在经过多轮的ABtest之后,产出了很多的数据,同时也有很多的指标,那么到底哪个指标的重要性更大一些呢,方法有很多,例如:主观经验法、专家调查法、层次分析法、熵值法,本次就使用R语言实现熵值法求权重
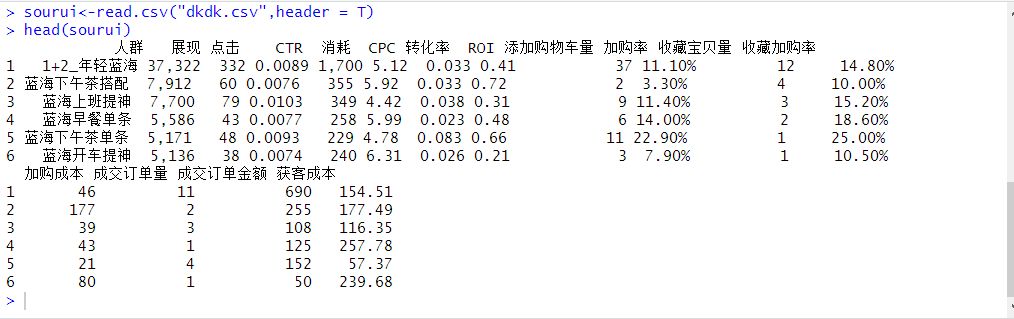
第一步导入数据看看
本次数据取自淘宝后台某家店铺,可以看到数据大多已经经过处理
sourui<-read.csv("dkdk.csv",header = T)
head(sourui)
str(sourui)
第二步取出本次要评估的指标
本次需要评估的指标是,点击率、获客成本,随后进行数据归一化(数据收敛),点击率是正向指标,而获客成本是负向指标,理解起来就是点击率越大越好,而获客成本越小越好,商人逐利嘛,最终得到0~1的归一化数据
sourui[is.na(sourui)]<-0
tt<-sourui[,c(4,16)]
#归一化处理
min.max.norm <- function(x){
(x-min(x))/(max(x)-min(x))
}
max.min.norm <- function(x){
(max(x)-x)/(max(x)-min(x))
}
tt$获客成本<-max.min.norm(tt$获客成本) #负向
tt$CTR<-min.max.norm(tt$CTR) #正向

第三步求出所有样本对指标Xj的贡献总量
#第三步:求出所有样本对指标Xj的贡献总量
sourui_t<-tt
first1 <- function(data)
{
x <- c(data)
for(i in 1:length(data))
x[i] = data[i]/sum(data[])
return(x)
}
dataframe <- apply(sourui_t,2,first1)
第四步计算信息熵
first2 <- function(data)
{
x <- c(data)
for(i in 1:length(data)){
if(data[i] == 0){
x[i] = 0
}else{
x[i] = data[i] * log(data[i])
}
}
return(x)
}
dataframe1 <- apply(dataframe,2,first2)
k <- 1/log(length(dataframe1[,1]))
d <- -k * colSums(dataframe1)
第五步计算冗余度
d <- 1-d
第六步计算各项指标的权重
#计算权重
w <- d/sum(d)
w
#计算评分
newtt<-ceiling((tt$CTR*0.7005496+tt$获客成本*0.2994504)*100)
sourui$score<-newtt
sourui[,c(1,17)]

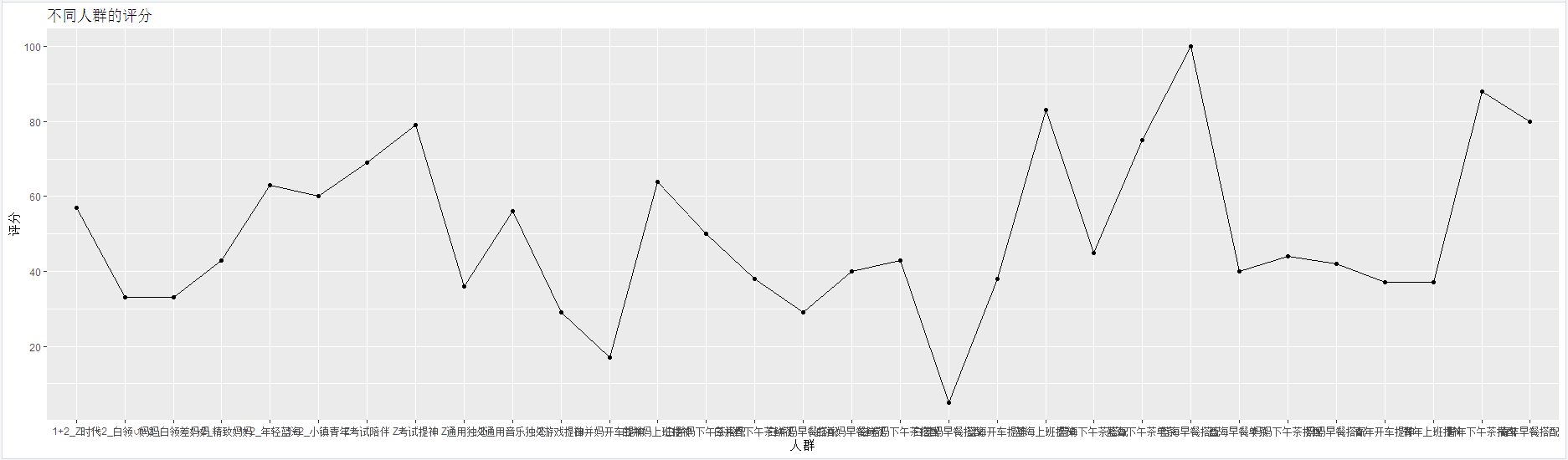
画了个丑陋的折线图
最后
以上就是聪慧烧鹅最近收集整理的关于电商行业之熵值法求权重的全部内容,更多相关电商行业之熵值法求权重内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复