《当年,我们是怎么平滑上云的?》介绍了上云的背景,以及三个重要结论:
(1)单机房架构的核心是“全连接”;
(2)机房迁移方案的设计目标是:平滑迁移,不停服务;可以分批迁移;随时可以回滚;
(3)想要平滑的实施机房迁移,临时性的多机房架构不可避免;
《多机房多活架构,究竟怎么玩?》说明了在机房迁移的过程中,一定有一个“多机房多活”的中间状态:
(1)理想多机房多活架构,是纯粹的“同机房连接”,仅有异步数据同步会跨机房;
(2)理想多机房多活架构,会有较严重数据一致性问题,仅适用于具备数据聚集效应的业务场景,例如:滴滴,快狗打车;
(3)伪多机房多活架构,思路是“最小化跨机房连接”,机房区分主次,落地性强,对原有架构冲击较小,强烈推荐;
多机房多活,只是平滑上云的一个中间状态,那上云的步骤究竟是怎么样的呢?
【5】核心问题五,如何分批平滑上云?
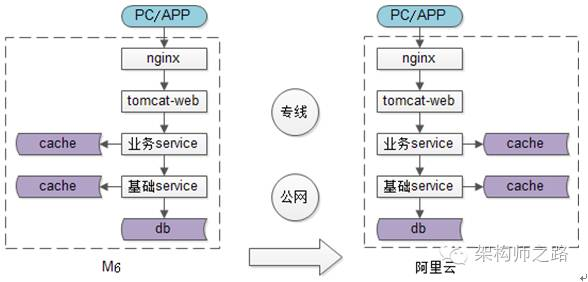
如上图,系统分层架构包含:web,业务服务,基础服务,缓存,数据库,它们都需要进行迁移。
大的方向,有两种方案:
(1)自底向上的迁移方案,从数据库开始迁移;
(2)自顶向下的迁移方案,从web开始迁移;
这两种方案我分别在58同城和58到家实践过,都是平滑的,蚂蚁搬家式的,随时可回滚,对业务无任何影响的,本文重点介绍“自顶向下”的方案。
画外音:14-15年58同城“逐日”项目,2000台物理机平滑迁移至天津机房,我是当时项目总架构师。
一、站点与服务迁移:无状态,迁移容易
站点和服务无状态,迁移起来并不困难。
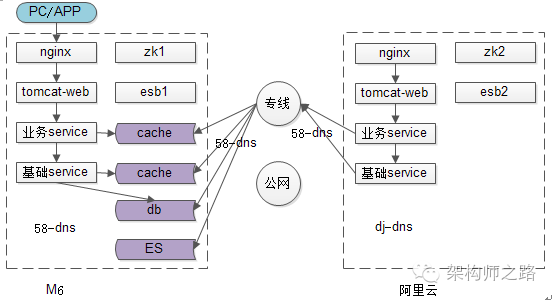
步骤一,前置条件:
(1)新机房准备就绪;
(2)专线准备就绪;
步骤二,在新机房搭建好待迁移的子业务,部署好web站点,业务服务,基础服务,做好充分的测试。
这里要重点说明的是:
(1)垂直拆分迁移,每次迁移的范围不要太大,划分好子业务和子系统;
(2)缓存和数据库还未迁移,存在跨机房连接;
(3)新机房的配置文件注意“同连”,不要跨机房调用业务服务与基础服务;
画外音,只要不切流量:
(1)依然老机房提供服务;
(2)新机房随便玩;
步骤三,灰度切流量,将被迁移的子业务切5%的流量到新机房,观察新机房的站点与服务是否异常。如果没有问题,再10%,20%,50%,100%的逐步放量,直至某个子业务迁移完成。
第一个子业务的站点和服务迁移完之后,第二个子业务、第三个子业务,蚂蚁继续搬家,直至所有的业务把站点和服务都全流量的迁移到新机房。
如何应对异常?
在迁移过程中,任何一个子业务,任何时间发生异常,可以将流量切回旧机房。旧机房的站点、服务、配置都没有改动,依然能提供服务。
这是一个非常稳的迁移方案。
二、缓存迁移:有状态,但数据可重建
站点和服务迁移完之后,接下来再迁缓存。
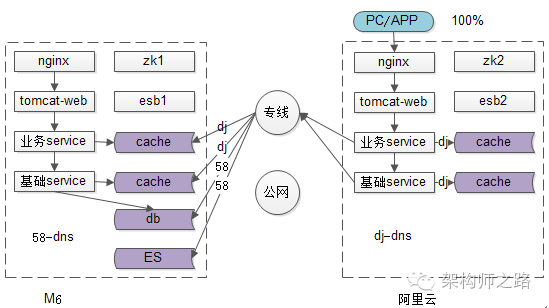
经过第一步的迁移,如上图:
(1)所有的入口流量都已经迁到了新的机房;
(2)缓存和数据库,仍然使用旧机房;
画外音:旧机房的站点和服务不能停,只要旧机房不停,就保留了切回流量回滚的可能性。
步骤四,在新机房搭建好缓存,缓存的规模和体量与旧机房一样。
步骤五,按照子业务垂直逐步切换使用新机房的缓存,切换细节为:
(1)运维做一个缓存内网DNS的切换(内网域名不变,IP切到新机房);
(2)杀掉原有缓存连接,业务线不需要做任何修改,只需要配合观察服务;
(3)缓存连接池会自动重连,重连会自动连接新机房的缓存;
bingo,一个子业务缓存迁移完毕。
这里要注意几个点:
(1)如果没有使用内网域名,而是采用IP直连缓存,则需要业务层配合,换新机房IP重启;
画外音:说过无数次,一定要使用内网域名。
(2)缓存迁移时间,尽量选在流量低峰期,新缓存是空数据,如果选在流量高峰期,短时间内可能会有大量请求透传到数据库上;
(3)对于同一个服务,缓存的切换时瞬时的,不会同时使用新旧机房的缓存;
画外音:否则容易出现一致性问题。
缓存的迁移也是按照子业务,垂直拆分,蚂蚁搬家式迁移的。整个迁移过程除了运维操作切内网域名,研发和测试都只是配合观察服务,风险非常低。
缓存允许cache miss,不用转移旧缓存内的数据,所以迁移方案比较简单。
三、数据库迁移:有状态,数据也要迁移
站点层,服务层,缓存层都迁移完之后,最后是数据库的迁移。
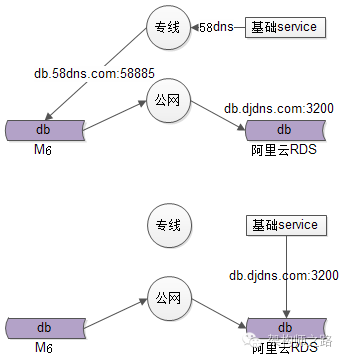
在迁移数据库之前,服务通过专线跨机房连数据库。
如何进行数据库迁移呢?
步骤六,先在新机房搭建新的数据库。
画外音:自建机房,需要自己搭建新的MySQL实例;到家直接使用阿里云的RDS。
步骤七,数据同步。自建机房可以使用数据库MM/MS架构同步数据,阿里云可以使用DTS同步数据。
画外音:DTS同步有一个大坑,只能通过公网同步非RDS的数据,至少在16年是这样,不知道现在产品升级了没有。
数据库同步完之后,如何进行数据源切换呢?
能不能像缓存的迁移一样,运维修改一个数据库内网DNS指向,然后切断数据库连接,让服务重连新的数据库呢?这样的话,业务服务不需要改动,也不需要重启。
这个方式看上去很不错,但是:
(1)一定得保证数据库同步完成,才能切流量,但数据同步总是有迟延的,旧机房一直在不停的写如数据,何时才算同步完成?
(2)只有域名和端口不发生变化,才能不修改配置完成切换,但如果域名和端口(主要是端口)发生变化,是做不到不修改配置和重启的。举个例子,假设原有数据库实例端口用了5858,而阿里云要求你使用3200,就必须改端口重启。
步骤八,最终的方案是,DBA在旧机房的数据库设置一个ReadOnly,停止数据的写入,在秒级别,RDS同步完成之后,服务修改数据库端口,重启连接新机房的数据库,完成数据层的切换。
这个过程中,为了保证数据的一致性,会损失秒级别的写入可用性。
经过上述站点、服务、缓存、数据库的迁移,平滑的蚂蚁搬家式上云目标就这么完成啦。
画外音:几百台机器,几千个集群,耗时一个季度。
自顶向下的机房迁移方案总结
一、先迁移站点层、业务服务层和基础服务层
(1)准备新机房与专线;
(2)搭建集群,充分测试,子业务垂直拆分迁移;
(3)灰度切流量;
二、缓存层迁移
(4)搭建新缓存;
(5)运维修改缓存内网DNS,切断旧缓存连接,重连新缓存(这一步很骚),切流量;
三、数据库迁移
(6)搭建新数据库;
(7)同步数据;
(8)旧库ReadOnly,同步完成后(秒级),服务指向新库,改配置重启,切流量;
以上8大步骤,整个过程分批迁移,一个子业务一个子业务的迁移,一块缓存一块缓存的迁移,一个数据库一个数据库的迁移,任何步骤出现问题都可以回滚的,整个过程不停服务。
思路比结论重要。

架构师之路-分享技术思路
相关文章:
《当年,我们是怎么平滑上云的?》
《多机房多活架构,究竟怎么玩?》
讨论:
贵司是如何上云的,步骤如何?
画外音:长文阅读量太低了,春节不写技术了。
最后
以上就是受伤鸡翅最近收集整理的关于上云不停服,自顶向下的平滑机房迁移方案!!!的全部内容,更多相关上云不停服,自顶向下内容请搜索靠谱客的其他文章。








发表评论 取消回复