调研
从网上的调研来看,其实整个百度有清洗流程的只有[1]其他都是抄的[1]中的内容。
实验流程
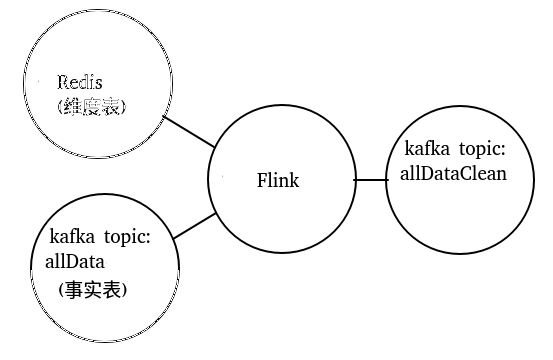
这个流程的话,不要去研究redis的Flink SQL Client的操作方法,因为在mvn repository中
没有看到flink-sql-connector-redis之类 的jar
所以该流程适可而止吧
####################################################################
Redis數據準備
127.0.0.1:6379> hset areas AREA_US US
127.0.0.1:6379> hset areas AREA_CT TW,HK
127.0.0.1:6379> hset areas AREA_IN IN
127.0.0.1:6379> hset areas AREA_AR PK,SA,KW
127.0.0.1:6379> hset areas AREA_IN IN
127.0.0.1:6379> hgetall areas
1) "AREA_US"
2) "US"
3) "AREA_CT"
4) "TW,HK"
5) "AREA_IN"
6) "IN"
7) "AREA_AR"
8) "PK,SA,KW"
本实验的redis对象是没有密码的,如果事先设置了密码,可以根据[14]去除
Redis代码中的注意事项
代码中有这么一句话:
this.jedis = new Jedis("127.0.0.1", 6379);
注意,这里的127.0.0.1如果改成redis所在节点的域名的话,必须是该redis支持外网访问,否则此处不要修改,会导致数据读取失败
####################################################################
本实验注意事项
①redis相关的jar依赖其实目前官方没有在维护了.所以不要做太深入的钻研
②需要导入flink-shaded-hadoop-3-uber-3.1.1.7.0.3.0-79-7.0.jar
Project Structure->Global Libraries中间一列导入上述的jar
否则会报错找不到hdfs这个file system
####################################################################
数据清洗目标
kafka(存放事实表)中数据示范:
{"dt":"2021-01-11 12:30:32","countryCode":"PK","data":[{"type":"s3","score":0.8,"level":"C"},{"type":"s5","score":0.1,"level":"C"}]}
格式化后如下:
{
"dt": "2021-01-11 12:30:32",
"countryCode": "PK",
"data": [
{
"type": "s3",
"score": 0.8,
"level": "C"
},
{
"type": "s5",
"score": 0.1,
"level": "C"
}
]
}这样的一条数据,根据countryCode转化为redis(存放维度表)中的具体地区AREA_AR
后面list中的数据打散,最终想要的效果如下:
{"area":"AREA_AR","dt":"2021-01-11 12:30:32","score":0.8,"level":"C","type":"s3"}
{"area":"AREA_AR","dt":"2021-01-11 12:30:32","score":0.1,"level":"C","type":"s5"}
也就是想要根据上述要求,把一条数据转化为两条数据
####################################################################
完整实验操作与代码
https://gitee.com/appleyuchi/Flink_Code/tree/master/flink清洗数据案例/FlinkProj
####################################################################
可能涉及到的Kafka操作
| 操作 | 命令 | 备注 |
| 查看topic | $KAFKA/bin/kafka-topics.sh --list --zookeeper Desktop:2181 | 无
|
| 往allData这个 topic发送 json 消息 | $KAFKA/bin/kafka-console-producer.sh --broker-list Desktop:9091 --topic allData | 这里可能碰到[2]中的报错,注意检查命令中端口与配置文件server.properties中的listeners的端口严格保持一致 [2]中的报错还可能是某个节点的kafka挂掉导致的.
可能碰到[3] 注意关闭防火墙
|
| 使用kafka自带消费端测试下消费 | $KAFKA/bin/kafka-console-consumer.sh --bootstrap-server Desktop:9091 --from-beginning --topic allData | 如果kafka自带消费者测试有问题,那么就不用继续往下面做了, 此时如果使用Flink SQL Client来消费也必然会出现问题 |
| 清除topic中所有数据[13] | $KAFKA/bin/kafka-topics.sh --zookeeper Desktop:2181 --delete --topic allData | 需要$KAFKA/config/server.properties设置 delete.topic.enable=true |
Reference:
[1]【19】Flink 实战案例开发(一):数据清洗(完整代码+数据,依赖有问题)
[2]Flink清洗Kafka数据存入MySQL测试(数据好像不太完整)
[3]Flink案例开发之数据清洗、数据报表展现(与[1]内容重复)
[4]Flink继续实践:从日志清洗到实时统计内容PV等多个指标(代码不完整)
[5]Flink清洗日志服务SLS的数据并求ACU&PCU(工程文件不完整)
下面的最后考虑(博主说是完整的.下面的实验的原始出处其实是[1])
[6]Flink入门及实战(20)- 数据清洗实时ETL(1)
[7]Flink入门及实战(21)- 数据清洗实时ETL(2)
[8]Flink入门及实战(22)- 数据清洗实时ETL(3)[10]Flink 清理过期 Checkpoint 目录的正确姿势
[11]Flink学习(二):实验一数据清洗(代码不完整,涉及到了elasticsearch)
[12]网站日志实时分析之Flink处理实时热门和PVUV统计(缺数据)
[13]Is there a way to delete all the data from a topic or delete the topic before every run?
[14]redis设置密码
最后
以上就是安静项链最近收集整理的关于Flink数据清洗(Kafka事实表+Redis维度表)的全部内容,更多相关Flink数据清洗(Kafka事实表+Redis维度表)内容请搜索靠谱客的其他文章。








发表评论 取消回复