MapReduce核心思想
分而治之,先分后和:将一个大的、复杂的工作或任务,拆分成多个小的任务,并行处理,最终进行合并。
MapReduce由Map和Reduce组成
Map: 将数据进行拆分
Reduce:对数据进行汇总
理论看不懂,跑个Java代码会有直观的印象。
这里我用的idea,使用的是maven项目,下面这个是pom文件,你得导这些包才能用hadoop
而且你得安装并配置hadoop2.7.4环境变量。如果你已经配置完毕,就继续吧,如果没有,可以看这个
https://blog.csdn.net/weixin_42072754/article/details/102947374
pom文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.czxy</groupId>
<artifactId>hadoop01</artifactId>
<version>1.0-SNAPSHOT</version>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-client</artifactId>
<version>2.6.0-mr1-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-common</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-hdfs</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-mapreduce-client-core</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
<!-- <plugin>
<artifactId>maven-assembly-plugin </artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>cn.itcast.Hadoop.db.DBToHdfs2</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>-->
</plugins>
</build>
</project>
首先准备数据文件 SumData.txt,内容如下:
27 41 39 29 51 45 24 28 56 52 29 51 18 25 19 10 52 37 18 25 23 52 19 33 59 24 39 58 51 12
44 10 42 19 35 28 39 33 58 45 28 35 26 55 32 33 27 40 10 31 42 15 41 56 42 47 40 45 28 52
52 28 50 12 42 28 17 50 31 33 42 14 34 19 23 22 40 21 54 43 52 29 38 53 34 28 11 15 25 44
27 27 43 58 24 12 33 45 39 43 19 57 38 55 54 29 28 58 36 44 59 26 27 21 31 55 29 53 39 38
58 52 46 37 20 49 10 28 15 24 35 38 14 44 59 48 42 18 59 38 43 23 19 28 30 24 36 10 30 15
59 26 21 28 54 53 54 49 12 16 12 28 28 55 33 27 25 19 32 56 19 45 43 33 33 53 38 40 45 39
17 57 26 35 57 47 43 15 52 57 52 56 39 26 12 57 38 32 15 30 22 48 14 29 12 47 37 29 59 57
11 34 54 13 43 41 45 59 58 42 36 13 32 55 18 51 14 13 40 58 58 19 39 15 25 55 36 30 10 52
31 46 12 53 58 52 11 17 39 33 23 16 23 56 22 42 48 23 38 40 49 46 28 46 53 33 27 53 40 32
25 23 36 46 21 22 47 21 52 11 24 20 14 16 57 38 21 16 42 29 14 38 32 10 39 57 16 23 53 58
58 14 54 43 10 32 13 18 46 10 30 27 20 14 41 46 26 15 31 23 18 38 18 15 46 38 33 42 47 42
48 15 59 32 49 15 57 13 27 53 37 18 40 49 19 54 43 58 33 29 55 49 43 56 11 26 10 10 34 36
24 17 41 25 31 51 22 26 41 48 55 46 32 11 56 36 31 12 43 13 52 24 47 14 30 22 28 14 56 27
10 25 14 45 33 28 51 58 31 17 30 50 57 51 12 25 56 24 31 44 11 21 43 19 21 46 24 59 37 31
22 20 49 27 36 11 27 42 14 25 38 58 18 48 17 13 35 42 57 38 24 13 57 13 46 54 35 43 12 38
54 55 21 52 58 17 22 47 21 55 49 23 32 54 48 45 43 36 45 33 57 40 10 37 57 45 29 25 12 32
37 14 25 46 25 55 15 59 30 54 25 36 48 30 51 31 54 26 35 56 32 52 37 57 34 54 41 55 40 51
47 33 35 56 40 52 33 53 58 32 43 26 46 25 10 41 55 37 58 43 57 20 40 23 35 22 42 19 38 30
49 33 52 22 57 19 39 22 42 21 41 24 57 33 53 21 35 18 38 18 44 58 52 50 44 23 18 26 19 21
47 54 24 48 59 29 43 37 46 42 40 38 24 48 38 24 17 25 23 30 26 33 20 28 12 41 28 35 45 22
18 13 21 36 10 30 55 19 21 41 37 37 33 40 38 40 36 34 21 52 33 40 40 31 51 52 59 34 34 32
26 22 21 38 20 40 12 32 59 24 22 29 23 22 18 48 16 17 59 46 53 40 47 43 26 16 23 17 18 14
35 29 43 20 27 22 21 15 11 20 29 15 13 20 10 17 10 33 42 36 17 48 32 28 29 23 32 19 45 55
35 55 18 17 12 20 13 17 54 13 51 10 43 15 43 13 46 21 47 48 55 51 19 32 53 33 52 16 23 47
22 33 52 23 43 25 34 39 22 42 21 51 58 48 24 30 12 55 36 43 38 24 20 53 42 26 33 14 47 55
30 55 20 59 16 11 40 10 43 33 16 58 43 55 54 25 54 47 59 29 51 21 54 59 26 13 23 19 19 17
44 14 38 23 45 42 47 43 13 15 29 17 27 28 37 30 51 26 59 15 30 33 47 21 28 38 49 46 14 51
28 55 58 11 27 34 17 46 27 34 46 56 39 31 53 52 17 56 28 49 27 39 49 16 19 12 28 26 27 42
28 27 27 26 34 53 55 13 11 40 47 35 58 15 18 38 30 57 48 54 59 16 54 56 12 27 57 12 41 13
25 54 33 21 19 57 45 33 10 57 12 57 26 38 26 31 39 53 31 59 55 25 46 54 59 47 34 57 23 39
33 52 39 42 15 56 54 43 39 36 13 18 53 29 17 22 29 50 20 19 55 25 22 27 12 41 47 32 55 52
13 30 26 18 58 20 52 30 50 23 11 38 58 28 45 14 44 45 27 23 19 16 24 22 12 35 47 20 57 39
41 49 17 37 45 59 32 34 22 13 53 25 13 51 17 18 35 31 28 40 39 34 52 22 16 12 40 36 17 55
56 45 14 32 20 40 36 16 34 55 43 33 38 43 49 36 41 49 57 17 13 10 39 18 30 28 19 15 29 41
19 49 17 38 49 57 10 50 23 32 22 16 12 42 43 30 18 59 29 19 18 24 55 52 46 43 57 51 48 58
47 35 23 46 36 33 26 43 28 22 45 57 18 35 36 23 13 51 56 25 37 15 12 59 17 29 21 18 34 37
27 18 38 58 14 14 54 40 52 25 15 53 22 26 27 10 57 27 26 55 11 44 17 56 57 41 31 10 40 24
57 45 44 51 41 44 26 22 45 33 20 21 11 59 28 46 51 45 42 19 24 47 35 25 54 35 10 13 53 34
22 10 52 42 22 50 32 28 23 21 49 49 39 53 15 44 26 52 36 53 16 29 41 14 50 38 40 30 53 50
38 28 29 17 55 27 46 11 25 40 36 33 41 43 57 30 32 20 11 51 21 17 49 26 28 45 42 36 50 10
21 11 14 30 27 21 37 47 26 16 43 41 25 17 18 58 36 14 26 40 39 48 20 39 44 49 13 19 57 57
24 35 14 50 20 41 26 16 19 57 32 20 27 21 49 31 59 23 44 34 57 43 55 33 17 11 58 31 21 22
10 38 59 36 30 53 41 15 24 19 18 43 14 51 25 45 24 37 23 56 20 38 18 15 53 52 20 43 32 55
50 46 54 59 47 33 46 25 25 54 29 49 46 25 15 53 58 53 24 13 42 32 47 17 40 36 14 12 51 24
27 15 55 33 11 51 24 36 24 11 52 40 25 15 33 32 14 43 30 17 41 35 43 39 21 28 44 35 42 44
26 46 58 22 57 30 18 56 34 31 21 44 41 57 53 26 14 37 49 57 51 54 44 17 57 11 15 57 27 18
35 14 37 57 35 46 16 12 46 25 57 29 11 59 30 50 57 11 36 24 59 30 26 34 30 25 21 37 57 22
31 13 51 27 55 35 32 54 50 56 46 51 16 12 34 59 55 52 16 15 59 23 44 15 18 48 23 36 13 41
37 45 20 23 46 46 24 53 19 51 26 25 49 47 42 24 48 40 28 12 26 51 52 22 18 42 23 18 30 26
49 21 35 10 33 25 22 16 28 55 28 10 10 50 41 33 19 57 46 13 47 34 27 10 11 34 28 29 17 39
58 30 21 35 23 38 44 32 31 51 52 39 45 53 47 43 10 56 52 27 10 44 37 59 34 56 25 30 24 50
46 51 57 30 30 50 39 12 49 52 10 49 57 56 31 10 21 53 31 19 42 33 55 21 29 11 51 29 52 10
15 55 25 31 52 55 50 37 11 39 40 22 30 25 49 13 57 24 27 22 29 51 28 42 51 24 16 46 25 30
17 53 39 12 28 32 35 12 11 24 57 58 44 58 39 25 46 24 12 26 40 20 56 20 47 20 17 55 41 15
29 41 11 23 20 52 22 24 34 15 29 44 58 35 12 20 25 24 42 53 12 22 24 10 59 14 50 28 28 30
16 19 18 10 12 39 39 26 19 16 26 23 37 45 31 58 10 54 29 26 40 16 16 51 39 12 26 36 39 53
13 23 14 16 20 22 40 10 25 39 40 17 25 48 43 17 10 40 47 49 58 40 55 30 55 19 37 10 53 15
47 46 25 33 19 48 48 40 32 59 35 40 46 41 31 39 46 42 28 51 55 13 15 50 58 53 49 53 51 12
22 56 40 35 48 46 25 21 27 35 34 43 22 29 39 45 29 35 31 39 46 33 17 10 28 47 55 17 53 47
54 58 35 56 14 11 45 19 52 21 44 12 55 48 51 50 26 45 28 45 35 56 25 31 37 31 59 34 42 13
40 46 39 23 41 11 30 53 21 14 48 10 59 11 58 11 45 44 46 16 22 59 55 17 19 18 44 43 55 48
53 15 50 39 32 39 35 15 36 33 38 24 17 42 19 13 46 50 49 55 10 50 35 25 52 24 29 33 21 25
15 55 31 30 34 50 40 27 32 38 12 36 29 15 19 39 26 25 28 10 53 22 10 37 21 14 24 34 33 59
34 37 21 59 45 23 22 50 49 11 56 40 58 58 59 28 18 55 42 55 47 31 50 45 53 31 51 42 28 34
10 54 11 30 14 31 12 33 11 57 14 58 49 20 39 38 19 25 22 32 36 34 19 59 30 49 12 29 35 30
36 54 56 55 33 51 41 20 25 28 30 37 16 25 22 52 20 24 36 27 23 46 48 10 30 57 10 50 32 37
12 38 31 19 22 49 32 28 40 57 47 51 50 52 48 55 47 37 58 30 37 36 58 41 34 40 36 21 19 22
49 35 47 55 24 34 32 11 56 10 18 11 43 55 13 56 54 58 53 43 12 15 22 53 52 10 16 12 41 13
26 33 24 10 14 19 52 37 58 38 37 49 57 59 18 59 45 14 48 43 47 45 38 43 21 33 24 40 44 43
36 43 22 54 41 19 15 53 52 56 31 39 18 59 41 36 40 35 38 46 22 33 24 34 44 50 46 52 45 59
43 53 37 30 33 30 25 45 23 44 34 25 35 26 21 29 51 44 52 58 12 41 39 14 34 40 42 23 44 20
12 18 39 29 15 21 18 24 16 52 56 12 35 41 32 18 22 21 55 17 25 50 54 58 42 38 42 37 55 53
13 11 42 38 40 52 51 32 39 44 13 12 11 57 51 57 35 45 44 30 18 37 58 57 56 27 58 54 58 53
34 32 36 32 13 40 18 15 43 55 45 53 49 56 49 32 47 48 36 51 29 27 31 32 14 12 15 14 42 10
53 44 49 27 54 38 46 50 57 44 45 44 28 34 33 21 22 30 47 18 11 45 17 43 29 13 29 46 45 42
13 22 40 22 27 14 55 52 33 20 19 10 13 49 33 51 19 29 28 16 39 49 42 37 46 55 13 28 25 35
28 49 31 50 49 14 45 38 11 41 37 52 30 27 41 55 53 33 14 28 41 12 28 20 14 20 49 51 22 38
30 39 28 49 33 54 12 13 13 25 41 36 19 39 21 49 48 12 29 31 49 31 39 10 20 39 10 16 35 18
40 37 33 14 11 43 48 43 25 22 52 23 33 37 10 14 27 10 41 37 50 22 11 52 12 45 19 14 13 10
49 52 47 29 48 15 12 59 12 44 33 15 57 50 47 44 22 45 11 50 45 53 24 34 59 21 51 32 15 36
30 21 45 57 10 42 51 21 20 43 44 11 16 20 56 23 46 58 21 52 58 23 17 36 25 20 17 32 16 19
36 32 46 40 57 51 40 20 14 18 22 41 29 33 52 31 48 29 43 59 56 44 13 29 19 13 46 55 52 30
23 55 53 42 31 26 42 17 36 51 33 14 53 35 27 29 59 56 11 28 19 33 30 22 39 54 45 51 15 47
42 43 30 27 56 34 29 59 21 36 58 27 46 15 29 11 40 32 29 24 36 31 26 38 23 56 32 53 52 18
28 33 38 55 41 36 37 45 40 52 46 49 14 54 53 14 28 25 57 31 27 10 29 31 46 42 36 52 17 57
41 28 19 16 25 34 32 22 40 51 45 42 41 25 40 30 36 49 55 51 42 57 54 36 15 14 44 56 40 56
15 27 47 26 17 27 54 19 18 35 34 48 30 14 50 44 38 51 46 49 10 41 52 55 18 30 27 25 56 55
48 33 27 51 35 38 50 39 50 44 57 38 56 24 21 53 27 30 42 24 56 59 22 17 12 24 56 38 20 38
33 29 49 59 41 52 12 44 22 38 35 45 27 37 47 59 56 52 12 59 41 14 11 45 46 20 13 22 54 51
11 53 15 42 48 50 47 32 52 27 50 54 23 11 13 56 35 25 41 59 18 48 18 24 26 14 48 22 41 27
24 26 31 31 37 29 27 52 40 40 35 56 27 13 56 45 44 26 28 58 56 54 29 26 19 17 42 39 19 12
59 17 55 17 52 14 36 31 56 53 46 34 25 55 59 56 16 28 16 55 24 22 32 20 24 16 46 50 37 29
27 52 29 26 28 12 50 41 34 29 54 52 47 33 17 55 18 42 26 16 31 23 21 17 17 36 34 56 19 38
32 34 40 33 22 10 47 32 18 44 26 55 48 43 44 44 37 24 20 40 34 29 48 45 38 18 56 49 33 35
17 47 54 19 38 24 58 46 48 37 39 10 11 47 17 53 15 19 38 50 10 54 29 25 23 16 30 32 49 29
32 42 39 36 27 18 16 49 42 39 50 40 20 56 44 29 17 49 21 50 30 22 20 54 49 24 46 17 11 45
58 22 48 45 25 18 15 38 11 31 28 59 56 49 27 53 10 12 51 17 30 14 24 17 22 11 30 28 42 24
26 31 33 28 16 40 59 34 31 37 43 45 59 43 40 44 19 16 31 48 32 20 22 43 36 33 54 29 49 37
34 31 25 13 13 20 27 49 44 46 21 38 50 35 20 40 53 54 36 26 41 43 37 21 58 55 50 12 31 16
50 25 57 59 47 14 29 20 46 27 16 17 47 14 44 23 19 53 50 40 10 35 33 31 50 39 12 57 37 52
当你有了这个文件后,需要求每一行用空格间隔开的数字的总和,还有所有行数字加起来的总和。
MapReduce计算需要三个类。
第一个类:
Mapper 继承 org.apache.hadoop.mapreduce.Mapper
第二个类:
Reducer 继承 org.apache.hadoop.mapreduce.Reducer
第三个类:
Runner 或 Driver (启动类)继承org.apache.hadoop.conf.Configured
实现org.apache.hadoop.util.Tool接口。
先把各个类的代码贴上来,然后逐个详细地讲解它们的作用。
认真看注释,反复看个几次,上下文结合,最好能自己跑一遍代码。
需要注意的是,要导入正确的包。
WordCountDriver.java
package demo01;
//注意观察这些包名,不能导错包
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
//Driver类 继承Configured类 实现Tool接口
public class WordCountDriver extends Configured implements Tool {
//实现Tool接口就必须重写一个run方法。
@Override
public int run(String[] args) throws Exception {
//1.实例化job
Job job = Job.getInstance(new Configuration(),"countNumbers");
//job就是一个工作对象、也可以理解为计算任务。他是代表一个大的计算任务。
//2.读取
//设置job读取的数据类型,因为我们是读取的.txt文本文件,所以使用TextInputFormat
job.setInputFormatClass(TextInputFormat.class);
//设置要读取的文件位置在哪里,是一个Path对象,注意包要导对
TextInputFormat.addInputPath(job,new Path("E:\SumData.txt"));
//3.map
//map将数据进行拆分,在这一步,就能完成计算,具体的计算定义在WordCountMapper类中
//所以这里要设置这个job的mapper类
job.setMapperClass(WordCountMapper.class);
//然后要设置这个mapper输出的数据类型
//map的输出是<keys,values>类型的
//也就是键值对类型,不过这个键值对左右都是列表或数组
//设置输出的key的类型为文本类型的列表
//为什么不是String?因为hadoop有自己的一套数据类型,往下看,已经总结了。
job.setMapOutputKeyClass(Text.class);
//设置输出的value类型为长整数类型的列表
job.setMapOutputValueClass(LongWritable.class);
//4.reduce
//reduce做数据合并,一般会对计算的结果进行汇总,整理。
//reduce发生在reducer类中,这里指定reducer类是哪一个
job.setReducerClass(WordCountReducer.class);
//reduce输出的也是键值对<key,values>,但是key是单个的,values是列表
//设置reduce输出的key的类型为文本型,注意,这个key不是列表了,而是单个对象了。
job.setOutputKeyClass(Text.class);
//设置reduce输出的values的类型为长整数
job.setOutputValueClass(LongWritable.class);
//5.输出
//设置计算结果输出的数据的数据类型,这里要写到文件里,所以是TextOutputFormat
job.setOutputFormatClass(TextOutputFormat.class);
//设置输出到哪里,只能设置为目录,而且这个目录不能存在。
//hadoop设计好的,为了防止覆盖,这个目录必须不能存在,不然就报错
TextOutputFormat.setOutputPath(job,new Path("e:\mapReduceResult01"));
//6.等待返回
//判断计算是否完成?完成就返回0(正常返回),没完成就返回1(异常返回)
return job.waitForCompletion(true)?0:1;
}
//写个主方法运行这个Driver类,固定格式记住就行
public static void main(String[] args) throws Exception {
ToolRunner.run(new WordCountDriver(),args);
}
}
WordCountMapper.java
package demo01;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//mapper类继承了Mapper,同时也要实现泛型
//前两个是输入的key和value的类型
//后两个是输出的keys和values的类型
public class WordCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
//定义一个变量,算当前为止总的和,这个变量的值线程锁定的,同一时间hadoop只会有一个map访问它,保证了计算的准确性
static long finalSum = 0;
//map是分布式运行的(分发到不同的节点上),计算的顺序会被打乱,不是从0到100,而是100拆分为几个块,同时计算
//谁先计算完,谁就丢给reduce,所以reduce接收到的数据是乱序的。
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//map每次读取一行数据,进行操作
//key 是偏移量(这一行第一个字符,到文本最开始的0的位置中间隔着的字符数) value 是这一行的内容
//获取这一行的长度,为了去除空行,空行的长度为0
int length = value.getLength();
//输出看一看这一行的长度,测试用
//System.out.println("这一行的长度"+length);
//sum是单行的和,finalSum是所有数字的和,不要混淆
//map是逐行运算,所以sum每次都会被初始化为0,然后计算这一行的和
//用long是因为大数据,突出一个大字,所以用long
long sum = 0;
//长度不为0,说明有数字,说明要计算和了
if (length != 0){
//保险起见,再初始化一次
sum = 0;
//因为数字之间都是用空格间隔开,所以用空格分隔成一个个的文本类型的数字
String[] values = value.toString().split(" ");
//遍历,每一个number都是文本格式的数字
for (String number : values) {
//输出看一下
//System.out.println(number);
//防止数据错误出现空指针异常(大数据不在乎一两条数据是否为空)
//大数据追求大体方向,而不追求精确
//因为大数据拿到的不是抽样数据,而是总体数据,所以一些损耗可以忽略。
if (number!= null){
//给sum一加
sum += Integer.parseInt(number);
}
}
//遍历完,sum也求出来了,sum就是这一行的和,我们把它加到总的和上面去
finalSum += sum;
//输出看一下
System.out.println(sum);
//context.write()有俩参数,分别对应你继承Mapper时,填入的后两个数据类型
//不能直接写String类型和long类型,必须用new Text("")类似这样的,进行一个转化
//转化成hadoop支持的数据类型才能往下写
//context.write是写到reduce里,也就是reduce接收的是mapper写出的数据
context.write(new Text("当前行偏移量:"+key.toString()+" 当前所有行值的总和:"+finalSum + " 当前行总和:"),new LongWritable(sum));
}
}
}
WordCountReducer.java
package demo01;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//这里的4个泛型,前两个是接收Mapper输出的类型,所以刚才Mapper的context.write()输出了什么类型
//你这里就得写什么类型,不然就会报错,后两个就是你Reducer要输出的类型
//因为你要把它写到文件里,虽然有Text就够了,不过形式主义要求,所以加个LongWritable
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//reduce接收到所有的数据后才会运行
//这时候你可以遍历输出看一下接收到了什么。
System.out.println("Reducer key : "+key);
for (LongWritable value : values) {
System.out.println("Reducer value : "+value);
//reduce计算后输出
context.write(key,value);
}
}
}
运行结果如下,注意,结合代码仔细观察运行结果,可以让你对运算过程理解更深刻:
建议亲自跑一下代码,复制粘贴,运行,5分钟就能搞定,如果你没接触过,理解计算过程需要至少10分钟,所以一定要亲自跑一遍。
INFO - session.id is deprecated. Instead, use dfs.metrics.session-id
INFO - Initializing JVM Metrics with processName=JobTracker, sessionId=
WARN - Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
WARN - No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
INFO - Total input paths to process : 1
INFO - OutputCommitter set in config null
INFO - Running job: job_local1478462730_0001
INFO - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
INFO - Waiting for map tasks
INFO - Starting task: attempt_local1478462730_0001_m_000000_0
WARN - Group org.apache.hadoop.mapred.Task$Counter is deprecated. Use org.apache.hadoop.mapreduce.TaskCounter instead
INFO - Using ResourceCalculatorPlugin : null
INFO - Processing split: file:/E:/SumData.txt:0+9300
INFO - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
INFO - io.sort.mb = 100
INFO - data buffer = 79691776/99614720
INFO - record buffer = 262144/327680
1046
1078
984
1147
992
1075
1117
1069
1090
921
…………
…………
…………//太多了,省略一下
…………
984
1034
915
1078
1039
1053
INFO -
INFO - Starting flush of map output
INFO - Finished spill 0
INFO - Task:attempt_local1478462730_0001_m_000000_0 is done. And is in the process of commiting
INFO -
INFO - Task 'attempt_local1478462730_0001_m_000000_0' done.
INFO - Finishing task: attempt_local1478462730_0001_m_000000_0
INFO - Map task executor complete.
WARN - Group org.apache.hadoop.mapred.Task$Counter is deprecated. Use org.apache.hadoop.mapreduce.TaskCounter instead
INFO - Using ResourceCalculatorPlugin : null
INFO -
INFO - Merging 1 sorted segments
INFO - Down to the last merge-pass, with 1 segments left of total size: 9083 bytes
INFO -
Reducer key : 当前行偏移量:0 当前所有行值的总和:1046 当前行总和:
Reducer value : 1046
Reducer key : 当前行偏移量:1023 当前所有行值的总和:12505 当前行总和:
Reducer value : 1078
Reducer key : 当前行偏移量:1116 当前所有行值的总和:13480 当前行总和:
Reducer value : 975
Reducer key : 当前行偏移量:1209 当前所有行值的总和:14484 当前行总和:
Reducer value : 1004
Reducer key : 当前行偏移量:1302 当前所有行值的总和:15456 当前行总和:
Reducer value : 972
Reducer key : 当前行偏移量:1395 当前所有行值的总和:16610 当前行总和:
Reducer value : 1154
…………
…………
…………//太多了,省略一下
…………
Reducer value : 915
Reducer key : 当前行偏移量:9021 当前所有行值的总和:101505 当前行总和:
Reducer value : 1078
Reducer key : 当前行偏移量:9114 当前所有行值的总和:102544 当前行总和:
Reducer value : 1039
Reducer key : 当前行偏移量:9207 当前所有行值的总和:103597 当前行总和:
Reducer value : 1053
Reducer key : 当前行偏移量:93 当前所有行值的总和:2124 当前行总和:
Reducer value : 1078
Reducer key : 当前行偏移量:930 当前所有行值的总和:11427 当前行总和:
Reducer value : 908
INFO - Task:attempt_local1478462730_0001_r_000000_0 is done. And is in the process of commiting
INFO -
INFO - Task attempt_local1478462730_0001_r_000000_0 is allowed to commit now
INFO - Saved output of task 'attempt_local1478462730_0001_r_000000_0' to e:/mapReduceResult01
INFO - reduce > reduce
INFO - Task 'attempt_local1478462730_0001_r_000000_0' done.
INFO - map 100% reduce 100%
INFO - Job complete: job_local1478462730_0001
INFO - Counters: 17
INFO - File System Counters
INFO - FILE: Number of bytes read=27969
INFO - FILE: Number of bytes written=357640
INFO - FILE: Number of read operations=0
INFO - FILE: Number of large read operations=0
INFO - FILE: Number of write operations=0
INFO - Map-Reduce Framework
INFO - Map input records=200
INFO - Map output records=100
INFO - Map output bytes=8881
INFO - Input split bytes=85
INFO - Combine input records=0
INFO - Combine output records=0
INFO - Reduce input groups=100
INFO - Reduce shuffle bytes=0
INFO - Reduce input records=100
INFO - Reduce output records=0
INFO - Spilled Records=200
INFO - Total committed heap usage (bytes)=514850816
Process finished with exit code 0
运行成功后,多出了一个目录
打开看一看
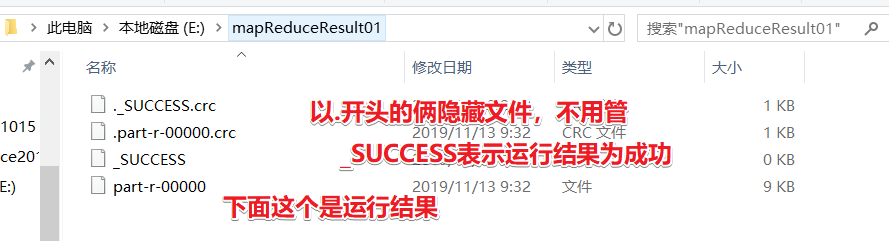
打开运行结果
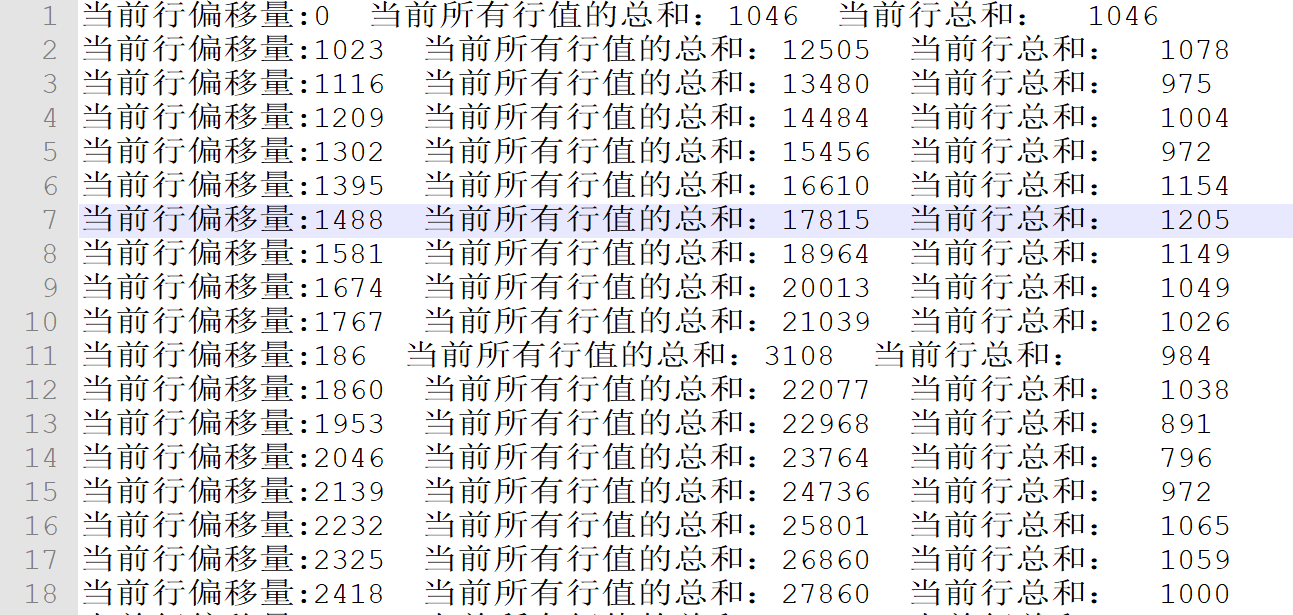
发现它们的顺序都是不规律的,这是因为map是分布式计算的,所以不会在意顺序
偏移量
每个字符移动到当前文档的最前面需要移动的字符个数。
hadoop数据类型
| java | hadoop |
|---|---|
| int | IntWritable |
| long | LongWritable |
| double | DoubleWritable |
| float | FloatWritable |
| boolean | BooleanWritable |
| String | Text |
最后
以上就是干净朋友最近收集整理的关于Java代码直观地理解MapReduce的全部内容,更多相关Java代码直观地理解MapReduce内容请搜索靠谱客的其他文章。






![[55]数据清洗、合并、转化和重构](https://www.shuijiaxian.com/files_image/reation/bcimg20.png)

发表评论 取消回复