文章目录
- 面试技巧篇
- 面试基础
- 简历内容
- 自我介绍
- Python语言篇
- 列表和字典
- Python2/3
- 函数参数
- 异常机制
- 性能分析
- 生成器
- 单元测试
- 深拷贝
- 小结
- 这部分主要针对Python服务端面试和职业规划
- 后端知识是非常繁杂的,编程语言、数据库、算法、网络、架构等
- 当然,遇到菜的前端都得你自己写,写脚本、怼产品啥的就不用说了
- 基础主要分以下几篇:
- 面试技巧
- Python语言
- 算法和数据结构
- 编程范式篇
- 操作系统篇
面试技巧篇
- 得先有人面试你,去拉钩或者BOSS打听打听
- 岗位职责
- 职位要求
- 公司技术栈
- 字节和知乎用Python多,随便截个招聘看看吧:

- 看看上面的技术点你熟悉哪些?查漏补缺,针对不同公司技术栈编写不同简历(很真实)
- 如果你是应届,公司更关注的是你的学习能力和基础能力,工具的使用谁不能学呢?
- 平台决定成长,大公司体量大,遇到的问题多,成长快!
面试基础
- 应届问基础,社招看项目
- 一面问基础、二面问项目、三面问设计(高工)
- 目前,我个人是应届生,也面试过几次,基础知识这东西一定要经 常 回 顾
- 你别告诉我你懂了,你得能讲清楚,学第三遍的时候你有可能会发现第一遍的理解是错的,狭隘了、草率了!
- 要注重软实力,比如面试时先来个自我介绍,这在考察表达能力,平时可以组织好一个模板;沟通在开发过程中是很重要的,你需求都表达不清楚也太难顶了吧
- 总览一下Python技术栈
- 回答:你了解的Python后端技术栈都有哪些?
- 我们可以从web请求流程入手,侃侃而谈:

- 后面我们会先从基础部分开始,再按照上面的流程打牢技术栈,完美回答这个问题!
- 第一阶段的目标是:初级工程师
- 初级工程师基本要求
- 扎实的计算机理论基础
- 代码规范
- 能在指导下完成需求
简历内容
- 基本信息
- 姓名、学校、学历、联系方式
- 职业技能
- 语言、框架、数据库、开发工具等
- 关键项目经验
- 遇到的问题、技术难点等
- 自我评价
- 真诚为好,别吹别哭
- 简历加分项:
- 知名项目经验
- 技术栈匹配
- 开源项目(github、blog经常更新)
- 博客可以写读书笔记,技术总结
- 避坑:
- 内容精简、突出重点
- 注意格式:模板+PDF
- 信息真实不作假、无关内容少一些
自我介绍
-
主要内容
- 个人信息
- 掌握的技术,参与的项目
- 应聘岗位的看法和兴趣
-
行为面试技巧
- 行为面试:面对相似场景时人会倾向于重复过去的行为模式
- 评判语言表达、沟通、抗压能力
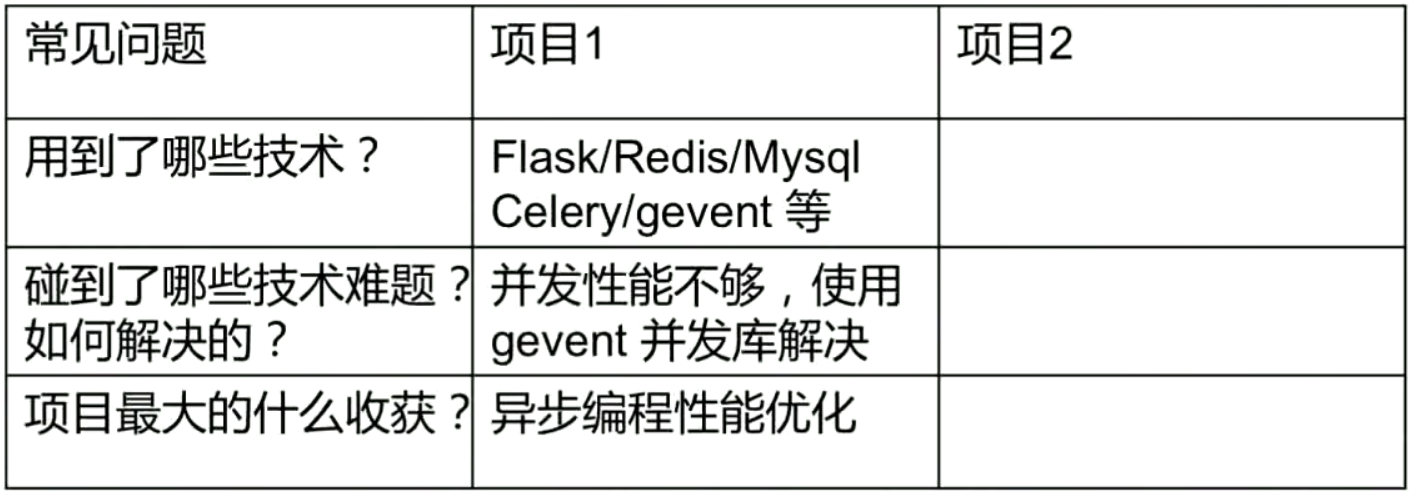
- 提问:说说你简历中的这个项目,回答可从四个方面:
层次 含义 情景 什么情况下发生的 任务 你是如何明确任务的,团队如何分工 行动 你做了哪些事情 结果 结果如何,带来了什么收获 - 伴随着还会有一些问题:建议自问自答自嗨,组织个表格:
- 最后一般都会问:你有啥要问我的吗?(这个必须有) ,我们要表现出兴趣
- 问工作内容(每天干嘛)
- 问公司技术栈
- 问团队结构(能不能开心工作学习)
- 问项目、业务(公司实力)
- 我好像以前都说没了,简直了,不能复吸…
-
面试技巧篇因为本人经历有限,不能吹不能黑,还是靠实践,最后摆出一道题目吧:
讲讲你觉得最有技术含量的项目(如果你项目太多只能这样)
Python语言篇
- Python是动态强类型语言
- 运行期确定数据类型(可以不指明类型,写代码爽)
- 不会发生隐式类型转换(是int不会变成str)
- 关于类型,有种说法叫鸭子类型
- 我们只关注功能,例如定义两个类,都实现同一功能(鸭子叫)
- 各类的对象自然是属于不同类型,但重要吗?鸭子能叫人也能叫
- 关于动态有两个概念
monkey patch- 即运行时替换
- 例如gevent库需要修改内置的socket
- 自省
- 既然动态了,就要有运行时判断对象类型的能力
- python一切皆对象,可以用
type/id/isinstance函数判断
ilist = [1,2,3] idict = dict(a=1) print(type(ilist)) # <class 'list'> print(type(idict)) # <class 'dict'> print(isinstance(ilist, list)) # True print(id(idict)) # 1715274125376 内存地址 # 当使用is判断的时候,比较的就是地址值 mlist = [1,2,3] ilist == mlist ilist is mlist # False - 注意,Python是有int/float/bool这些类型的,你想强就强(能避免火葬场?)
- 另外,Python轮子多,应用广泛,语言灵活,生产力高
列表和字典
- 列表推导(List Comprehension)
l = [i for i in range(10)] # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] l2 = (i for i in range(10)) # 现在是个生成器 <class 'generator'> for i in l2:print(i) # 生成器推导可以节省内存 - 字典推导
ilist = [1,2,3] mlist = ['a','b','c'] d = {k:v for k,v in zip(a,b)} # 优雅! - 动态语言的维护性较差,这更要求我们严格约束自己的编码风格
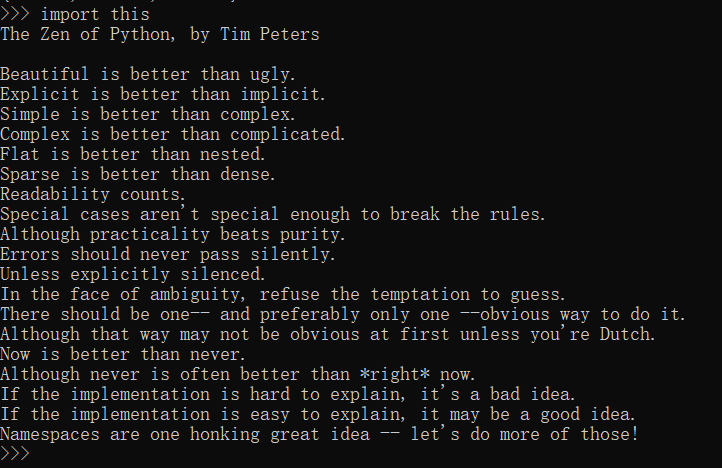
- 图为Python重要开发者Tim Peters提出的一些规范,也叫“Python之禅”
Python2/3
- 有些遗留轮子不支持Python3,大致了解一下差异
- Python3的改进
print成为函数- 编码问题:3不再有Unicode对象(就是我们有时候不得不在字符串前面加个
u),默认string就是Unicode编码 - 除号返回浮点数
- 类型注解(type hint):帮助IDE实现类型检查,主要是给开发者提个醒
super()方便直接调用父类函数- 高级解包:
a, b, *c = range(10) # 也属于语法糖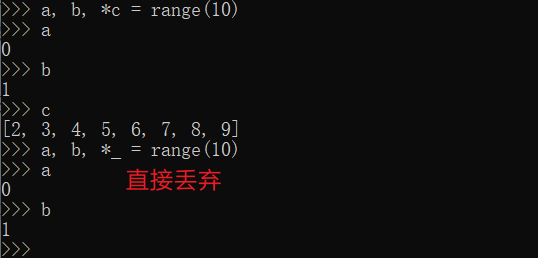
- py3高级操作
- 限定关键字参数(就是传参的时候可以指定参数名,防止搞混)
- 抛出异常时不丢失栈信息(traceback),即Chained exceptions
import shutil def test(arg1,arg2): try: shutil.copy2(arg1,arg2) except OSError: raise NotImplementedError("OSError") from OSError test("copy","copy2")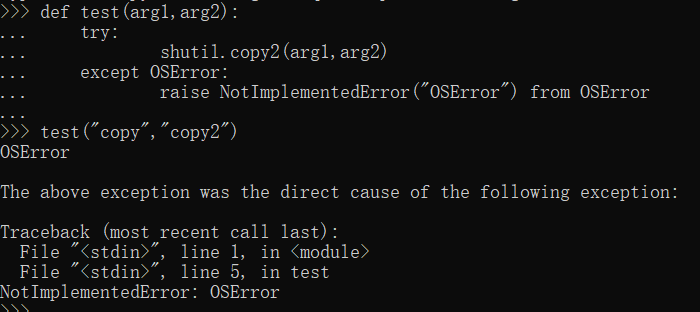
- 一切返回迭代器:
range()/zip()/dict.items()
- python3新增语法和库
- 链接子生成器
yield from - 新增内置库:
- asyncio内置库:
async/await原生协程支持异步编程 - enum、mock、ipaddress
- asyncio内置库:
- 修改内置库:
urllib/selector
- 链接子生成器
- pyc文件统一放到
__pycache__ - 兼容2/3的工具:
- six模块
- 2to3转换工具
__future__模块from __future__ import print_function,是为了在老版本中兼顾新特性的一种方法
函数参数
- 函数传参时传值还是传引用?(学了C++可能就会下意识有这个问题)
- 但是这里用的是共享传参(Call by Sharing)
- 函数形参获得实参的引用或者副本,看个代码:
def func1(mylist): # 你可能觉得这个传引用 mylist.append(3) print(mylist) def func2(mystr): # 你可能觉得这个传值 mystr += "niub" print(mystr) return mlist = [] mstr = "Roy," func1(mlist) func2(mstr)- 其实,这要看传入参数的类型,可变与不可变对象是不同的
- Python一切皆对象
- 不可变对象:
bool/int/float/tuple/str - 可变对象:
list/set/dict
- 不可变对象:
- 传递参数是通过对象引用(是的,类似C++引用,直接操作原对象那种),但!如果传的是可变对象,例如上面的func1,则会对mlist直接修改;如果传的是不可变对象,例如func2,就会将mstr拷贝一份创建新对象再操作
- 默认参数的问题
- 格式:
def 函数名(...,形参名,形参名=默认值): - 指定有默认值的形式参数必须在所有没默认值参数的最后
- 格式:
- 可变参数
*args、**kwargs- 列表/元祖参数,会将参数转换成元祖
def print_args(*args): print(type(args), args) # enumerate() 用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列 for idx, val in enumerate(args): print(idx, val) # idx是序号 print_args([1,2]) # <class 'tuple'> (1, 2) # 0 1 # 1 2 # 可以传*[1,2],结果同上 # 可以传[1,2],得到 0 [1, 2]- 关键字参数,会转换成字典
def print_kwargs(**kwargs): print(type(kwargs), kwargs) for k, v in kwargs.items(): # dict.items() 返回可遍历的(键, 值) 元组数组 print('{}:{}'.format(k, v)) # 类似的,可传 **dict('a':1, 'b':2)
异常机制
- 有的语言使用错误码,Python使用异常处理错误
- 处理异常还是继承基类,类级层次结构可以查看链接
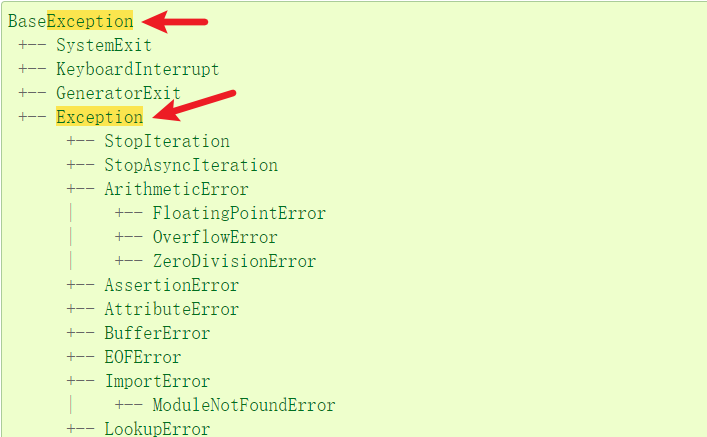
- 什么时候需要捕获处理异常?先了解内置异常类型(让python帮你了解有哪些异常场景)
- 网络请求超时、连接错误
- 资源访问不存在、权限
- 代码逻辑越界、KeyError
- 异常处理块:

# 自定义一个异常 class MyException(Exception): pass try: # 直接抛出 raise MyException("this is my customize exception") except MyException as e: # 捕获处理,这里也可以捕Exception,只有捕了父类子类的也会被捕! print(e) finally: print("over!") my_exception() - 为什么业务异常都继承Exception而不是BaseException呢?
- 因为BaseException中的KeyboardInterrupt可能会让异常处理失效
性能分析
- GIL(global interpreter lock)全局解释器锁,CPython解释器中使用
- 为啥使用锁呢?因为同一进程的线程共享内存空间,数据可能会不安全

- GIL头比较铁,直接把其他线程锁住了
- CPU密集型程序可以让多线程占用多核提高进程执行效率,这个不让同时执行字节码,伤害性极强啊~
- 当然,IO期间会释放GIL,对IO密集型影响不大
- 怎么解决呢?进程池

- 为啥使用锁呢?因为同一进程的线程共享内存空间,数据可能会不安全
- 有了GIL就一定线程安全吗?
- 原子操作才能保证线程安全,python中什么操作才是原子的?

- 学过计组就知道,这里的一个字节码指令即一个微指令(一个机器指令对应一组微指令),每个微指令对应一组微操作(水平存储)
- 不是一个字节码就不安全!
- 如何保证线程安全呢?多字节码操作处加锁!
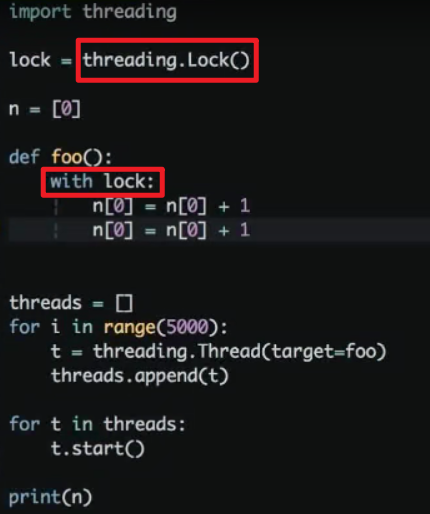
- 原子操作才能保证线程安全,python中什么操作才是原子的?
- 性能
- 使用内置或第三方profile工具(收集程序的运行信息)
- 优化
- 语言一般不会成为瓶颈
- 数据结构和算法优化
- 数据库:索引优化、消除慢查询、使用NoSQL
- 缓存:使用内存数据库Redis
- 异步任务:celery
- 并发:gevent(协程机制)
- 多线程处理IO
生成器
- 简而言之,就是可以生成值的函数,当一个函数有了
yield关键字就成了生成器 - 可以挂起执行并保持当前的状态
- 可以不断调用
next()函数获取由yield语句返回的下一个值,举个例子:def simple_gen(): yield 'hello' yield 'Roy' gen = simple_gen() print(type(gen)) print(next(gen)) # hello print(next(gen)) # Roy - Python3之前没有原生协程,只有基于生成器的协程
- 协程可理解为微线程,就是在一个线程内执行的,可内部中断的子程序,例如:
- 传统的生产者-消费者模型是一个线程写消息,一个线程取消息,通过锁机制控制队列和等待,但一不小心就可能死锁
- 改用协程,一个线程内,生产者生产消息后,直接通过yield跳转(关键就在这,可暂停执行和产出数据)到消费者开始执行,待消费者执行完毕后,切换回生产者继续生产,效率极高;参考
- 注:还支持
send()向生成器(函数)发送数据和throw()想函数抛出异常

- 即只有默认值和send值,可以理解为一个yield循环一次,n个n次

- 总是激活,太麻烦:

- func参数就是函数引用,配合语法糖使用装饰器
- Python3.5引入async/await支持原生协程:

- Python使用协程来处理高并发场景,结合Linux的epoll模型(高效IO模型,多路复用)
- 高并发处理的主要问题是IO密集,协程可以使用yield中断而非阻塞,快速切换处理,避免线程间切换降低效率
单元测试
- 针对一个函数、类进行的测试,很底层
- 三无产品不可取(无文档、无注释、无测试)
- 有些公司提倡测试驱动开发(TDD)
- 易测的代码是高内聚低耦合的,好
- 有时候会采用print查看结果,其实直接把assert写进代码就好了
- 常见的测试库:
nose/pytest和mock模块# test.py # pip install pytest def test_search(): # 必须以test开头 # 正常值 assert binary_search([1,2,3,4], 1) == 1 assert binary_search([1,2,3,4], 7) == -1 # 边界值 assert binary_search([1,2,3,4], 0) == 1 assert binary_search([1,2,3,4], -1) == 1 # 异常值 assert binary_search([], 1) == 1 # 测试取值通常分为上面三类- 执行
pytest test.py,如果是绿线证明测试通过!也可以定位错误
- 执行
深拷贝
- 有三种对象值传递的操作
- 直接赋值:其实就是对象的引用(别名),可以理解为指针
- 浅拷贝(copy):拷贝父对象,不会拷贝对内部的子对象
- 深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象
# 浅拷贝 dic = {'a': [1,2,3]} # 字典是对象,里面的列表是子对象 b = dic.copy() # 当然,咱也可导入copy,copy.copy,效果相同! dic['a'].append(4) dic,b # ({'a': [1, 2, 3, 4]}, {'a': [1, 2, 3, 4]}) # 深拷贝 import copy c = copy.deepcopy(dic) dic, c # ({'a': [1, 2, 3, 4]}, {'a': [1, 2, 3, 4]}) dic['a'].append(5) dic, c # ({'a': [1, 2, 3, 4, 5]}, {'a': [1, 2, 3, 4]}) - 小作业:Python中如何正确初始化一个二维数组?
小结
- 本篇大致介绍了面试技巧和Python语言基础,其中生成器的概念和用法、GIL的概念及优化需要清楚
- 下一篇介绍常考的数据结构和算法
最后
以上就是寒冷灯泡最近收集整理的关于Python面试篇(一)的全部内容,更多相关Python面试篇(一)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复