目录
- 基本知识
- CPU分析
- 页面查看
- 实战
- 问题描述
- 分析过程
Golang提供了性能分析大杀器 pprof,主要分为两种应用场景,一种是对于脚本程序,可以通过在代码里引入性能分析库来进行分析;另外一种就是今天的重点:普通web服务型应用,启动的时候同步配置好debug端口,就可以在应用运行中,随时对其进行性能分析。
基本知识
CPU分析
查看30s内CPU的使用情况
go tool pprof http://localhost:{debugport}/debug/pprof/profile?seconds=30
执行后会自动开启一个交互的shell,可以通过输入指令的方式对采集到的结果进行分析,如
- top 查看占用的CPU
Flat表示当前函数的耗时,cum表示总和耗时(如果函数调用了其他函数,也包括其他函数的用时)
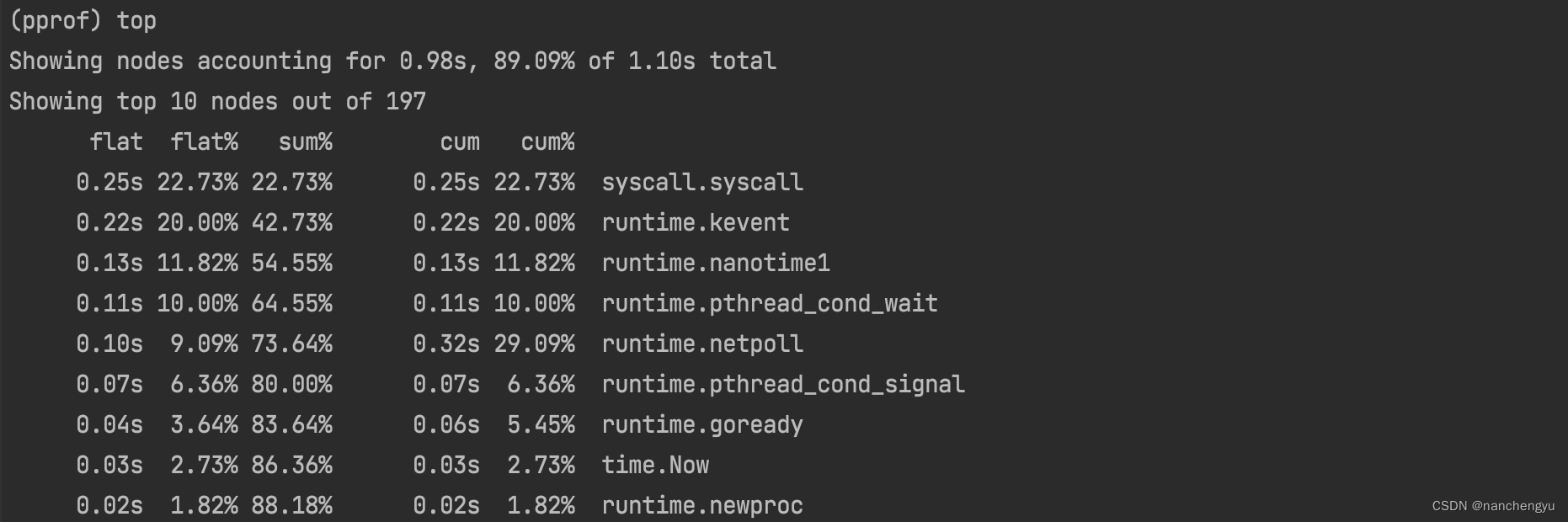
- list syscall 发现top之后,有针对性的可以看下每个函数的调用栈
- 还可以通过traces看每个采样到的函数的调用栈
页面查看
除了刚才提到的命令行交互,还可以把采样结果输入到文件里,然后通过graphviz工具查看
- 提前安装graphviz, mac可以这样执行
brew install graphviz
- 生成采样文件
curl -sK -v http://localhost:{debugport}/debug/pprof/profie> profile.out
- 进行页面展示
go tool pprof -http=:8080 profile.out
实战
问题描述
某个接口依赖多次对下游同一个接口的调用拼装
为了减少接口返回时间,并发请求了下游的某个接口,但返回时间非常长
已知下游没有性能问题
分析过程
- 首先常规查看profile和goroutine
首先看到有大量的goroutine,并且都阻塞在/runtime/proc.go中,调用栈如下
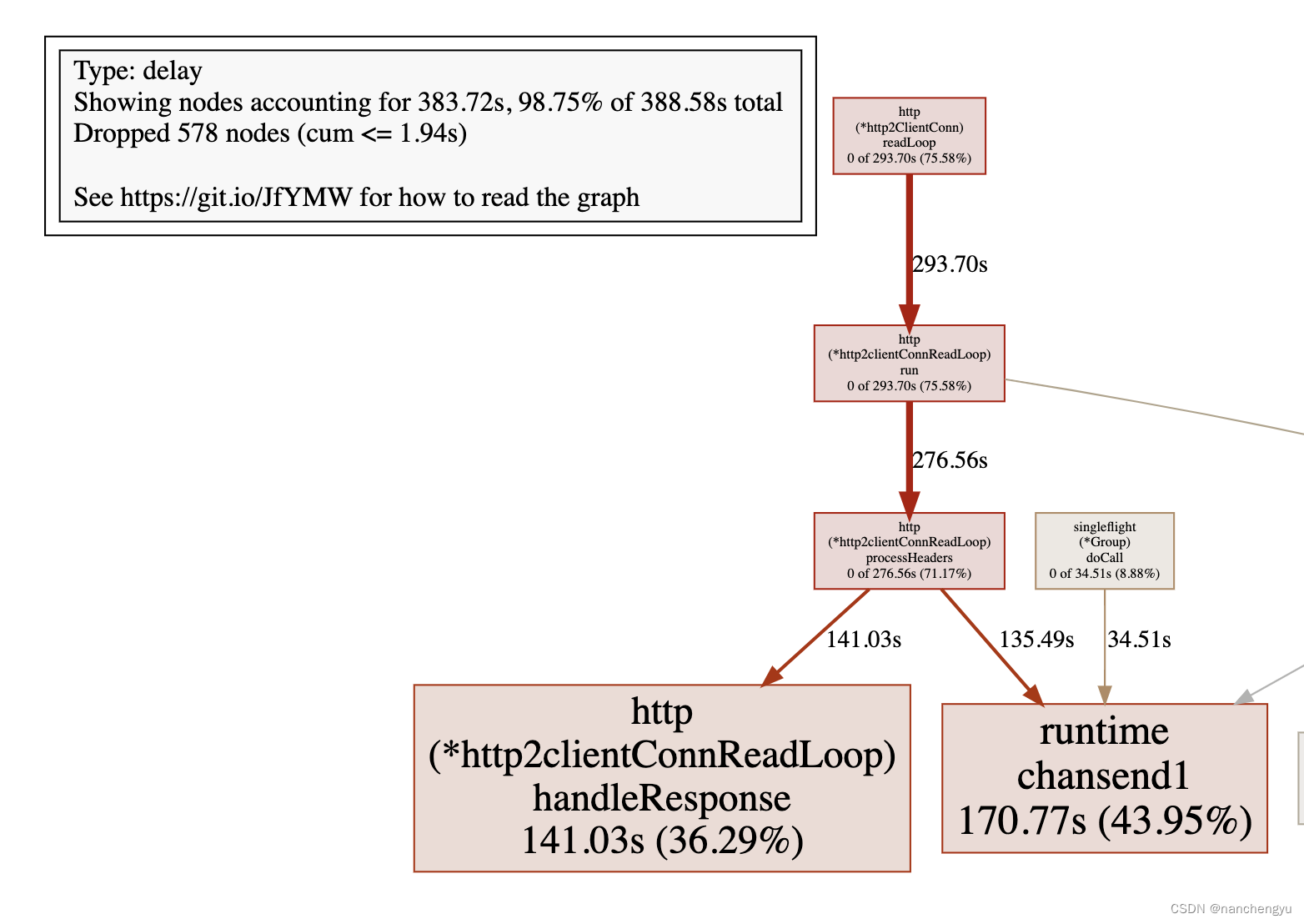
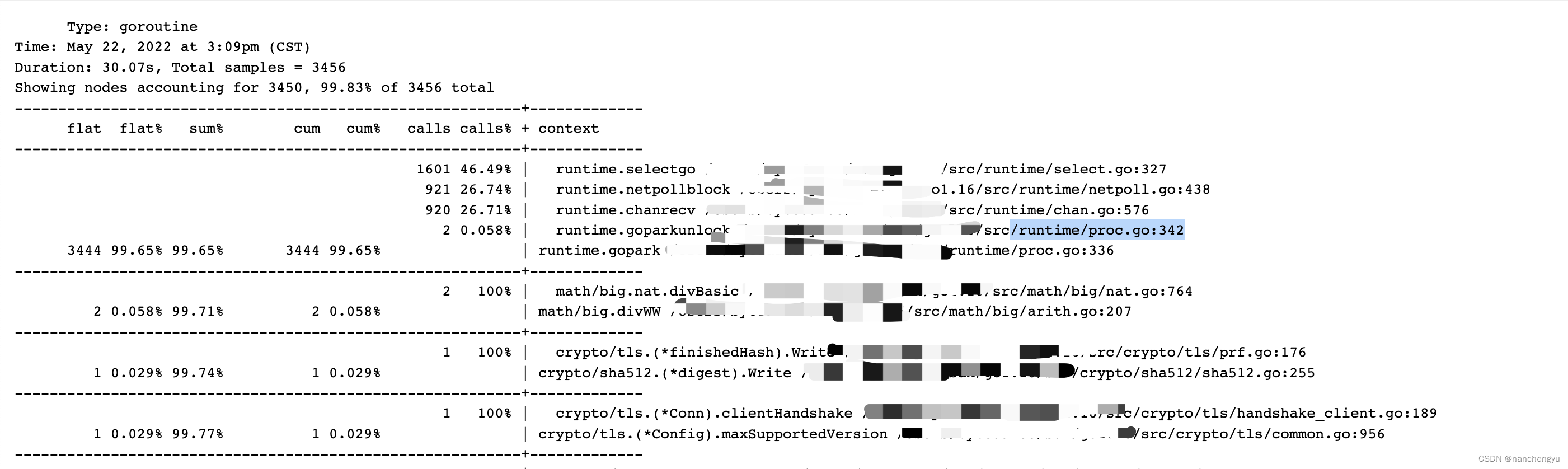 根据数据,其实并发数只有700左右,但却产生了3000+goroutine,很奇怪,再具体看下graph
根据数据,其实并发数只有700左右,但却产生了3000+goroutine,很奇怪,再具体看下graph
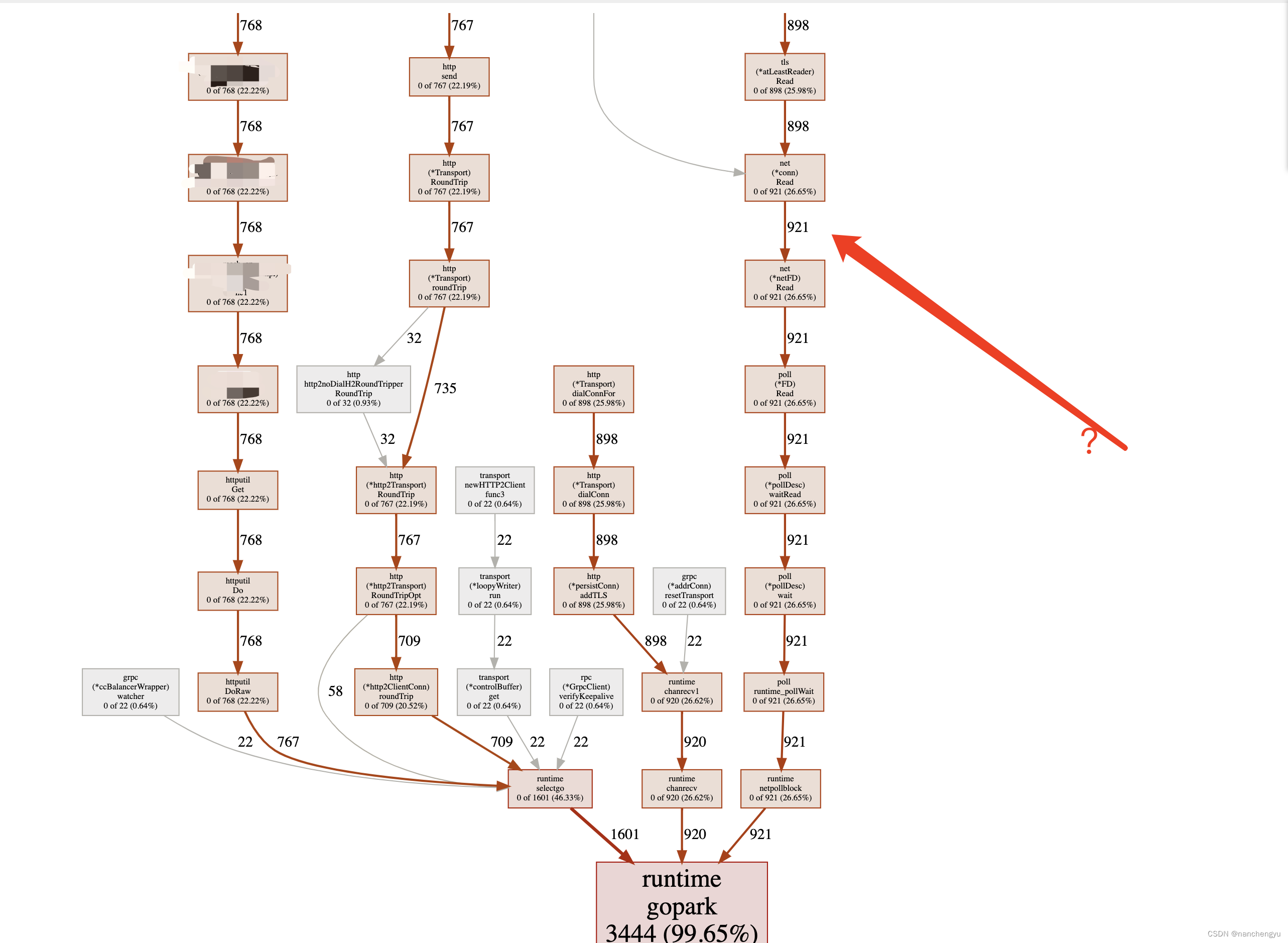 看上图,确实业务逻辑只有700+线程(图的左方),其中由于依赖的底层http库用了异步,会额外多一倍,但仍然看出来图中有一群,不知道哪儿来的线程(箭头所示),数量大概在3400-768*2,大概占一半。这些线程看起来都和http包相关
看上图,确实业务逻辑只有700+线程(图的左方),其中由于依赖的底层http库用了异步,会额外多一倍,但仍然看出来图中有一群,不知道哪儿来的线程(箭头所示),数量大概在3400-768*2,大概占一半。这些线程看起来都和http包相关
线条的样式代表了调用关系。实线代表直接调用;虚线代表中间少了几个节点。
- 较粗的边线代表该路径下使用了更多的资源
- 较细的边线代表该路径下使用了较少的资源
- 新的杀器 trace
curl -sK -v http://localhost:{debugport}/debug/pprof/trace?seconds=30 > trace.out
go tool trace trace.out
可以看到如下的页面
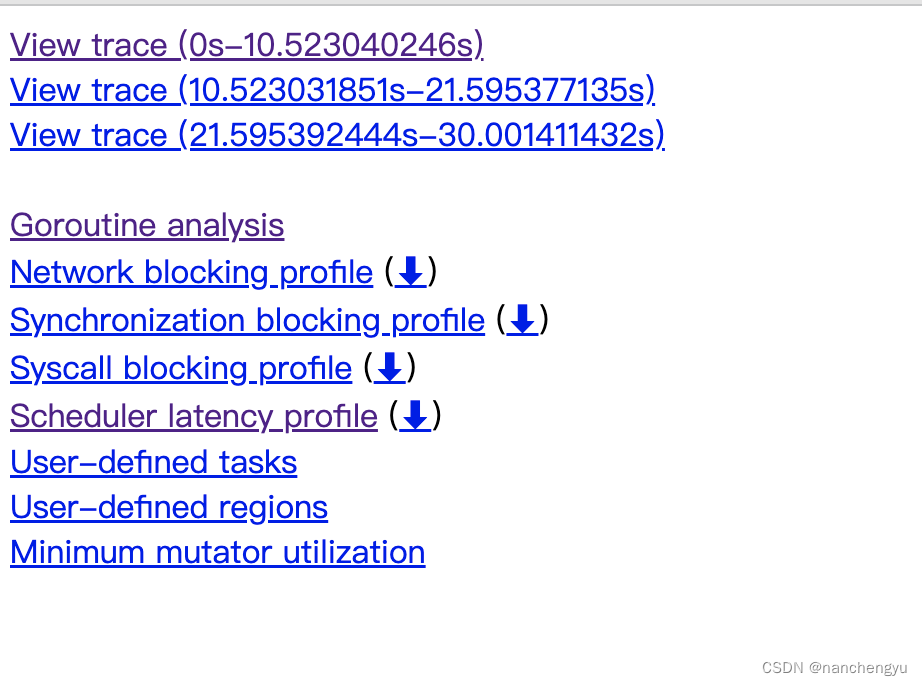
一般先看 Scheduler latency profile 得出一个整体的情况,看到主要消耗都在读取和发送数据
然后看Goroutine analysis,找到自己关心的线程
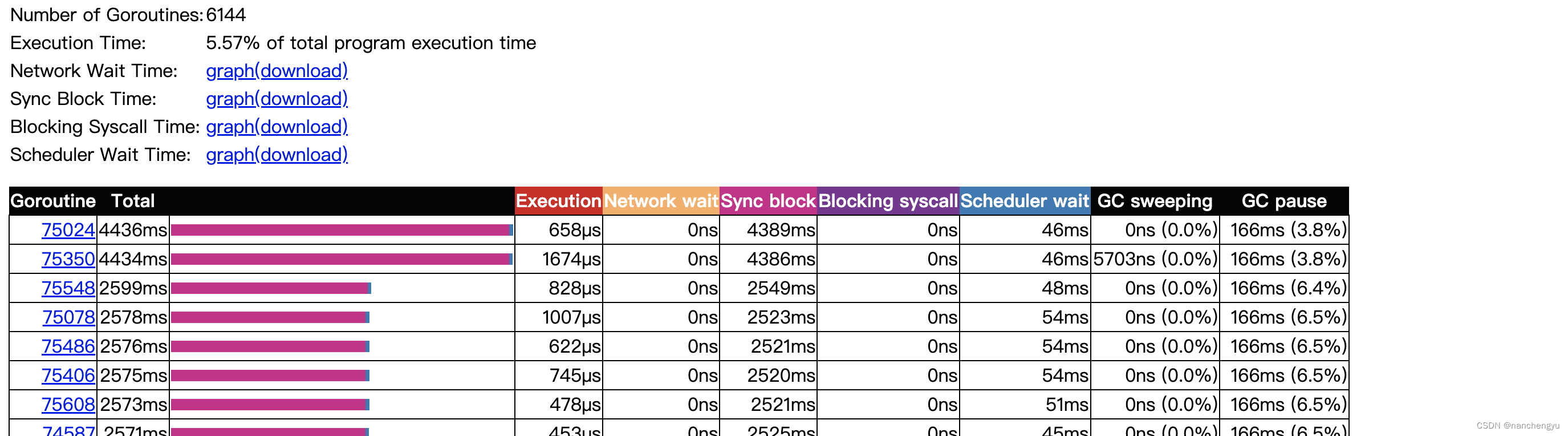
可以发现其实execution执行时间差别很大,然后网络等待时间都是0,同步阻塞时间很大,有些甚至到四秒多,基本可以锁定接口很慢是因为这个东西
然后看刚才的tls的线程,可以发现大部分的消耗是在等网络
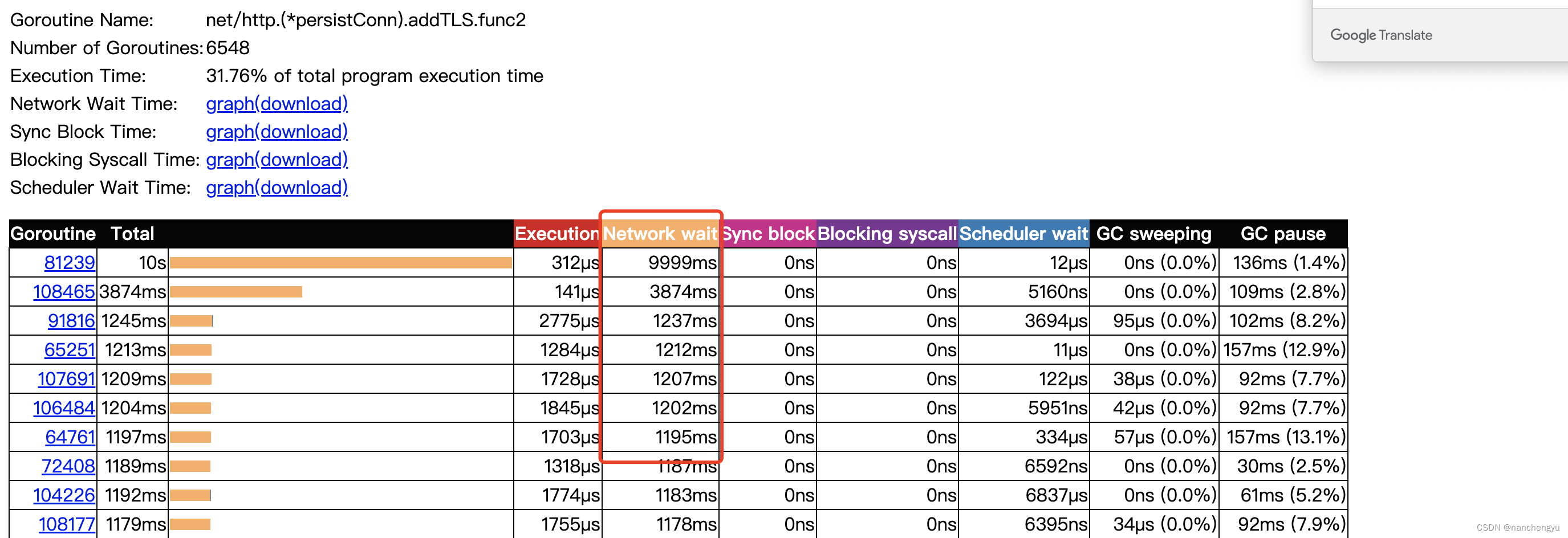
看一下addTLS的调用栈
RoundTripOpt -> GetClientConn->getClientConn->dialClientConn->
roundTrip->getConn->queueForDial->dialConnFor->dialConn->Handshake
第二条线就是握手线程的来源,也就是当链接失效的时候,需要重新建立链接,因为我们用的httpclient没有缓存链接,每次请求都需要重新建立链接,卡在select上
最终调整了并发数量,为10,解决了问题。
最后
以上就是鳗鱼芒果最近收集整理的关于Golang pprof的使用+一个性能调优的小例子基本知识实战的全部内容,更多相关Golang内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复