
本篇只是部分Python基础的面试题。

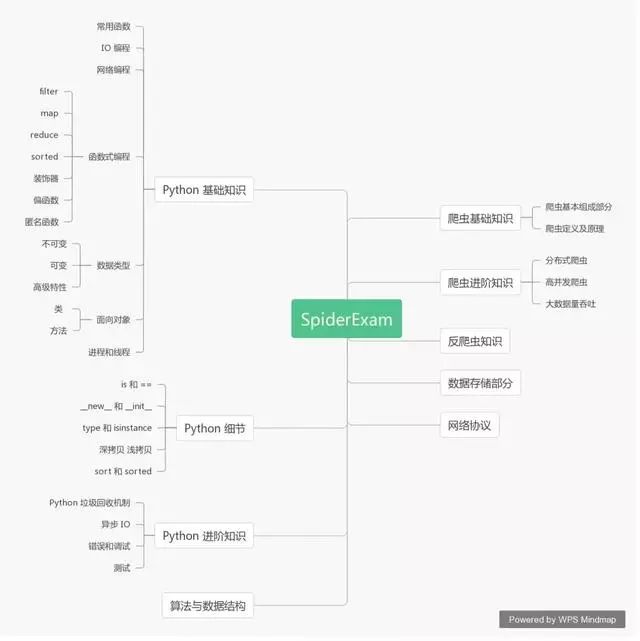
先来一份完整的爬虫工程师面试考点:
一、 Python 基本功
1、简述Python 的特点和优点
Python 是一门开源的解释性语言,相比 Java C++ 等语言,Python 具有动态特性,非常灵活。
2、Python 有哪些数据类型?
Python 有 6 种内置的数据类型,其中不可变数据类型是Number(数字), String(字符串), Tuple(元组),可变数据类型是 List(列表),Dict(字典),Set(集合)。
3、列表和元组的区别
列表和元组都是可迭代对象,能够对其进行循环、切片等,但元组 tuple 是不可变的。元组不可变的特性,使得它可以成为字典 Dict 中的键。
4、Python 是如何运行的
CPython:
Python 程序运行时,会先进行编译,将 .py 文件中的代码编译成字节码(byte code),编译结果储存在内存的 PyCodeObject 中,然后由 Python 虚拟机解释运行。当程序运行结束后,Python 解释器会将 PyCodeObject 保存到 pyc 文件中。每一次运行时 Python 都会先寻找与文件同名的 pyc 文件,如果 pyc 存在则比对修改记录,根据修改记录决定直接运行或再次编译后运行,最后生成 pyc 文件 。
5、Python 运行速度慢的原因
a). Python 不是强类型的语言,所以解释器运行时遇到变量以及数据类型转换、比较操作、引用变量时都需要检查其数据类型。
b). Python 的编译器启动速度比 JAVA 快,但几乎每次都要启动编译。
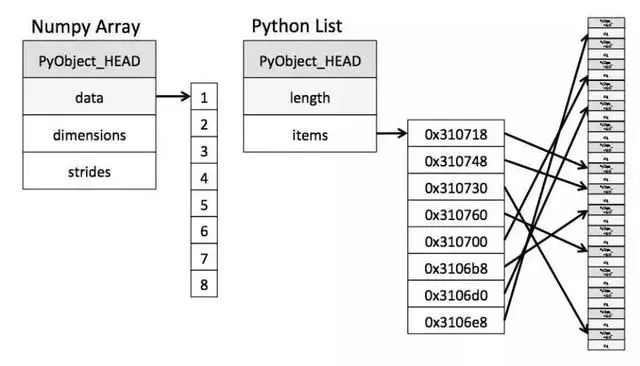
c). Python 的对象模型会导致访问内存效率变低。Numpy 的指针指向缓存区数据的值,而 Python 的指针指向缓存对象,再通过缓存对象指向数据:
6、面对 Python 慢的问题,有什么解决办法
a). 可以使用其他的解释器,比如 PyPy 和 Jython 等。
b). 如果对性能要求较高且静态类型变量较多的应用程序,可以使用 CPython。
c). 对于 IO 操作多的应用程序,Python 提供 asyncio 模块提高异步能力。
7、描述一下全局解释器锁 GIL
每个线程在执行时候都需要先获取 GIL,保证同一时刻只有一个线程可以执行代码,即同一时刻只有一个线程使用 CPU,也就是说多线程并不是真正意义上的同时执行。但是在 IO 操作时,是可以释放锁的(这也是 Python 能够异步的原因)。而且如果想要利用多核 CPU,那么可以使用多进程。
8、深拷贝 浅拷贝
深拷贝是将对象本身复制给另一个对象,浅拷贝则是将对象的引用复制给另一个对象。所以当复制后的对象改变时,深拷贝的原对象值不会改变,而浅拷贝原对象的值会被改变。
9、is 和 == 的区别
is 表示的是对象标示符(object identity),而 == 表示的是相等(equality)。
is 的作用是用来检查对象的标示符是否一致,也就是比较两个对象在内存中的地址是否一样,而 == 是用来检查两个对象是否相等。但是为了提高系统性能,对于较小的字符串 Python 会保留其值的一个副本,当创建新的字符串的时候直接指向该副本即可。如:
a = 8 b = 8 a is b
10、文件读写
简述文件读取时 read 、readline、readlines 的区别和作用
他们的区别除了读取内容范围不同外,返回的内容类型也不同。
read()会读取整个文件,将读取到底的文件内容放到一个字符串变量,返回 str 类型。
readline()读取一行内容,放到一个字符串变量,返回 str 类型。
readlines() 读取文件所有内容,按行为单位放到一个列表中,返回 list 类型。
11、请用一行代码实现
请分别使用匿名函数和推导式这两种方式将 [0, 1, 2, 3, 4, 5] 中的元素求乘积,并打印输出元组。
print(tuple(map(lambda x: x * x, [0, 1, 2, 3, 4, 5]))) print(tuple(i*i for i in [0, 1, 2, 3, 4, 5]))
12、请用一行代码实现
用 reduce 计算 n 的阶乘(n!=1×2×3×...×n)
print(reduce(lambda x, y: x*y, range(1, n)))
13、请用一行代码实现
筛选并打印输出 100 以内能被 3 整除的数的集合
print(set(filter(lambda n: n % 3 == 0, range(1, 100))))
14、请用一行代码实现
text = 'Obj{"Name": "pic", "data": [{"name": "async", "number": 9, "price": "$3500"}, {"name": "Wade", "number": 3, "price": "$5500"}], "Team": "Hot"'
打印文本中的球员身价元组,如 ($3500, $5500)
print(tuple(i.get("price") for i in json.loads(re.search(r'[(.*)]', text).group(0))))
15、请写出递归的基本骨架
def recursions(n): if n == 1: # 退出条件 return 1 # 继续递归 return n * recursions(n - 1)
16、切片
请写出下方输出结果
tpl = [0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95] print(tpl[3:]) print(tpl[:3]) print(tpl[::5]) print(tpl[-3]) print(tpl[3]) print(tpl[::-5]) print(tpl[:]) del tpl[3:] print(tpl) print(tpl.pop()) tpl.insert(3, 3) print(tpl)
[15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95] [0, 5, 10] [0, 25, 50, 75] 85 15 [95, 70, 45, 20] [0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95] [0, 5, 10] 10 [0, 5, 3]
17、文件路径
打印输出当前文件所在目录路径
import os print(os.path.dirname(os.path.abspath(__file__)))
打印输出当前文件路径
import os print(os.path.abspath(__file__))
打印输出当前文件上两层文件目录路径
import os print(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
18、请写出运行结果,并回答问题
tpl = (1, 2, 3, 4, 5) apl = (6, 7, 8, 9) print(tpl.__add__(apl))
问题:tpl 的值发生变化了吗?
运行结果如下:
(1, 2, 3, 4, 5, 6, 7, 8, 9)
答:元组是不可变的,它是生成新的对象
19、请写出运行结果,并回答问题
name = ('James', 'Wade', 'Kobe')
team = ['A', 'B', 'C']
tpl = {name: team}
print(tpl)
apl = {team: name}
print(apl)
问题:这段代码能运行完毕吗?为什么?它的运行结果是?
答:这段代码不能完整运行,它会在 apl 处抛出异常,因为字典的键只能是不可变对象,而 list 是可变的,所以不能作为字典的键。运行结果是:
{('James', 'Wade', 'Kobe'): ['A', 'B', 'C']}
TypeError
20、装饰器
请写出装饰器代码骨架
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
简述装饰器在 Python 中的作用:
在不改动原函数代码的情况下,为其增加新的功能。
21、多进程 多线程
多进程更稳定还是多线程更稳定?为什么?
多进程更稳定,它们是独立运行的,不会因为一个崩溃而影响其他进程。
多线程的致命缺点是什么?
因为所有线程共享进程的内存,所以任何一个线程挂掉都可能直接造成整个进程崩溃。
进程间通信有哪些方式?
共享变量、队列、管道。
二、Python 细节问题
1、 连接字符串用join还是+
当用操作符+连接字符串的时候,每执行一次+都会申请一块新的内存,然后复制上一个+操作的结果和本次操作的右操作符到这块内存空间,因此用+连接字符串的时候会涉及好几次内存申请和复制。而join在连接字符串的时候,会先计算需要多大的内存存放结果,然后一次性申请所需内存并将字符串复制过去,这是为什么join的性能优于+的原因。所以在连接字符串数组的时候,应考虑优先使用join。
2、Python 垃圾回收机制
参考 https://blog.csdn.net/xiongchengluo1129/article/details/80462651
Python中的垃圾回收是以引用计数为主,分代收集为辅。引用计数的缺陷是循环引用的问题。
在Python中,如果一个对象的引用数为0,Python虚拟机就会回收这个对象的内存。
引用计数法的原理是每个对象维护一个ob_refcnt,用来记录当前对象被引用的次数,也就是来追踪到底有多少引用指向了这个对象,当对象被创建、对象被引用、对象被传入函数、被存储在容器中等四种情况时,该对象的引用计数器 +1
对象被创建 a=14
对象被引用 b=a
对象被作为参数,传到函数中 func(a)
对象作为一个元素,存储在容器中 List={a,”a”,”b”,2}
与上述情况相对应,当发生对象别名被 del 销毁时、对象的引用被赋予新对象时、汉书执行完毕后、从容器中删除时等四种情况,该对象的引用计数器-1
当该对象的别名被显式销毁时 del a
当该对象的引别名被赋予新的对象, a=26
一个对象离开它的作用域,例如 func函数执行完毕时,函数里面的局部变量的引用计数器就会 -1(但是全局变量不会)。
将该元素从容器中删除时,或者容器被销毁时。
当指向该对象的内存的引用计数器为0的时候,该内存将会被Python虚拟机释放.
sys.getrefcount(a)可以查看 a 对象的引用计数,但是比正常计数大1,因为调用函数的时候传入a,这会让 a 的引用计数+1
引用计数的优点:
1、高效
2、运行期没有停顿:一旦没有引用,内存就直接释放了。不用像其他机制等到特定时机。实时性还带来一个好处:处理回收内存的时间分摊到了平时。
3、对象有确定的生命周期
4、易于实现
引用计数的缺点:
1、维护引用计数消耗资源,维护引用计数的次数和引用赋值成正比,而不像mark and sweep等基本与回收的内存数量有关。
2、无法解决循环引用的问题。A和B相互引用而再没有外部引用A与B中的任何一个,它们的引用计数都为1,但显然应该被回收。
# 循环引用示例 list1 = [] list2 = [] list1.append(list2) list2.append(list1)
为了解决这两个缺点 Python 还引入了另外的机制:标记清除和分代回收.
标记清除
『标记清除(Mark—Sweep)』算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。它分为两个阶段:第一阶段是标记阶段,GC会把所有的『活动对象』打上标记,第二阶段是把那些没有标记的对象『非活动对象』进行回收。那么GC又是如何判断哪些是活动对象哪些是非活动对象的呢?
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈、寄存器。
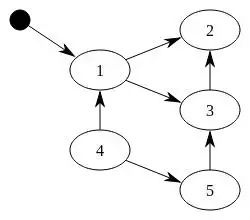
在上图中,我们把小黑圈视为全局变量,也就是把它作为root object,从小黑圈出发,对象1可直达,那么它将被标记,对象2、3可间接到达也会被标记,而4和5不可达,那么1、2、3就是活动对象,4和5是非活动对象会被GC回收。
标记清除算法作为Python的辅助垃圾收集技术主要处理的是一些容器对象,比如list、dict、tuple,instance等,因为对于字符串、数值对象是不可能造成循环引用问题。
Python使用一个双向链表将这些容器对象组织起来。不过,这种简单粗暴的标记清除算法也有明显的缺点:清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
分代回收
分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象。
GC 的逻辑
分配内存 -> 发现超过阈值了 -> 触发垃圾回收 -> 将所有可收集对象链表放到一起 -> 遍历, 计算有效引用计数 -> 分成 有效引用计数=0 和 有效引用计数 > 0 两个集合 -> 大于0的, 放入到更老一代 -> =0的, 执行回收 -> 回收遍历容器内的各个元素, 减掉对应元素引用计数(破掉循环引用) -> 执行-1的逻辑, 若发现对象引用计数=0, 触发内存回收 -> python底层内存管理机制回收内存
Python 中, 一个代就是一个链表, 所有属于同一”代”的内存块都链接在同一个链表中用来表示“代”的结构体是 gc_generation, 包括了当前代链表表头、对象数量上限、当前对象数量。
Python默认定义了三代对象集合,索引数越大,对象存活时间越长,新生成的对象会被加入第0代,前面_PyObject_GC_Malloc中省略的部分就是Python GC触发的时机。每新生成一个对象都会检查第0代有没有满,如果满了就开始着手进行垃圾回收。
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。同时,分代回收是建立在标记清除技术基础之上。
3、递归
Python 递归深度默认是多少?递归深度限制的原因是什么?
Python 递归深度可以用内置函数库中的 sys.getrecursionlimit() 查看。
因为无限递归会导致的 C 堆栈溢出和 Python 崩溃。
如果本文对你有帮助,别忘记给我个3连 ,点赞,转发,评论,
咱们下期见!答案获取方式:已赞 已评 已关~
学习更多知识与技巧,关注与私信博主(03)

最后
以上就是苹果春天最近收集整理的关于搞定这套Python爬虫面试题,面试轻轻松松!的全部内容,更多相关搞定这套Python爬虫面试题内容请搜索靠谱客的其他文章。








发表评论 取消回复