这是中国大学MOOC中的大数据算法课程笔记
实际上Google已经宣布弃用MapReduce,但是它作为一种并行处理框架,仍然在很多地方得到了广泛的应用。还有一个重要的MapReduce实现平台,就是Hadoop平台,大家仍然可以在上面使用。
这一讲是从算法设计的角度来讲解MapReduce。
这次分为下面4个内容:
1、MapReduce概述
2、字数统计
3、平均数计算
4、单词贡献矩阵的计算
一、MapReduce概述
MapReduce是由Google公司开发的分布式编程模型,在2004年推出。这个编程模型的目的是给一些并不熟悉并行编程的程序员提供一个编程框架,使得他们可以容易地编写并行程序,运行在成百上千上万的机器集群上。
MapReduce实现了两个主要功能
Map把一个函数应用于集合中的所有成员,然后返回一个基于这个处理的结果集。
Reduce是把从两个或更多个Map中,通过多个线程、进程或者独立系统对并行执行处理的结果集进行分类和归纳。
在这个过程中,用户需要定义Map和Reduce函数
在Map过程和Reduce过程中间,需要对key/value对按key进行聚集,reduce函数被应用与每个组。
这样每个分组都是独立的,可以用分布式大规模并行的方式进行处理。
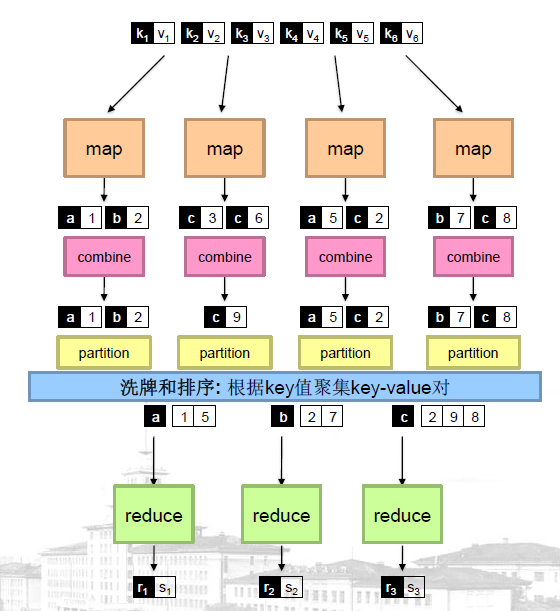
上图是MapReduce过程的示意图。其中combine操作和partition是可选的。
partition为并行reduce操作划分key空间。
combine操作是map后阶段运行的类reducer过程,把结果进行局部的聚集,用作减少网络流量的优化器。
MapReduce编程的重点是,程序员需要指定相应的Map函数和Reduce函数。
执行框架处理其他的一切:
包括调度:为map和reduce分配worker。
“数据分布”:将过程移动到数据。
同步:中间数据进行聚集,排序或洗牌。
错误处理:检测worker失败和重新启动。
程序员不需要知道的包括:
map和reduce在哪里运行,mapper和reducer何时结束等细节。
本地聚合的重要性:
Mapper和Reducer的同步需要通信,而通信会对性能造成影响,因此需要尽可能的避免通信减小开销。
所以,需要通过本地聚合减少中间数据。
二、字数统计MapReduce过程
以下是对MapReduce应用于字数统计的算法框架

“In-mapper"聚合:保持多个map调用中的状态,将combiner的功能集成到mapper中,这样避免了从mapper到combiner通过外存的I/O操作,这样需要显式的内存管理。
三、计算平均数MapReduce过程
combiner设计原则:
有时reducer可以用作combiner,但大多数情况下不行。
combiner不能改变程序的输入输出模型,只是起到聚合优化的作用。
下面是一个求平均数的MapReduce过程:

也可以采用In-Mapper形式:

四、单词共现矩阵的计算
共现矩阵的定义如下:

这个算法可以作用一种测量语义距离的方法,用于许多语言处理任务。
在对输入输出数据的处理上用两种方法来处理:词对法和条纹法。
词对法伪码:
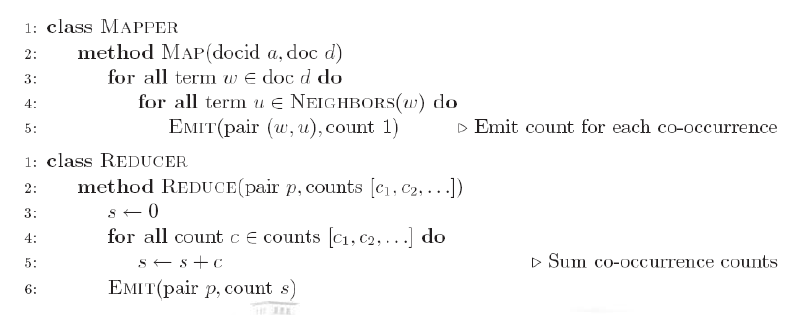
该方法的优点是易于实现、易懂;缺点是排序和洗牌代价高,combiner作用不大。
条纹法伪码:

用条纹法对key-value对的排序和洗牌少得多,能更好地利用combiner;劣势是相对更难实现,key-value对生成的对象更大。

由上述例子可以看出,我们需要对key-value数量和大小、本地聚合的形式作出权衡,使各方面的性能达到最优。
考虑的因素主要如下:

最后
以上就是热情火最近收集整理的关于基于MapReduce的并行算法设计的全部内容,更多相关基于MapReduce内容请搜索靠谱客的其他文章。








发表评论 取消回复