掘金原文:https://juejin.cn/post/6966127447527915551
背景
现象
- 业务基于ElasticSearch为产品提供了全文搜索能力,需要及时将DB变更数据异构到ES,供业务查询,即DTS(Database To ES);
- 由于数据变更入口较多,使用Canal原生客户端去监听数据binlog变更,并将数据顺序投递到MQ,基础搜索服务消费端消费,过滤,数据组装后,上报到ES,即DB->Canal->MQ->Comsumer->ES;
- 目前整体DB->ES数据同步较慢,处理速度QPS为60左右,在遇到洗数据/导入资源等大量数据变更时,往往造成大量Canal-MQ(顺序)消息堆积,业务数据同步时延;
- 一些对数据可见性敏感的场景 (比如个人创建习题后需马上可见),由于多条件查询走DB较慢,目前实现方案走的ES,大延迟对会对此类场景造成较大业务受损,不可接受;
- 当前通过规避高峰期数据量清洗去减少上述影响,对日常洗数据造成不便,同时隐含造成线上业务用户体验差;
现数据量-同步延时对比
| 数据变更量 | DTS数据同步 |
|---|---|
| 60 < x < 600 | 1s~10s |
| 3600<x<10800 | 1min~3min |
| 10800<x | >3min |
问题分析
现实现方案
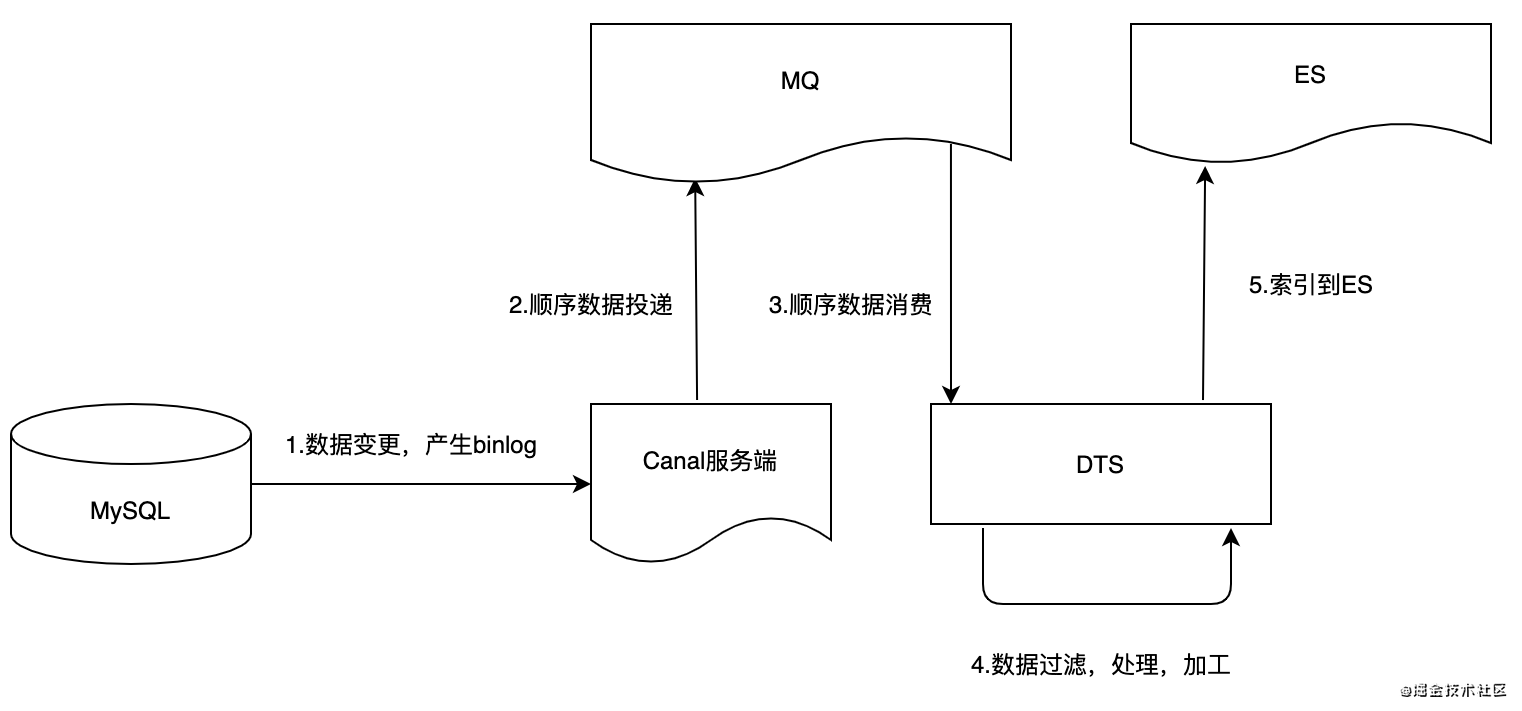
耗时分析
1.DB→ES上报主要通过MQ削峰解耦,当DB数据大量变更时容易造成MQ消息堆积;无非就以下三种情况:
- 生产者生产消息过快:
- 消费者消费消息过慢;
- 两种现象同时存在;
2.DB->ES→可被检索到,主要有几个同步耗时点:(参照上图,红色字体为严重耗时点) - 步骤1:binlog日志发送到Canal造成的延时(参考MySQL主从同步延时),正常情况下可忽略;(上图)
- 步骤2:Canal发送变更顺序消息到MQ:
- 目前按全局顺序消息配置;(Canal支持按表级别配置),在进行大量数据变更时,超过100万,约有20min上报延迟;
- 即:将所有变更数据只发送到broker的一个queue中(
非常不利于消费端顺序消费); - Canal不支持按主键id进行顺序发送;
- 上报QPS相对可接受,没有业务逻辑,直接转发到MQ;
- 步骤3:DTS服务批量拉取消息,并顺序消费:
- 从MQ队列中顺序拉取消息,
由于步骤2的全局顺序消息,导致消费端顺序消费实际只能加锁拉取一个队列,单线程处理,扩充实例也无法提升消费速度; - 获取消息后,步骤5按表,DDL操作类型实现不同的上报ES动作;
- 当上报成功后,进行MQ消息ack,返回CONSUME_SUCCESS确认Canal消费位点;
- 当上报失败时,进行MQ消息rollback, 返回RECONSUME_LATER,进行失败重试;
- 步骤4,5:
同步,顺序上报逻辑,中间还夹杂着业务数据查询和过滤;- ES批量bulk操作,一次http请求;
- ES将数据写入内存buffer,Refresh后可见,1s内, ES特性使然,暂无法(无需)处理;
目前Canal-MQ消息堆积主要是步骤3导致的,本次优化先从该点入手;
MQ顺序消费优化
- 目前Canal按全局顺序消息发送(堆积瓶颈仍在消费端):
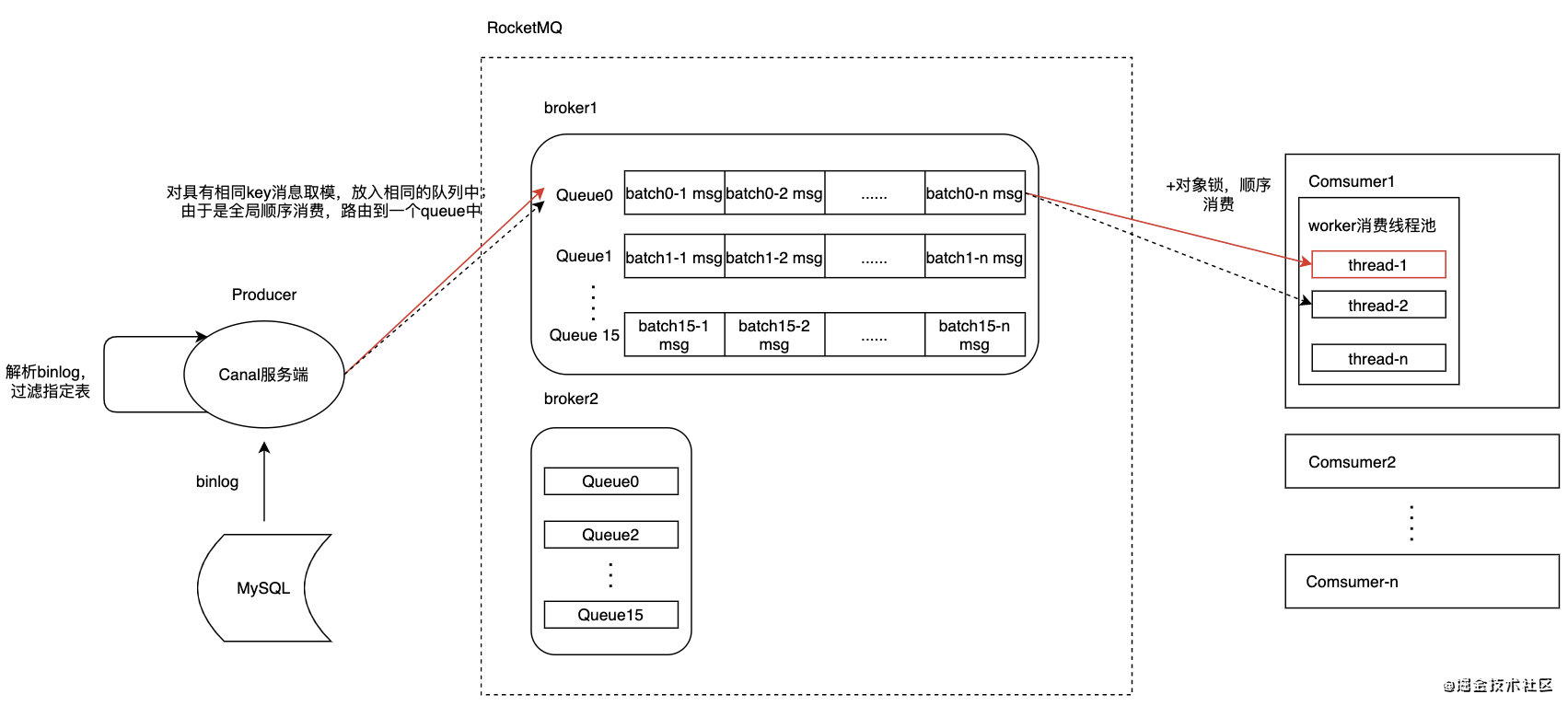
- 即使是单Comsumer多worker线程模型,
仍然只能同时只有一个上报线程在工作,这对于IO密集型任务是非常不利的; - 现象:数据上报和消费全都挤在一条队列,对于存储和多实例消费均不利;
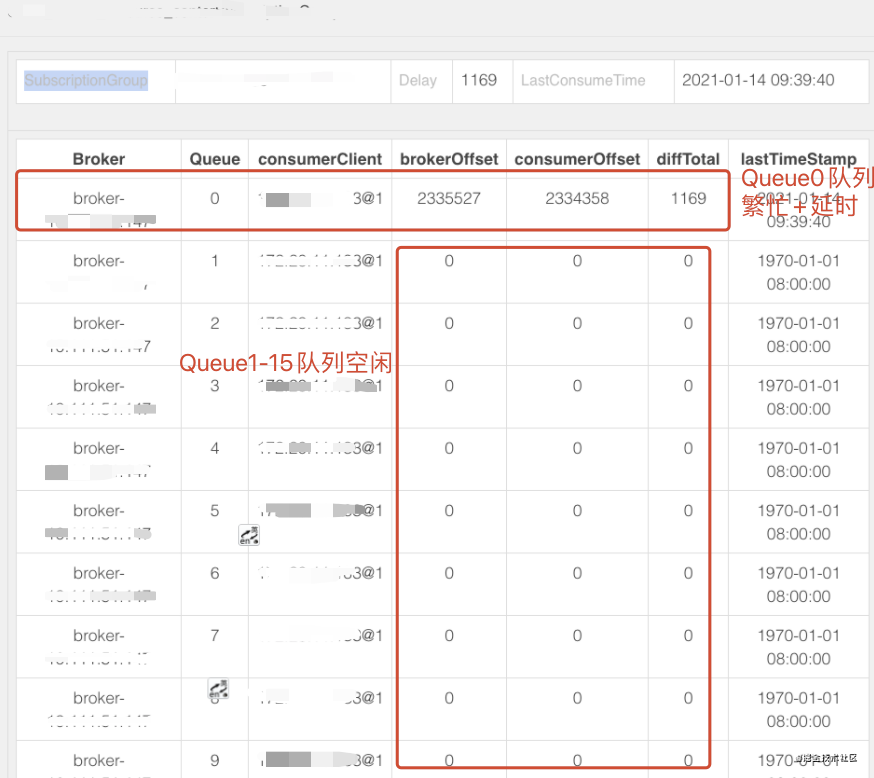
弊端
- 由于要保持DB到ES异构的数据强一致性,按照产生的binlog顺序处理后在重放到ES,并做了同步消息确认和回滚来保障强一致性,目前单线程方式处理性能极低;
- 实际业务对于同一条数据进行并发操作的概率是极低的,需要进一步细化顺序同步数据粒度;
方案设计
目标
- 期望按最小粒度(表+业务uid)保证消息顺序上报,提升db到es的上报qps;
队列方案
通过同一条队列的FIFO特性保证;
1.直连Canal服务端
- 搜索服务直连Canal服务端,拉取变更消息后按表+业务id顺序路由上报:
- 即从数据上报方式优化,同时自然而然提升消费端消费速度;
服务结构
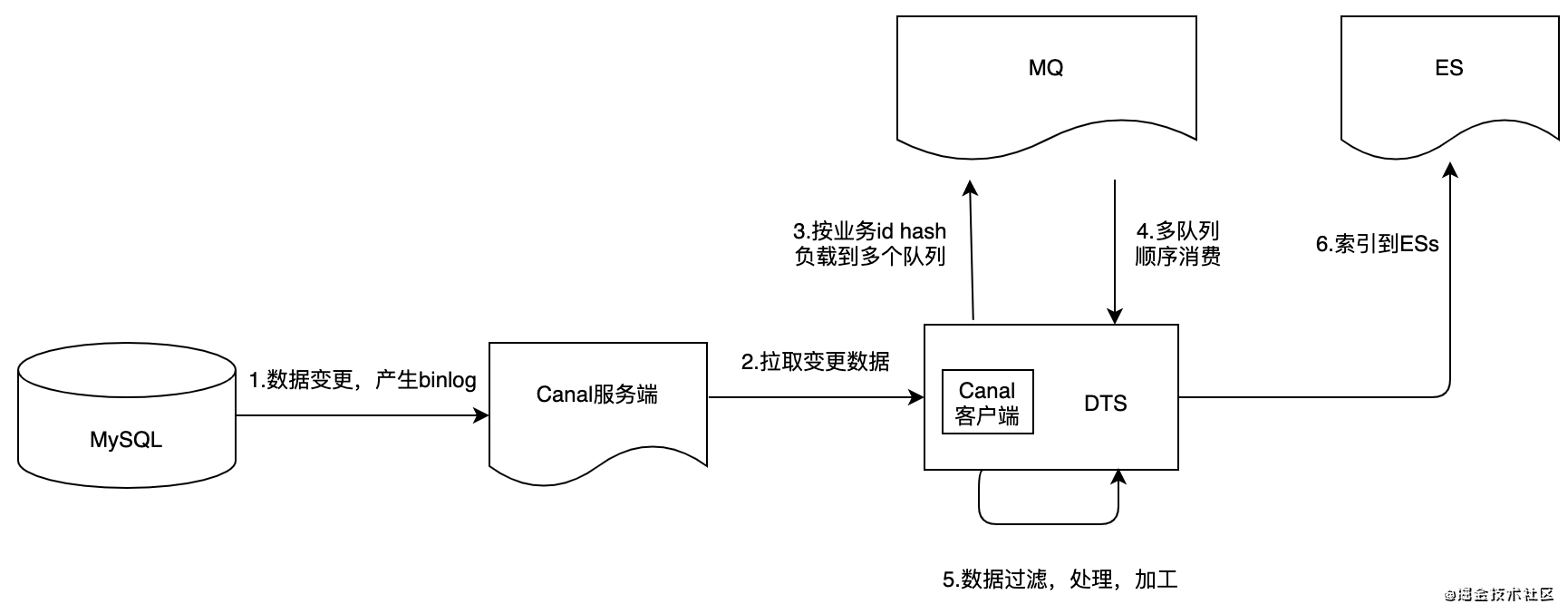
优点
- 可以自定义发送MQ路由顺序规则(按表+id);(目前Canal原生客户端不支持)
- 数据上报支持多实例消费上报,可通过扩容服务实例提升消费速度;
缺点
- 替换官方Canal发送MQ客户端,有一定开发量;
2.消费端进行消息二次路由到MQ,按表+业务id;
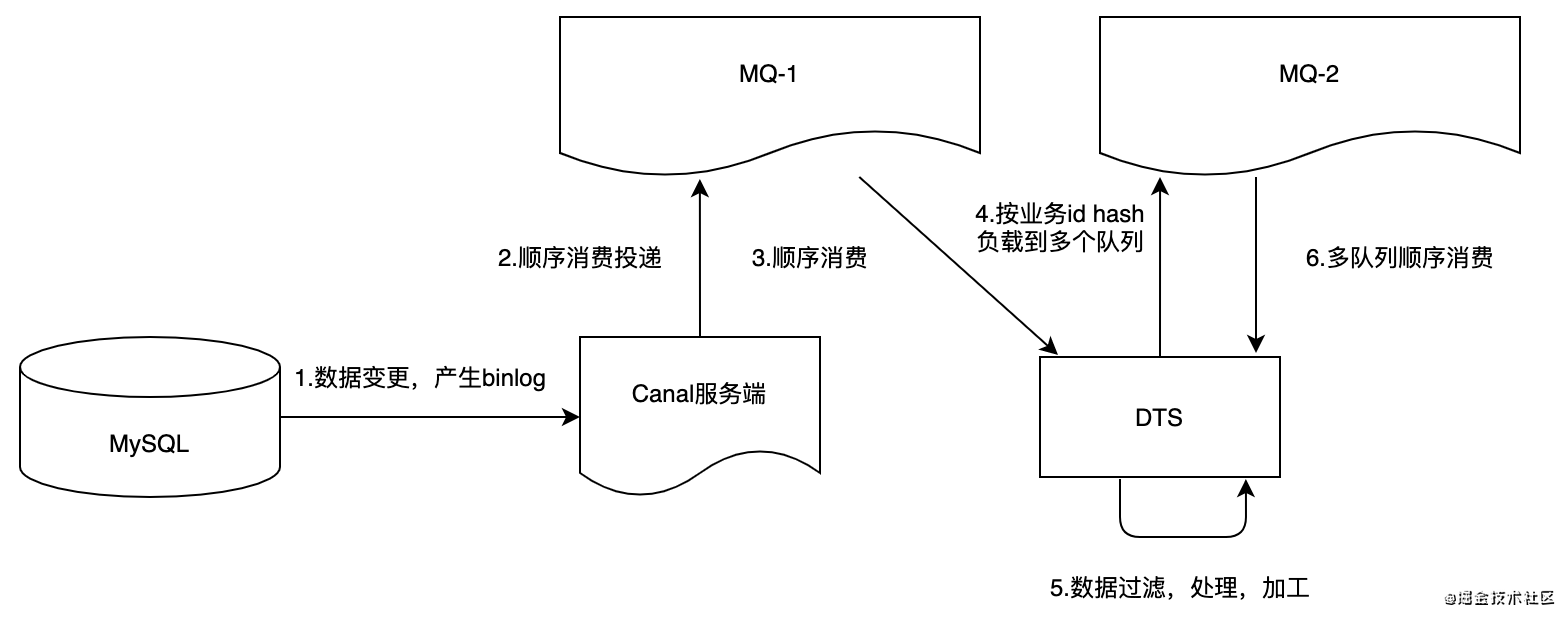
优点
- 优点同上;
- 并且实现简单,只需要增加3步骤,对原有代码侵入也较小;
缺点
- 经过两次MQ,存在网络消耗和资源存储浪费;
分布式锁方案
通过Redis锁保证同一业务uid执行顺序
- 本质上顺序消费只需要保证是同一条业务数据的顺序性,通过分布式锁同步来保证;
- 即顺序消费的确认的时间点由消费上报成功转移到获取Redis锁成功,而业务层对同一数据的并发/高频(1s内)处理是极少的,即获取锁等待的概率实际也很低;
服务结构
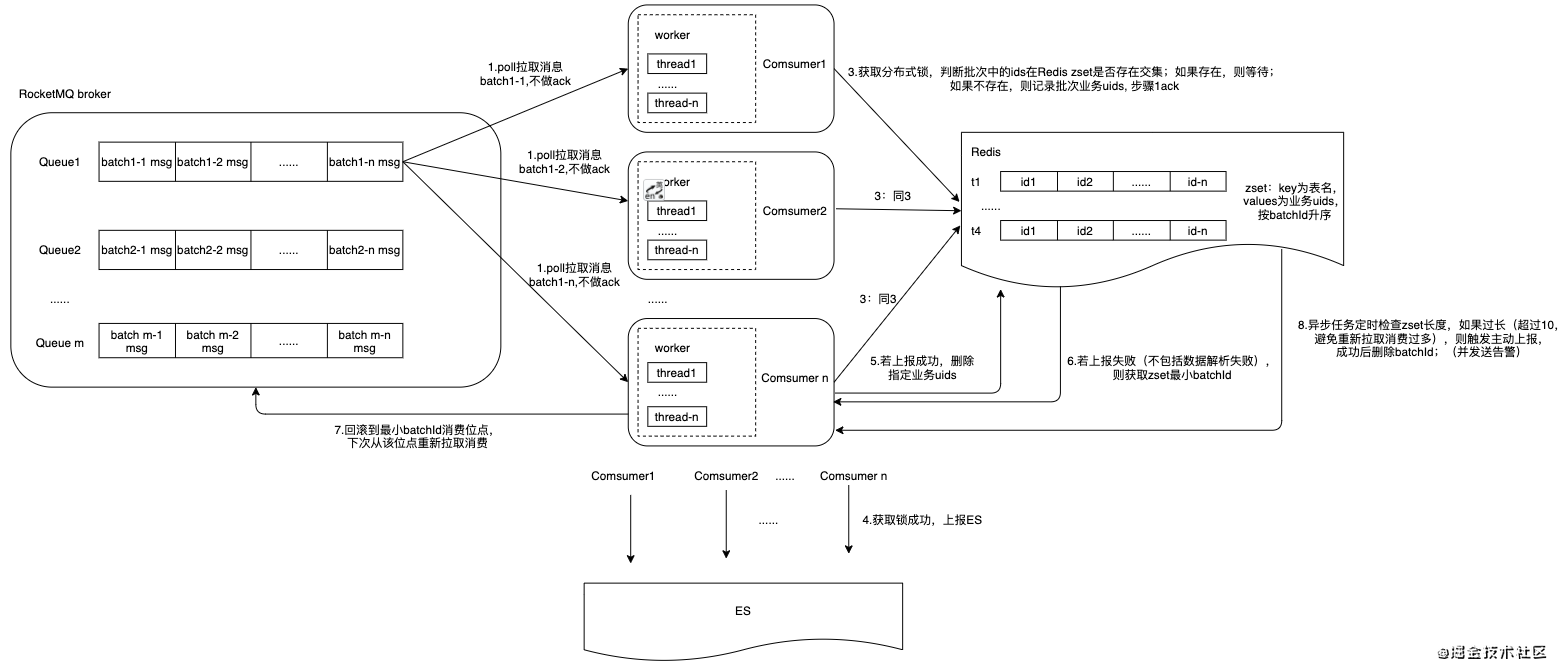
优点
- 能够实现预期按id顺序同步;
- 通过提升单实例的消费速度优化;
缺点
- 整体改动较大,拉取数据方式(ack方式),和回滚最小batchId逻辑;
- 引入Redis组件,整体同步链路变长,可靠性变差,复杂度变高;
- 已经引入了队列来保障顺序处理,不建议通过锁保障;
因果矩阵分析
| 方案 | 开发成本4 | 维护成本4 | 同步速率8 | 数据一致性保障 | 总分 |
|---|---|---|---|---|---|
| 方案1 | 3(替换canal原生发送MQ客户端) | 4(后续无需改动) | 7(自定义路由,顺序均匀hash到队列) | 8(通过原本的消费位点ack方式保障) | 22 |
| 方案2 | 4(只需要多加一条MQ做二次路由) | 2(多了一次MQ存储和发送) | 5(二次MQ发送) | 8(与原本一样) | 19 |
| 方案3 | 2(改动范围大) | 2(引入Redis组件) | 6(通过提升单实例的消费速度,原单一队列顺序消费没有改善) | 6(异常处理较为复杂) | 16 |
进一步优化
在方案1基础上进行优化
问题分析
- 在进行大量数据更新时,其实很多数据为公共资源数据,及时性更新对业务并不重要;
- 私有数据(公共/区域)由于为个人操作所感知(创建/查询/删除/更新等),需要及时感知变更,而这些变更却被公共数据清洗所阻塞,不合理;
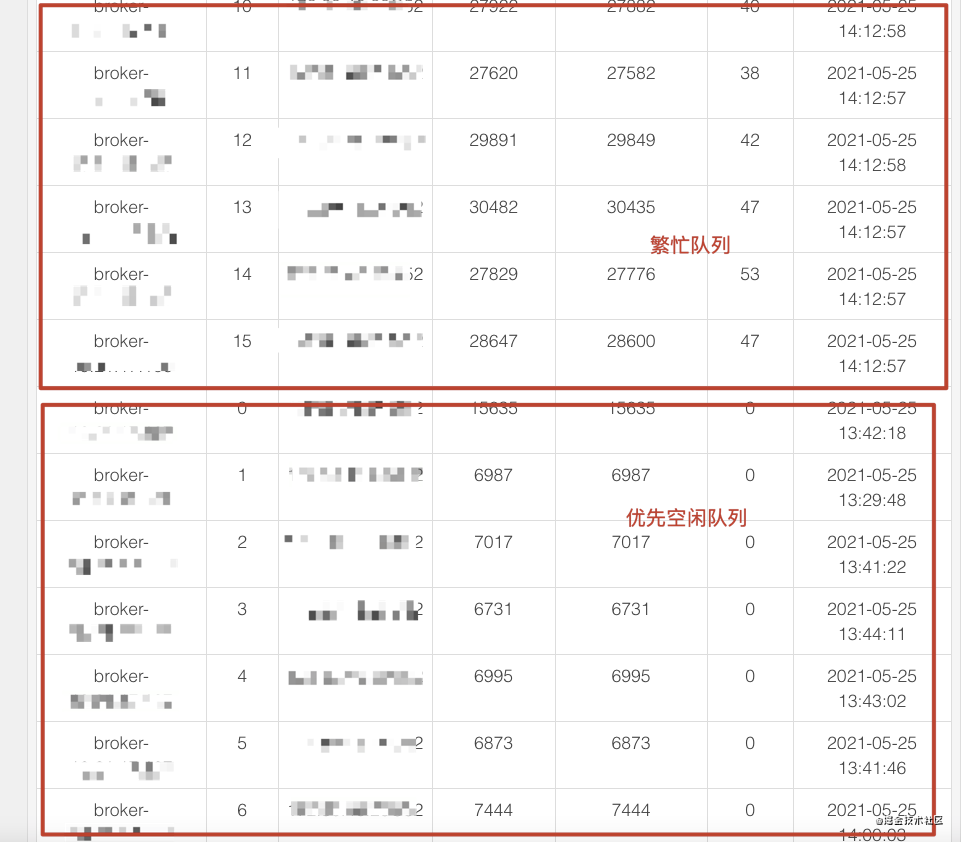
- 将MQ队列划分一下优先级,分为繁忙队列和空闲优先队列,对于变更优先级高的数据,走后者,减少排队阻塞导致的时延;
实现
- 通过Appcode区分优先级高的同步数据;(当前根据业务场景,也可通过参数/策略区分)
- 分别将数据投递到不同的队列中;
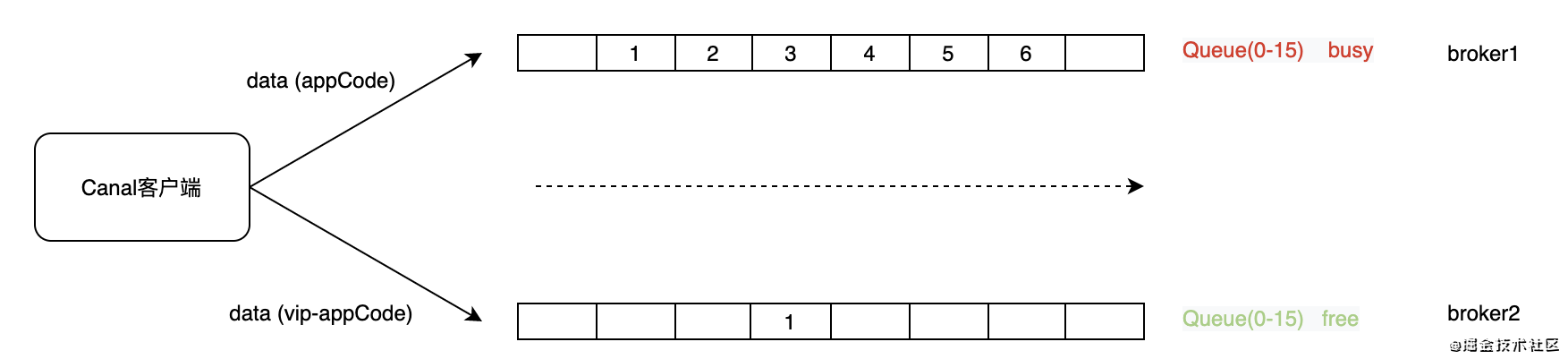
代码实现
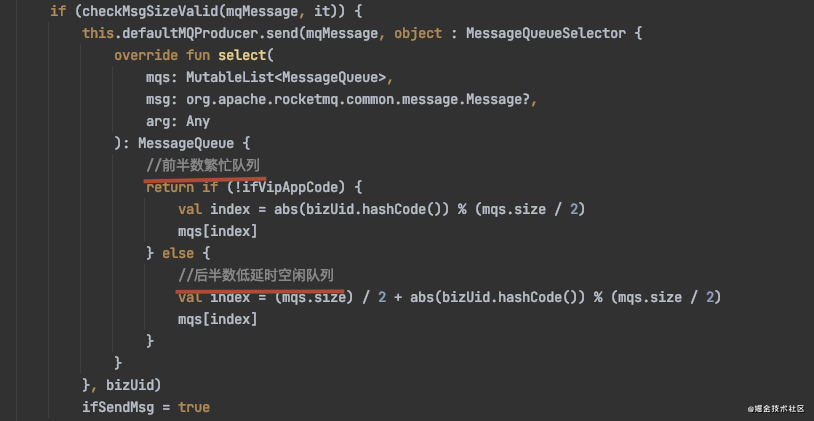
效果:(不同队列优先级同步)
同步瓶颈
- 由于canal服端只允许同时只有一个客户端连接,可通过消费端扩容,满足生产实际使用;
- 进一步优化方向思考:优化Canal客户端端到MQ的IO,通过服务内存队列入队直接做ack,服务线程池hook注册确保异常情况下最大努力把消息投递到MQ;
结论
- 方案1,2主要从消息生产端来优化(顺便优化了消费端的消费方式),即通过更小粒度路由方式发送到同一个queue中(全局顺序→ 业务uid顺序),消费端可以通过扩容来提升消费速度,并针对业务场景去做信息的优先级同步;
- 方案3是通过锁来保证同一uid顺序消费,即相同uid的数据保证顺序性,实现较为复杂,提升单实例下的消费速度,在有队列顺序保证的条件下,暂不建议引入;
综上,建议选择方案1;
最后
以上就是伶俐老鼠最近收集整理的关于DTS数据上报优化背景问题分析方案设计的全部内容,更多相关DTS数据上报优化背景问题分析方案设计内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复