<td>.*</td><td>.*</td><td>.*</td><td>.*</td><td>(.*)</td>')
# 爬取网页
def getData(baseurl):
datalist = []
html = askURL(baseurl) # 保存获取到的网页源码
# print(html)
#【逐一】解析数据 (一个网页就解析一次)
soup = BeautifulSoup(html, "html.parser") # soup是解析后的树形结构对象
for item in soup.find_all('tr'): # 查找符合要求的字符串形成列表
# print(item) #测试查看item全部
data = [] # 保存一个学校的所有信息
item = str(item)
#排名
paiming1 = re.findall(paiming, item) # re正则表达式查找指定字符串 0表示只要第一个 前面是标准后面是找的范围
# print(paiming1)
if(not paiming1):
pass
else:
print(paiming1[0])
data.append(paiming1)
if(paiming1 in data):
#学校名字
xuexiao1 = re.findall(xuexiao, item)[0]
# print(xuexiao1)
data.append(xuexiao1)
#得分
defen1 = re.findall(defen, item)[0]
# print(defen1)
data.append(defen1)
#星级
xingji1 = re.findall(xingji, item)[0]
# print(xingji1)
data.append(xingji1)
#层次
cengci1 = re.findall(cengci, item)[0]
# print(cengci1)
data.append(cengci1)
# print('-'*80)
datalist.append(data) # 把处理好的一个学校信息放入datalist中
return datalist
# 得到指定一个url网页信息内容
def askURL(url):
# 我的初始访问user agent
head = { # 模拟浏览器头部信息,向豆瓣服务器发送消息 伪装用的
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36"
}
# 用户代理表示告诉豆瓣服务器我们是什么类型的机器--浏览器 本质是告诉浏览器我们可以接受什么水平的文件内容
request = urllib.request.Request(url, headers=head) # 携带头部信息访问url
# 用request对象访问
html = ""
try:
response = urllib.request.urlopen(request) # 用urlopen传递封装好的request对象
html = response.read().decode("utf-8") # read 读取 可以解码 防治乱码
# print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code) # 打印错误代码
if hasattr(e, "reason"):
print(e.reason) # 打印错误原因
return html
# 3保存数据
def saveData(datalist, savepath):
book = xlwt.Workbook(encoding="utf-8", style_compression=0) # 创建workbook对象 样式压缩效果
sheet = book.add_sheet('中国大学排名', cell_overwrite_ok=True) # 创建工作表 一个表单 cell覆盖
for i in range(0, 640):
print("第%d条" % (i + 1))
data = datalist[i]
# print(data)
for j in range(0, 5): # 每一行数据保存进去
sheet.write(i , j, data[j]) # 数据
book.save(savepath) # 保存数据表
#主函数
if __name__ == "__main__": # 当程序执行时
# #调用函数 程序执行入口
main()
# init_db("movietest.db")
print("爬取完毕!")
具体实现效果如下
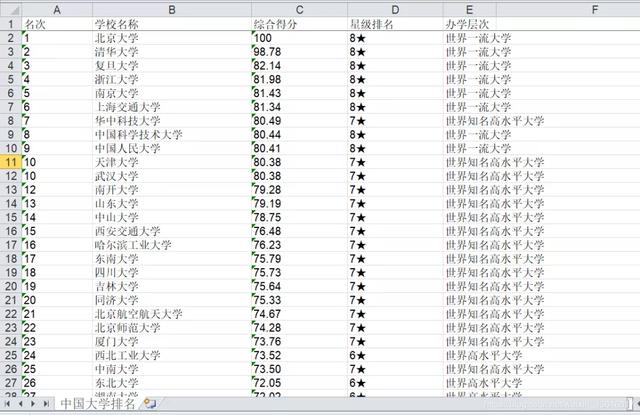
一共600多条数据
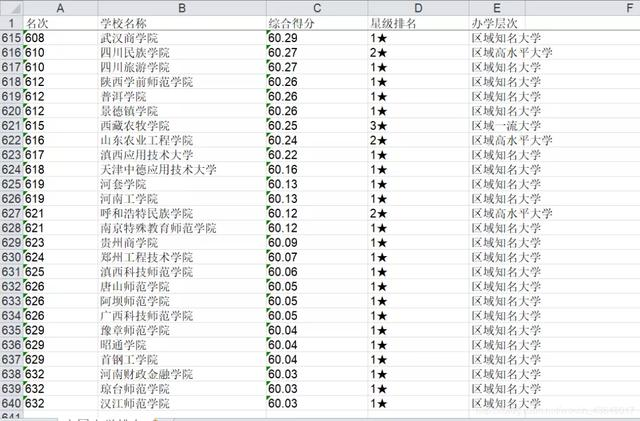
最后
以上就是忐忑小笼包最近收集整理的关于python爬虫爬取2020年中国大学排名的全部内容,更多相关python爬虫爬取2020年中国大学排名内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复