1.网上很多关于搭建Hadoop集群的知识,这里不多做叙述,并且本机运行Hadoop程序是不需要hdfs集群的,我们本机运行只做个demo样式,当真的需要运行大数据的时候,才需要真正的集群
2.还有就是词频统计的知识,不论是官方文档,还是网上的知识,基本都能随意百度个几百篇出来
但是我找半天,确实是没有找到对词频的结果进行全局排序的操作,实在是苦于搜索不到,我就自己瞎鼓捣一波,搞了个demo出来,还有决定不找接口了,之前一直说自己忙,没时间写blog,现在想想其实还是接口,因为永远没有那么多闲余的时间给你慢慢学学。。。
废话少聊,这里实现对结果进行排序的根本,其实也很简单,借助MapReduce本身的排序机制,我们只需要进行2次MapReduce即可
在第二次运行MapReduce的时候,我们需要调转一下key-value的顺序,就可以实现对结果数据的排序
package cn.cutter.demo.hadoop.demo; import cn.cutter.demo.hadoop.utils.ZipUtil; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.mapreduce.Counter; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob; import org.apache.hadoop.mapreduce.lib.jobcontrol.JobControl; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; import org.apache.hadoop.util.StringUtils; import java.io.*; import java.net.URI; import java.util.*; /** * @program: cutter-point * @description: 测试hadoop,新加上排序能力 * @author: xiaof * @create: 2018-11-24 20:47 * * (input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output) **/ public class WorkCount4 { /** * map类 */ public static class TokenizerMapper extends Mapper<Object, Text, NewKey1, IntWritable> { static enum CountersEnum { INPUT_WORDS } private final static IntWritable one = new IntWritable(1); private Text word = new Text(); private boolean caseSensitive; private Set<String> patternsToSkip = new HashSet<String>(); private Configuration conf; private BufferedReader fis; public void map(Object key, Text value, Mapper<Object, Text, NewKey1, IntWritable>.Context context) throws IOException, InterruptedException { String line = (caseSensitive) ? value.toString() : value.toString().toLowerCase(); for(String pattern : patternsToSkip) { line = line.replaceAll(pattern, "").replace(" ", "").trim(); } if(line.contains("Exception") || line.contains("exception")) { NewKey1 newKey1 = new NewKey1(line, 1l); context.write(newKey1, one); } } } /** * reduce类 */ public static class IntSumReducer extends Reducer<NewKey1, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(NewKey1 newKey1, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); newKey1.setSecond((long)result.get()); context.write(new Text(newKey1.getFirst()), result); } } public static class NewKey1 implements WritableComparable<NewKey1> { private String first; private Long second; public NewKey1() {} public NewKey1(String first, Long second) { this.first = first; this.second = second; } public String getFirst() { return first; } public void setFirst(String first) { this.first = first; } public Long getSecond() { return second; } public void setSecond(Long second) { this.second = second; } @Override public int compareTo(NewKey1 o) { //优先根据value进行排序 Long result = this.second - o.second; if(result != 0) return result.intValue(); else return first.compareTo(o.first); } @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.write((this.first + "n").getBytes()); dataOutput.writeLong(this.second); } @Override public void readFields(DataInput dataInput) throws IOException { this.first = dataInput.readLine(); this.second = dataInput.readLong(); } @Override public int hashCode() { return this.first.hashCode() + this.second.hashCode() + Integer.valueOf(random(6)); } @Override public boolean equals(Object obj) { if(!(obj instanceof NewKey1)) { return false; } NewKey1 newKey1 = (NewKey1) obj; return (this.first.equals(newKey1.first)) && (this.second == newKey1.second); } } public static String random(int i) { String sources = "0123456789"; Random random = new Random(); StringBuffer flag = new StringBuffer(); for(int j = 0; j < i; ++j) { flag.append(sources.charAt(random.nextInt(9))); } return flag.toString(); } public static class SortMap1 extends Mapper<Object, Text, IntWritable, Text> { @Override protected void map(Object key, Text value, Mapper<Object, Text, IntWritable, Text>.Context context) throws IOException, InterruptedException { String line = value.toString(); String words[] = line.split("t"); if(words.length == 2) { IntWritable intWritable = new IntWritable(); intWritable.set(Integer.valueOf(words[1])); context.write(intWritable, new Text(words[0])); } } } public static class SortReduce1 extends Reducer<IntWritable, Text, Text, IntWritable> { @Override protected void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException { context.write(values.iterator().next(), key); } } /** * 使用远程input目录的数据,需要用hdfs的目录,用本地目录不行 * @param args * @throws Exception */ public static void main(String[] args) throws Exception { System.setProperty("hadoop.home.dir", "F:\hadoop-2.7.7"); Configuration conf = new Configuration(); GenericOptionsParser optionsParser = new GenericOptionsParser(conf, args); // conf.set("fs.default.name", "hdfs://127.0.0.1:9000"); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WorkCount4.class); job.setMapperClass(TokenizerMapper.class); job.setMapOutputKeyClass(NewKey1.class); // job.setCombinerClass(NewKey1.class); //制定reduce类 job.setReducerClass(IntSumReducer.class); //指定输出<k3,v3>的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //先解析zip文件,并删除zip包 //H:ideaworkspace1-tmpinput H:ideaworkspace1-tmpoutput String temp[] = {"H:\ideaworkspace\1-tmp\input", "H:\ideaworkspace\1-tmp\output"}; String name = random(temp.length); args = temp; ZipUtil.unZipFilesAndDel(args[0]); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1] + name)); //job1加入控制器 ControlledJob ctrlJob1 = new ControlledJob(conf); ctrlJob1.setJob(job); //JOB2设置 Job job2 = Job.getInstance(conf, "word count2"); job2.setJarByClass(WorkCount4.class); job2.setMapperClass(SortMap1.class); job2.setMapOutputKeyClass(IntWritable.class); job2.setMapOutputValueClass(Text.class); //制定reduce类 job2.setReducerClass(SortReduce1.class); //指定输出<k3,v3>的类型 job2.setOutputKeyClass(Text.class); job2.setOutputValueClass(IntWritable.class); //job2加入控制器 ControlledJob ctrlJob2 = new ControlledJob(conf); ctrlJob2.setJob(job2); FileInputFormat.setInputPaths(job2, new Path(args[1] + name)); FileOutputFormat.setOutputPath(job2, new Path(args[1] + name + "-result")); //设置作业之间的以来关系,job2的输入以来job1的输出 ctrlJob2.addDependingJob(ctrlJob1); //设置主控制器,控制job1和job2两个作业 JobControl jobCtrl = new JobControl("myCtrl"); //添加到总的JobControl里,进行控制 jobCtrl.addJob(ctrlJob1); jobCtrl.addJob(ctrlJob2); //在线程中启动,记住一定要有这个 Thread thread = new Thread(jobCtrl); thread.start(); while (true) { if (jobCtrl.allFinished()) { System.out.println(jobCtrl.getSuccessfulJobList()); jobCtrl.stop(); break; } } // System.exit(job.waitForCompletion(true) ? 0 : 1); } }
辅助类,因为服务器上的日志都是自动压缩好的,要想进行分析,那就先要进行解压
package cn.cutter.demo.hadoop.utils; import java.io.*; import java.nio.charset.Charset; import java.util.Arrays; import java.util.Random; import java.util.zip.ZipEntry; import java.util.zip.ZipFile; import java.util.zip.ZipInputStream; /** * @ClassName ZipUtil * @Description TODO * @Author xiaof * @Date 2018/12/11 23:08 * @Version 1.0 **/ public class ZipUtil { private static byte[] ZIP_HEADER_1 = new byte[] { 80, 75, 3, 4 }; private static byte[] ZIP_HEADER_2 = new byte[] { 80, 75, 5, 6 }; /** * 解压这个目录的zip文件 * @param zipPath */ public static void unZipFilesAndDel(String zipPath) throws IOException { File file = new File(zipPath); if(file.isDirectory()) { //遍历所有文件 File files[] = file.listFiles(); for (int i = 0; i < files.length; ++i) { unZipFilesAndDel(files[i].getAbsolutePath()); } } else { if(isArchiveFile(file)) { String filename = file.getName(); unZipFile(file); file.delete(); System.out.println("完成解压:" + filename); } } } public static String random(int i) { String sources = "0123456789"; Random random = new Random(); StringBuffer flag = new StringBuffer(); for(int j = 0; j < i; ++j) { flag.append(sources.charAt(random.nextInt(9))); } return flag.toString(); } private static void unZipFile(File file) throws IOException { ZipFile zip = new ZipFile(file,Charset.forName("UTF-8"));//解决中文文件夹乱码 String name = zip.getName().substring(zip.getName().lastIndexOf('\') + 1, zip.getName().lastIndexOf('.')); BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(file)); ZipInputStream zipInputStream = new ZipInputStream(bufferedInputStream); BufferedOutputStream bufferedOutputStream = null; ZipEntry zipEntry = null; while((zipEntry = zipInputStream.getNextEntry()) != null) { String entryName = zipEntry.getName(); bufferedOutputStream = new BufferedOutputStream(new FileOutputStream(file.getParentFile() + "\" + name + random(6))); int b = 0; while((b = zipInputStream.read()) != -1) { bufferedOutputStream.write(b); } bufferedOutputStream.flush(); bufferedOutputStream.close(); } zipInputStream.close(); bufferedInputStream.close(); zip.close(); } /** * 判断文件是否为一个压缩文件 * * @param file * @return */ public static boolean isArchiveFile(File file) { if (file == null) { return false; } if (file.isDirectory()) { return false; } boolean isArchive = false; InputStream input = null; try { input = new FileInputStream(file); byte[] buffer = new byte[4]; int length = input.read(buffer, 0, 4); if (length == 4) { isArchive = (Arrays.equals(ZIP_HEADER_1, buffer)) || (Arrays.equals(ZIP_HEADER_2, buffer)); } } catch (IOException e) { e.printStackTrace(); } finally { if (input != null) { try { input.close(); } catch (IOException e) { } } } return isArchive; } public static void main(String[] args) { File file = new File("H:\ideaworkspace\1-tmp\input\111 - 副本.zip"); try { unZipFile(file); boolean res = file.delete(); System.out.println(res); } catch (IOException e) { e.printStackTrace(); } System.out.println(isArchiveFile(file)); System.out.println(file.getAbsolutePath()); } }
这里说个点,我发现自己一台电脑就单单分析20G的数据,都要跑半天,几个小时下来毛都没跑出来。。。
尴尬了,于是只能找个几十M的文件试试水
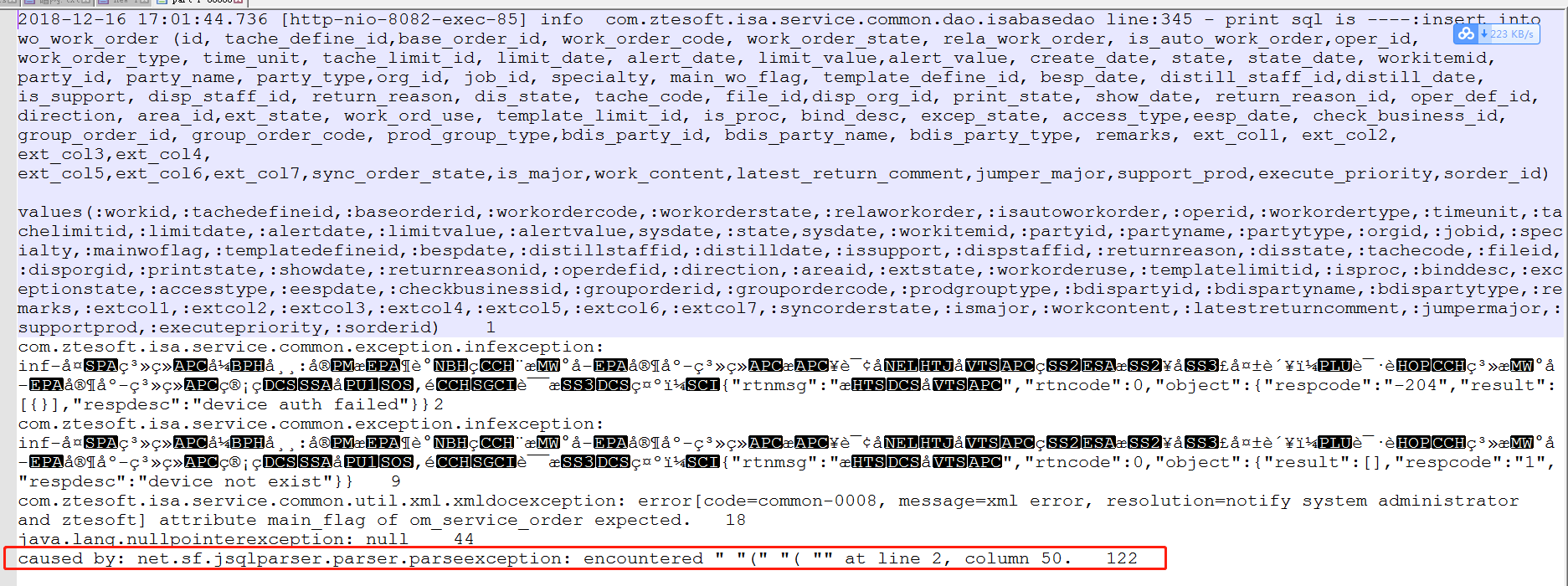
我们发现是这个地方报错非常频繁,可以从这个入手,看看是那些sql导致的,当然这个程序还有待改进,这里只能找到发生最频繁的异常,并不能分析出到底是哪个地方(当然跟记录日志的格式也有关系,这个太乱)。。。。
转载于:https://www.cnblogs.com/cutter-point/p/10128187.html
最后
以上就是冷傲草丛最近收集整理的关于【hadoop】1、MapReduce进行日志分析,并排序统计结果的全部内容,更多相关【hadoop】1、MapReduce进行日志分析内容请搜索靠谱客的其他文章。








发表评论 取消回复